Ground: A Data Context Service Hellerstein et al. , CIDR 2017
An unfortunate consequence of the disaggregated nature of contemporary data systems is the lack of a standard mechanism to assemble a collective understanding of the origin, scope, and usage of the data they manage.
Put more bluntly, many organisations have only a fuzzy picture at best of what data they have, where it came from, who uses it, and what results depend on it. These are all issues relating to metadata. And the metadata problem is now hitting a crisis point for two key reasons:
- Poor organisational productivity – valuable data is hard to find and human effort is routinely duplicated. Google’s GOODs and machine learning lineage systems [1], [2] that we looked at last year provide ample evidence of the productivity enhancements (near necessity) of metadata systems at scale.
- Governance risk. This is becoming an increasingly serious issue as regulators clamp down on the use and transfer of data.
Data management necessarily entails tracking or controlling who accesses data, what they do with it, where they put it, and how it gets consumed downstream. In the absence of a standard place to store metadata and answer these questions, it is impossible to enforce policies and/or audit behaviour.
With e.g., the forthcoming GDPR regulations, if you can’t do that and your data contains information about people, then you could be liable for fines of $20M or 4% of revenue, whichever is the higher.
Data context services represent an opportunity for database technology innovation, and an urgent requirement for the field.
Hellerstein et al. argue that in addition to the three V’s of big data, we should be worrying about the ‘ABCs’ of data context: Applications, Behaviour, and Change.
A is for Applications
Application context describes how data gets interpreted for use: this could include encodings, schemas, ontologies, statistical models and so on. The definition is broad:
All of the artifacts involved – wrangling scripts, view definitions, model parameters, training sets, etc., – are critical aspects of application context.
B is for Behaviour
Behavioural context captures how data is created and used over time. Note that it therefore spans multiple services, applications, and so on.
Not only must we track upstream lineage – the data sets and code that led to the creation of the data object – we must also track the downstream lineage, including data products derived from this data object.
In additional to lineage, also included in the behavioural context bucket are logs of usage. “As a result, behavioural context metadata can often be larger than the data itself!”
C is for Change
The change context includes the version history of data, code and associated information.
By tracking the version history of all objects spanning code, data, and entire analytics pipelines, we can simplify debugging and enable auditing and counterfactual analysis.
P is for People and Purpose?
Adding a ‘P’ rather messes up the nice ‘ABC’ scheme, but in relation to privacy regulations (e.g., the aforementioned GDPR), I think I would be tempted to also call out People and perhaps Purpose as top level parts of the model. (In Ground, these would be subsumed as a part of the application context). An organisation needs to to be able to track all information it has relating to a given person, and every system that processes that information. Moreover, under the GDPR, it will also need to track the purposes of use for which consent was given when the data was collected and be able to demonstrate that the data is not used outside of those purposes.
G is for Ground
The authors are building a data context service called Ground, aiming to be a single point of access for information about data and its usage. Ground has a shared metamodel used to describe application, behaviour and change contextual information. This metamodel is the ‘common ground’ on which everything comes together. ‘Above ground’ services build on top of this metadata (see examples in the figure below). ‘Below ground’ services are concerned with capturing and maintaining the information in the metamodel.

