Incremental knowledge base construction using DeepDive Shin et al., VLDB 2015
When I think about the most important CS foundations for the computer systems we build today and will build over the next decade, I think about
- Distributed systems
- Database systems / data stores (dealing with data at rest)
- Stream processing (dealing with data in motion)
- Machine learning (extracting information from data)
(What did I miss? Anything you’d add to the list?)
Regular readers will no doubt have noticed that these are the subject areas I most often cover on The Morning Paper. I’ve chosen today’s paper as representative of a large body of work at Stanford on a system called DeepDive. DeepDive sits at a very interesting intersection of the above topics, and its goal is to build a knowledge base – stored in a relational database – from information in large volumes of semi-structured and unstructured data. Such data is sometimes called dark data, and creating a knowledge base from it is the task of knowledge base construction (KBC).
The ultimate goal of KBC is to obtain high-quality structured data from unstructured information. These databases are richly structured with tens of different entity types in complex relationships… they can ingest massive numbers of documents – far outstripping the document counts of even well-funded human curation efforts.
The most important measures of KBC systems are precision (how often a claimed tuple is correct), and recall (of all the possible tuples to extract, how many are actually extracted). DeepDive itself has been used to build dozens of high-quality KBC systems (see descriptions of some of them at http://deepdive.stanford.edu/showcase/apps), and won KBC competitions.
In all cases, we have seen the process of developing KBC systems is iterative; quality requirements change, new data sources arrive, and new concepts are needed in the application. This led us to develop techniques to make the entire pipeline incremental in the face of changes both to the data and to the DeepDive program. Our primary technical contributions are to make the grounding and inference phases more incremental.
The incremental techniques improved system performance by two-orders of magnitude in five real KBC scenarios, while keeping the quality high enough to aid in the development process. Before we can understand those techniques, we need to cover some background on the overall KBC process itself.
KBC, the big picture
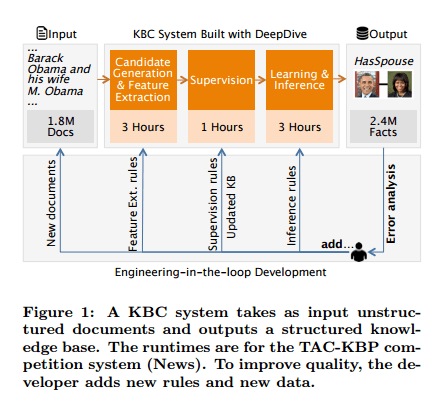
The process begins with a corpus of documents, and ends with a relational database containing facts extracted from those documents. KBC systems are typically developed incrementally with developers reviewing the quality of fact extraction (precision and recall) and adding new rules and data as needed. The resulting database will contain entities, relations, mentions, and relation mentions.
- An entity is a real-world person, place, or thing
- A relation associates two or more entities
- A mention is a span of text that refers to an entity or relationship
- A relation mention is a phrase that connects two mentions participating in a relation (e.g. London is the capital of England).
Ingestion and extraction of candidate mappings and features
As documents are ingested they are split into sentences. Each sentence is marked up using standard NLP pre-processing tools, including HTML stripping, part-of-speech tagging, and linguistic parsing, and then stored as a row in the database.
Once the document sentences are loaded and pre-processed, DeepDive looks for candidate mappings and features.
Candidate mappings are extracted using SQL queries. These extract possible mentions, relations, and entities. At this stage we go for high recall (get anything that might be interesting) and don’t worry too much about precision. For example, if we’re building a knowledge base including information about married partners, than we might extract a MarriedCandidate mapping every time two people are mentioned in the same sentence.
Features are supplementary information that the subsequent learning phases can use to learn which of the candidate mappings should indeed be considered true relations with high probability. In the marriage example, we might extract as a feature the phrase that appears between the two mentions. The system will learn a weight indicating how much confidence to place in a given phrase as an indication of a true relation.

In general, phrase could be an arbitrary UDF that operates in a per-tuple fashion. This allows DeepDive to support common examples of features such as “bag-of-words” to context-aware NLP features, to highly domain-specific dictionaries and ontologies. In addition to specifying sets of classifiers, DeepDive inherits Markov Logic’s ability to specify rich correlations between entities via weighted rules.
Supervised learning phase
There are two techniques for providing labelled training data. One is simply to provide true or false labels for evidence relations. The other is a technique called distant supervision. Distant supervision uses a supplementary dataset of facts to create larger sets of labelled data. Continuing the marriage example, suppose we have an external database of trusted facts indicating spouse relationships, and we choose a particular relationship P1 is married to P2. We then label as true every candidate marriage mapping the system has extracted that mentions P1 and P2. This will of course label as true indications of marriage some phrases that really aren’t, for example, “Crypto Bob (P1) exchanged messages with Crypto Alice (P2)”.
At first blush, this rule seems incorrect. However, it generates noisy, imperfect examples of sentences that indicate two people are married. Machine learning techniques are able to exploit redundancy to cope with the noise and learn the relevant phrases.
Inference and learning using a factor graph
Now the fun begins…
A DeepDive program defines a standard structure called a factor graph through inference rules specified by the developer. From the DeepDive website:
A rule expresses concepts like “If John smokes then he is likely to have cancer” and, in other words, describes the factor function of a factor and which variables are connected to this factor. Each rule has a weight (either computed by DeepDive or assigned by the user), which represents the confidence in the correctness of the rule. If a rule has a high positive weight, then the variables appearing in the rule are likely to take on values that would make the rule evaluate to true.
