Dependency-driven analytics: a compass for uncharted data oceans Mavlyutov et al. CIDR 2017
Like yesterday’s paper, today’s paper considers what to do when you simply have too much data to be able to process it all. Forget data lakes, we’re in data ocean territory now. This is a problem Microsoft faced with their large clusters of up to 50K nodes each producing petabytes of ‘exhaust’ logs daily. In those logs is all the information you need to be able to answer many interesting questions but getting at in poses two key problems:
- The log data is the collected output of many disparate systems. It’s hard for humans to understand the intricacies of all the different log formats to parse and analyse them. Plus, they keep on changing anyway!
- The computational costs for scanning, filtering, and joining the log data in its raw form are prohibitive.
If only there were some kind of cost-effective pre-processing we could do on the raw data, that would make (the majority of) most subsequent queries easier to express and much faster to execute…
Log entries relate to entities (machines, jobs, files and so on). Guider is the Microsoft system that extracts those entities and builds a graph structure with entities as nodes, and edges representing relationships between them.
The result is a declarative, directed and informed access to the logs that saves users hours of development time, reduces the computational cost of common analyses by orders of magnitude, and enables interactive exploration of the logs.
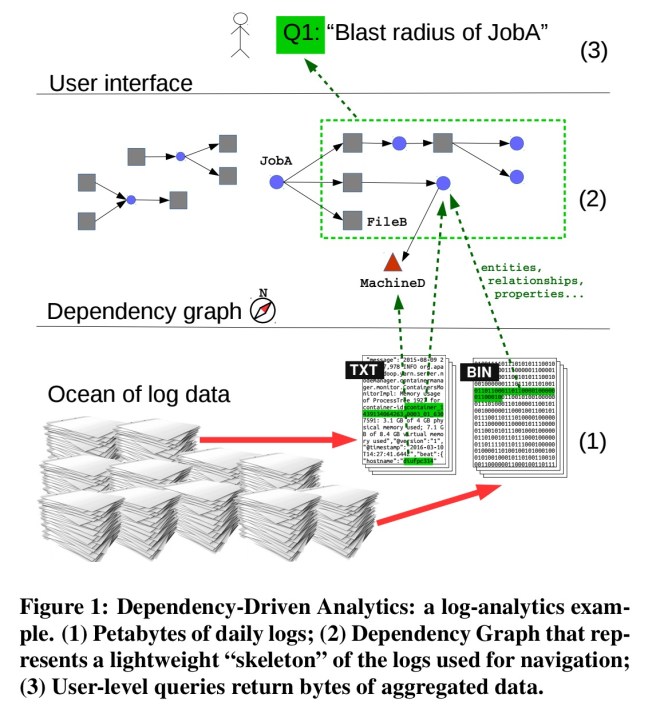
This idea of building a compact graph representation on top of the underlying raw data is coined by the authors ‘Dependency-Driven Analytics’ :
Dependency-Driven Analytics (DDA) is a new pattern in data analytics in which massive volumes of largely unstructured data are accessed through a compact and semantically-rich overlay structure: the dependency graph. The dependency graph fulfils two roles: it serves as 1) a conceptual map of the domain being modelled as well as 2) an index for some of the underlying raw data.
Where do graph structures really win over relational or other data structures? When you need to navigate lots of relationships. And this is precisely how they help in DDA use cases:
Instead of sifting through massive volumes of shapeless data, the user of a DDA system can navigate this conceptual map, and quickly correlate items which are very far apart in the data, but directly or indirectly connected through the dependency graph. Our experience indicates that this drastically lowers the cognitive cost of accessing the unstructured data.
Lets look at some examples of where Guider has been used in Microsoft to make this idea a little more concrete:
- A global job ranking system that uses Guider to traverse the dependencies between jobs. The key query here is the “job failure blast radius” query which aims to calculate the number of CPU-hours of downstream jobs of some job j that will be impacted if j fails. With Guider this transitive query can be answered simply using a graph query language, but is very difficult to answer from the raw logs.
- Finding the root cause of a job failure (which is quite similar in spirit to the blast radius query, only you need to seek upstream, not downstream).
- The impressive Morpheus automatic SLO discovery and management framework that we look at last year using Guider to access the dependency graph as its main inference tool.
- Planning a data center migration using Guider to create a projection of the graph at tenant level, where edges store the amount of reads/writes shared by two tenants.
