Acing the IOC game: toward automatic discovery and analysis of open-source cyber threat intelligence Liao et al. CCS 2016
Last week we looked at a number of newly reported attack mechanisms covering a broad spectrum of areas including OAuth, manufacturing, automotive, and mobile PIN attacks. For some balance, today’s paper choice looks at something to help the defenders! iACE analyses security blogs posting Indicators of Compromise (IOCs), and extracts OpenIOC schema-based reports from them, which can then be fed automatically into detection and prevention systems.
I find this paper interesting on three levels:
- There’s iACE itself, the glimpse it gives us into the world of Cyber Threat Intelligence (CTI), and how it works.
- Even if security isn’t your thing, the general approach of extracting useful information from large volumes of blog postings or other web pages containing semi-structured information mixed with informal prose has lots of applications. There many challenges both small and large to be overcome along the way, and this paper does a good job of describing approaches to many of them.
- After using iACE to analyse over 71,000 articles and extract over 900K IOCs, the authors were able to further analyse what they had discovered to give new insights into attacks over the last 13 years.
Setting the scene
Given its importance, CTI has been aggressively collected and increasingly exchanged across organizations, often in the form of Indicators of Compromise (IOC), which are forensic artifacts of an intrusion such as virus signatures, IPs/domains of botnets, MD5 hashes of attack files, etc. Once collected, these IOCs can be automatically transformed and fed into various defense mechanisms (e.g., intrusion detection systems) when they are formatted in accordance with a threat information sharing standard, such as OpenIOC, that enables characterization of sophisticated attacks like drive-by downloads. The challenge, however, comes from the effective gathering of such information, which entails significant burdens for timely analyzing a large amount of data.
There are many blogs and forums where informal descriptions of IoCs are posted. Converting these into a standard IOC format has traditionally been done manually, but the volume of attacks and reports is growing rapidly to a point where manual extraction is no longer suitable. A study of 45 of the top sites revealed that 10 years ago there were just a handful of reports a month, now there are easily over 1,000. Systems such as RecordedFuture analyse over 650,000 sources!
Current approaches to automated extraction produce a large number of false positives, making the results unsuitable for being directly fed into security systems.
The problem is not as difficult as the general fact extraction one (see e.g. DeepDive) though:
A key observation from the open intelligence sources producing high-quality IOCs is that technical articles and posts tend to describe IOCs in a simple and straightforward manner, using a fixed set of context terms (e.g., “download”, “attachment”, “PE”, “Registry”, etc.), which are related to the iocterms used in OpenIOC to label the types of IOCs. Further, the grammatical connections between such terms and their corresponding IOCs are also quite stable: e.g., the verb “downloads” followed by the nouns “file” and ok.zip (the IOC) with a compound relation; “attachments” and clickme.zip also with the compound relation.
Which makes it sound as if it should be relatively easy! There’s quite a bit to it though, so let’s take a look at the end-to-end process.
iACE from soup to nuts
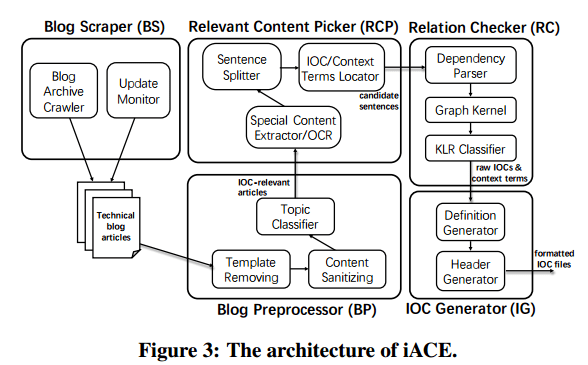
There are five main components in iACE: a blog scraper; blog preprocessor; relevant content picker; relation checker; and finally the IOC generator. One of the things I like is that at each step, by mostly taking advantage of prior art and existing libraries and integrating them cleverly, they are able to build towards a powerful and novel solution. It’s a great example of what’s possible with modern system building when you have awareness of some of the building blocks out there (or a willingness and inclination to go and search for them!).
Blog scraping and preprocessing
The starting point is a list of known blogs (45 in this case) to monitor. A crawler downloads the blog sites and then the pre-processor gets to work finding the relevant pages, and the relevant sections of the relevant pages. The first time iACE encounters a new site it starts by doing a breadth-first crawl. This of course will capture all of the site’s pages, not just the ones of interest. Relying on the fact that there will be more blog posts than anything else, the blog scraper uses the Python beautifulsoup library to extract the HTML template from each page. Pages with templates that are infrequently used are pruned out.
From the resulting set of pages, a similar analysis looks for content that appears the same across many pages, though not necessarily on every page (e.g. blog contributor’s photos and so on).
Such a difference is captured by an information-theoretic metric called composite importance (CI) [47] that is used by the BS to measure the uniqueness of each node on each page’s DOM tree with regards to other pages: the nodes found to be less unique (rather common across different pages) are discovered and dropped from the DOM tree, using an algorithm proposed in the prior research [47].
The next step uses Tesseract to capture text from any images, the images are automatically pre-processed using Gimp to help improve recognition accuracy. The combination is able to extract text from blog images with accuracy over 95%.
Finding relevant articles
Given the above set of pruned article pages, the relevant content picker examines their content to find out which ones might include IOCs. This is done using an SVM-based classifier trained on a corpus of 150 IOC articles and 300 non-IOC articles. In evaluation, the model obtained a precision of 98% with 100% recall! The features used by the classifier are:
- Topic words: topic term extraction is a well-studied NLP technique, and the authors used the
topia.termextractopen source tool to collect the top 20 terms together with their frequencies for each article. - Article length: IOC articles tend to be longer. No special libraries required!