Information can get into Ground via both above ground and below ground services: via crawling (as in GOODs), via REST APIs, in batches via a message bus or indeed several other means. As metadata arrives, Ground publishes notifications which can be consumed by above ground services that may for example enrich it.
For example, an application can subscribe for file crawl events, hand off the files to an entity extraction system like OpenCalais or Alchemy API, and subsequently tag the corresponding Common Ground metadata objects with the extracted entities.
Ground’s storage engine must be flexible enough to efficiently store and retrieve rich metadata including version management information, model graphs, and lineage storage. Both metadata feature extraction and metadata storage are noted as active research areas.
Having ingested, enriched, and stored the metadata, we probably also ought to have some kind of search or query interface to make use of it. Metadata use cases will need combinations of search-style indexing (e.g., for querying over tags), support for analytical workloads (e.g., over usage aka exhaust data), and graph style queries supporting transitive closures etc.
… various open-source solutions can address these workloads at some level, but there is significant opportunity for research here.
G is also for Graph
Each kind of contextual data (Application, Behavioural, and Change) is captured by a different kind of graph. (Note that as with dependency-driven analytics that we looked at last week, graphs seem to be the most natural structure for the metadata layer that sits on top off all the data within an organisation. This is a major future scale-out use case for graph databases).
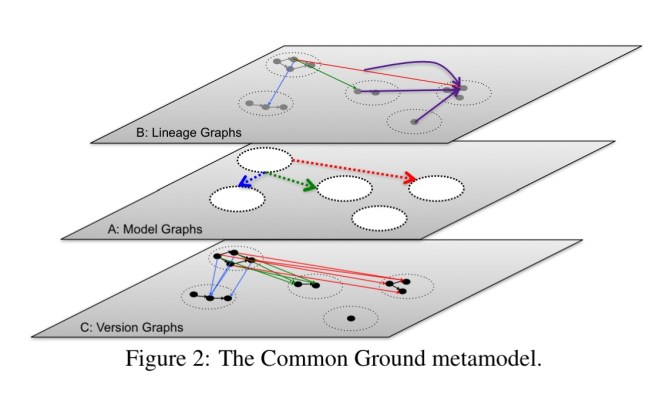
Application context is represented by model graphs which capture entities and the relationships between them.
Change context is represented by version graphs which form the base of the model, and capture versions of everything above them. There’s a cute definition of a “Schrödinger” version for items such as Google Docs whose metadata is managed outside of Ground – every time the metadata is accessed via Ground’s APIs, Ground fetches the external object and generates a new external version, thus ‘each time we observe an ExternalVersion it changes.’ Using this strategy Ground can track the history of an external object as it was perceived by Ground-enabled applications.
Behavioural context is represented by lineage graphs which relate principals (actors that can work with data such as users, groups and roles) and workflows which represent things that can be invoked to process data. Ground captures lineage as a relationship between versions. Usage data may often be generated by analyzing log files. We looked at a number of systems for extracting causal chains from log files in October of 2015 (e.g lprof, The Mystery Machine).
An example is given of the ‘Grit’ aboveground service which tracks git repositories, their commits and commit messages, the files within them and their versions, users and the actions they performed. Grit is a good indication of the breadth of vision for Ground in capturing all metadata relating to anything that touches data within an organisation.
Building Ground
An initial version of Ground, called Ground Zero has been built, mostly to serve as an exploratory platform to see how well suited today’s technology building blocks are to creating such a system. Trying to store the metamodel information in a relational database (in this case PostgreSQL), the team were unable to get query performance within an order of magnitude of graph processing systems. An in-memory graph was built using JGraphT on top of Cassandra (with the time to build the graph not included in the figures below), and performed better. Modelling with Neo4j was straightforward and querying was fast. Both JGraphT and Neo4j can only scale to a single node however. The TitanDB scale-out graph did not perform competitively in the analysis.

… there are no clear scalable open source “winners” in either log or graph processing. Leading log processing solutions like Splunk and SumoLogic are closed-source and the area is not well studied in research. [AC: what about the ELK stack?]. There are many research papers and active workshops on graph databases, but we found the leading systems lacking.
What next?
The Ground project is only just getting started. Future work includes:
- further investigation (and possible design of something new) for data context data storage and query
- integration of schema and entity extraction technologies up to and including knowledge base extraction with systems such as DeepDive
- capturing exhaust from data-centric tools (wrangling and integration
- using the usage relationships uncovered between users, applications and datasets to provide insights into the way an organisation functions
- improving governance (see below)
- and connecting commonly used modelling frameworks such as sci-kit learn and TensorFlow to Ground
Simple assurances like enforcing access control or auditing usage become extremely complex for organizations that deploy networks of complex software across multiple sites and sub-organizations. This is hard for well-intentioned organizations, and opaque for the broader community. Improvements to this state of practice would be welcome on all fronts. To begin, contextual information needs to be easy to capture in a common infrastructure. Ground is an effort to enable that beginning, but there is much more to be done in terms of capturing and authenticating sufficient data lineage for governance—whether in legacy or de novo systems.

So glad to see work being done on metadata systems. This is a huge issue for larger companies and has some of the greatest ROI in my opinion.