The factor graph contains two types of nodes: variables and factors. Variables may be either evidence variables (we know their true value, as a result of the supervision phase) or query variables whose value we want to predict. Factors define the relationships between the variables in the graph, “Each factor can be connected to many variables and comes with a factor function to define the relationship between these variables.”
Inference now takes place over the factor graph, using Gibbs sampling. Again, the website explains this well:
Exact inference is an intractable problem on factor graphs, but a commonly used method in this domain is Gibbs sampling. The process starts from a random possible world and iterates over each variable v, updating its value by taking into account the factor functions of the factors that v is connected to and the values of the variables connected to those factors (this is known as the Markov blanket of v). After enough iterations over the random variables, we can compute the number of iterations during which each variable had a specific value and use the ratio between this quantity and the total number of iterations as an estimate of the probability of the variable taking that value.
Thus DeepDive uses joint inference, determining the values of all events at the same time. This allows events to influence each other if they are directly or indirectly connected through influence rules.
Closing the loop
At the end of the learning and inference phrase, DeepDive has computed a marginal probability p for each candidate fact. Typically a user then selects facts with high confidence (e.g. p > 0.95) to produce the final knowledge base. It’s unlikely the system will be perfect first time around:
Typically, the user needs to inspect errors and repeat, a process that we call error analysis. Error analysis is the process of understanding the most common mistakes (incorrect extractions, too-specific features, candidate mistakes, etc.) and deciding how to correct them. To facilitate error analysis, users write standard SQL queries.
Incremental development
I only have space to cover this very briefly, see §3 in the paper for full details. DeepDive supports incremental grounding and_incremental inference_. Incremental grounding is the process of updating an existing factor graph based on new information, and incremental inference is the process of updating the learned probabilities given the change in the graph.
For incremental grounding, DeepDive uses standard incremental view maintenance techniques from the database community. Specifically, it uses the DRED algorithm of Gupta et al. (1993).
For incremental inference two different approaches are implemented – neither dominates the other and so the system chooses which to use at runtime using a simple set of rules based on the kinds of changes made to the graph.
- The sampling approach stores a set of possible worlds sampled from the original distribution, rather than storing all possible worlds, and then performs inference over these samples. “We use a (standard) Metropolis-Hastings scheme to ensure convergence to the updated distribution.”
- The variational approach stores a factor graph with fewer factors that approximates the original distribution. On the smaller graph, running inference and learning is often faster.

(What did I miss? Anything you’d add to the list?) – Cryptography
That’s a good one! Masses of interest in eg practical technologies for computing over encrypted data, managing privacy etc..
`than we might extract a MarriedCandidate mapping`, should it be `then`
We are a bunch of volunteers and starting a new scheme in our community.
Your website offered us with valuable information to work on. You’ve done a formidable job and our entire group will be thankful to you.
Given the large stack of software and the complexity of already existing systems, I’d consider adding more CS research and tooling to reduce and/or eliminate faults and increase correctness. Call it Quality assurance if you will, but there is stuff happening that’s about the most impressive applied CS done in many years. The DARPA HACMS challenge has produced some results well worth reading up on, especially the reduction in cost to produce formally verified avionics grade software shows real promise. You’ve already covered a lot of them including ‘Lineage Driven Fault Injection’, ‘Causal Profiling’ and several others. I’m pretty sure there’s a pattern here: None of the higher level stuff, and the associated complexity that comes with it, is within reach without the lower level stuff actually performing extremely well. I for one expect this to become increasingly hard in the coming 5-10 years, especially without tools. Systems are already distributed, but the tooling is struggling to keeping up. Currently we are forced to use old tools not very well suited to the new tasks at hand. Most tools target local problems, few tackle distributed problems.
And thanks for The Morning Paper. I’ve read every single entry and the papers behind them.
Wow – as far as I know you’re the only reader to have read every single edition! Serious dedication, and thanks for the comments and pointers.
Regards, Adrian.
Well, not really. I’ll have to admit I kind of cheated, because I’d already read way more than half the papers before a clever person pointed me at your blog (Thanks again Tobias F). Seems like we’ve been on a similar quest to understand what’s driving the changes we see, and what comes next. There is a substantial overlap in terms of articles we’ve both picked up, I guess for pretty much the same reasons.
I admire your ability to bring out the gist of the papers, as it makes research far more accessible to a wider audience. I can only find the gist, not ‘write home about it’ like you do.
With years of training, I’ve fallen into a pattern where I average ~180 pages of research papers every day. It’s not like you have to read all of it. The gist of the average paper is typically less than a few percent of the text (and figures). It’s when you find the non-average papers, the ones that send thrills down your spine and force you to really think that make all of it worthwhile. I’ve been looking for tools to help with finding the right stuff. Have you found any? I’ve tried Quid and a few others, but always end up tracking various news feeds looking for the ones that stick out. I’m pretty sure I’m missing some good ones.
I tend to focus more on the lower level stuff, including hardware and the lowest layers of software, as it often has greater impact on the rest of the stack and pushes the limits of what is possible. I’m currently trying to find out as much as possible about what happens when 3D Xpoint and Hybrid Memory Cubes become commodity. Intel+Altera and the X86 meets high end FPGA:s. Tools to convert software to run on FPGA:s. Barefoot networks (based on research out of Stanford) with 6.5 terabits/s software defined networking. The p4 network programming language (http://p4.org/) that comes with barefoot silicon and the research behind it.
These things combined are likely to have more trivial impact on how computing, data processing and machine learning is done, and blurs the line between ‘data at rest’ and ‘stream processing’.
It was supposed to be “These things combined are likely to have more THAN trivial impact on how computing, data processing and machine learning is done, and blurs the line between ‘data at rest’ and ‘stream processing’.”