- Dictionary word density: IOC articles tend to have a lower dictionary word density, because most IOCs are non-dictionary words. The
enchantlibrary is used to find dictionary words in an article. The dictionary word density feature is then just the ratio of dictionary words to total words.
Now that we have IOC articles, the next step is to find the sentences, tables, and lists most likely to contain IOC indicators from within the articles. The content is selected by looking for certain anchors it may contain – i.e. context terms and possible IOC tokens. 600 carefully constructed regexes (that’s a codebase I wouldn’t want to maintain!) are used, in combination with Semanticlink to recover other semantic-related terms. At this point we have candidate sentences, but this is still not suffcient to give high enough accuracy (avoiding lots of false positives).
Fundamentally, the coincidence of relevant tokens (context term and IOC token) does not necessarily indicate the presence of an IOC-related description. Most important here is the consistency between the relation of these tokens and what is expected from the narrative of IOCs…
This is very close to the NLP problem of Relation Extraction (RE), but not quite close enough for those libraries to be directly applicable. Instead the team modelled it as a graph mining problem, using graph similarity comparisons to detect the presence of the desired relations. This is the job of the Relation checker component of iACE:
To analyze the relation between an IOC candidate and a context term, our approach first uses a dependency parser to transform a sentence into a dependency graph (DG). A DG describes the grammatical connections between different linguistic tokens, with verbs being the structural center of a clause and other tokens directly or indirectly depending on the center. Such a dependency describes the grammatical connection among tokens such as direct object, determinant, noun compound modifier, etc… In our research, the DG was constructed using the Stanford dependency parser [20], the state-of-the-art open-source tool that converts text to simplified grammatical patterns suitable for relations extraction.
Given the dependency graph, the task now becomes to check how similar it is to known patterns. This is done by comparing paths using the direct product kernel graph mining technique, “a function that measures the similarity of two graphs by counting the number of all possible pairs of arbitrarily long random walks with identical label sequences.”
Based on our customized direct-product kernel, we run a classifier (the relation checker) to determine the presence of IOC relations between a context term and an IOC candidate within a sentence. The classifier is trained over DS-Labeled with 1500 positive instances and 3000 negative instances
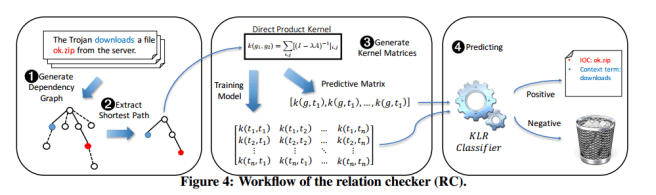
After identifying the IOC and its corresponding context terms, and validating them with the relations checker, all that remains is to export the discovered content in OpenIOC record format….
Specifically, each indicator item in the record is created by filling in the search attribute in the Context tag with a context term and the Content tag with its corresponding IOC. The content of other fields on the item can be derived from these two fields… For the header of the record, the IG generates the content for the Description tag using the open-source automatic summarization tool TextRank to create a summary for the blog article. Also, the original blog link address is used to fill the link tag, and the content of authored_by and authored_date tag are set to our prototype name and the file generation time.
A few interesting learnings from the results
The team compared iACE against the Stanford NER tool and against a commercial IOC identifier. All three systems were run on 500 randomly selected articles from 25 blogs. iACE extracted IOC items across 427 OpenIOC categories with a precision of 98% and recall of 93%. The competitors recovers IOCs in 8 categories with precision of 72% and a recall of 56%
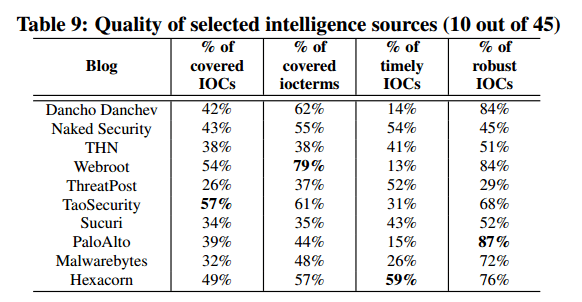
The most informative intelligence sources (based on first reports) were as follows:
Through mining the [extracted] IOCs across articles and blogs, we gained new insights into reported attacks and discovered connections never known before. Such connections shed new light on the way the adversaries organize their campaigns and adapt their techniques. Further linking the reported IOCs to auxiliary data sources reveals the impact of such CTI on the responses to emerging threats.
By grouping articles into clusters the team were able to find links between attacks never before known, including examples where long running attacks share a few critical resources. One command & control network was discovered to have been in operation for a very long time (2009-2013), continuously adapting its attack strategies and techniques. iACE was able to draw the connections between its activities and present the full picture.
The authors conclude:
By anchoring a sentence with putative IOC tokens and context terms, our approach can efficiently validate the correctness of these elements using their relations, through a novel application of graph similarity comparison. This simple technique is found to be highly effective, vastly outperforming the top-of-the-line industry IOC analyzer and NER tool in terms of precision and coverage. Our evaluation of over 71,000 articles released in the past 13 years further reveals intrinsic connections across hundreds of seemingly unrelated attack instances and the impacts of open-source IOCs on the defense against emerging threats, which highlights the significance of this first step toward fully automated cyber threat intelligence gathering.