- An auditing and compliance system that operates over a DDA dependency graph and a list of compliance rules. This is a really important use case with all the forthcoming privacy regulations in GPDR, so I hope you’ll forgive me for an extended quotation here:
Current storage and access technologies guarantee data integrity and protect against unauthorized access, but cannot enforce legal regulations or business rules. A number of important regulations prevent data to flow across geographic regions, like European Union regulations prohibiting the copy of “personal data” beyond jurisdictional boundaries. There are also laws and business rules for data at rest, for example requirements to delete personal data identifying users access to online services after a given period of time (e.g., 18 months), or business agreements restricting 3rd-party data access to certain scenarios. Current data stores are unable to identify policy violations in that context (e.g., based on flexible business rules). At Microsoft, we have deployed a monitoring system leveraging DDA for that purpose.
Before the DDA system, auditing was manual and substantially more costly…
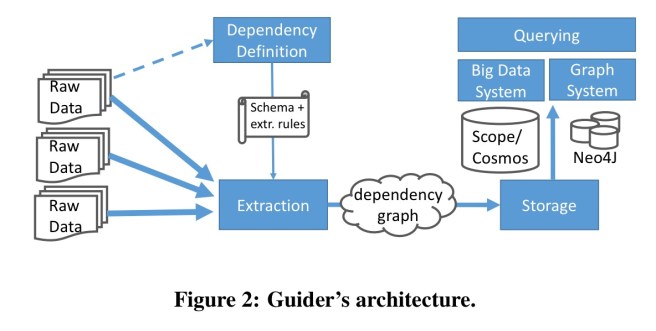
We’ve established therefore that traversing the graph of relationships between entities can be highly useful when understanding a big dataset. That should come as no surprise. The team would like to be able to run large scale graph queries over the resulting graph, but currently they are limited to loading and querying small subsets of the graph via an ETL process. Neo4j was the only graph engine Microsoft found that was robust enough to handle the workload, but is restricted to a single instance.
We considered several other graph technologies, including TitanDB, Spark GraphFrames, and Tinkerpop/Tinkergraph, but at the current state of stability/development they were not sufficiently capable for our setting.
None of the approaches, including the limited Neo4j solution, is really satisfactory (‘creating, storing and manipulating the graph at scale is a major technical issue’), and the authors are pretty clear about what they’d like to see here:
This experience indicates that industry is in desperate need for a fully capable, scale-out graph solution that can handle complex, large, and structured graphs, as well as a unified surface language for graph, relational and unstructured data handling.
If you’re interested in large-scale graph processing, we spent a couple of weeks looking at the topic back in May 2015 on The Morning Paper and continuing into June.
The research agenda for Guider has two main strands. The first is to find an optimized structure for storing and querying DDA graphs. In particular, it may be possible to take advantage of certain properties of the dependency graph that general purpose graph-engines cannot depend upon:
The fact that the structure we operate on is a causal, temporal graph allows us to prune all nodes/edges that “precede” the source node JobAi chronologically. This pruning can be pushed down to the storage of the graph (like we do in our time-partitioned DFS copy of the graph) to dramatically reduce IO. The fact that nodes and edges are typed can also be used for pruning, further reducing the cardinality of scans and joins. We advocate for a system that automatically derives such complex constraints (as part of the dependency definition process), and leverages them during query optimization.
The second strand of future research is to see if entities and their relationships can be automatically extracted from log entries, rather than the fragile manual log mining scripts the team depend on today. In a fast-moving ecosystem, these require constant maintenance. As as example, Hadoop alone has 11K log statements spread over 1.8M lines of code, 300kloc of which changed during 2015 alone. The proposed direction is to take advantage of information in the source code itself. Although the authors don’t cite the paper, the sketch they present is very similar to the approach used by lprof, so I’m going to refer you to my write-up of lprof’s log file and source code analysis rather than repeat it here.
Then there will just remain one final challenge : ;)
To further complicate this task, our next challenge is to achieve all this in near real-time as data items are produced across hundreds of thousands of machines. At Microsoft, we have built solutions to ingest logs at such a massive scale, but stream-oriented entity extraction and linking at this scale remains an open problem.

Adrian thank you so much for noticing us!
I am following your blog and seeing our paper here is simply awesome!)
PS: May I ask you to correct the first author’s surname though? (it is Mavlyutov). Thank you!
Spelling corrected – sorry for the mistake. I have a hunch we may see many more overlay graphs for navigating enterprise resources in time :).
For sure, several labs are working on systems like this at the moment.
Thanks for the update!