Prioritizing attention in fast data: principles and promise Bailis et al., CIDR 2017
Today it’s two for the price of one as we get a life lesson in addition to a wonderfully thought-provoking piece of research.
I’m sure you’d all agree that we’re drowning in information – so much content being pumped out all of the time! (And hey, this blog has to take a share of the blame there too :) ). Can you read all of the articles, keep up with all of the tweets, watch all of the latest YouTube videos, and so on?
Back in 1971, Herbert Simon wrote a piece entitled “Designing organizations for an information rich world” (they really had no idea just how much of an information flood was coming back then though!). In it Simon says:
In an information-rich world, the wealth of information means a dearth of something else: a scarcity of whatever it is that information consumes. What information consumes is rather obvious: it consumes the attention of its recipients.
We have a limited capacity for what we can actually pay attention to – only the tiniest portion of all the available information. You could try uniform random sampling, but a better strategy is to prioritize where you choose to spend your attention budget (why? – not all content has equal merit). Here’s a personal example – I watch very little tv (what I do watch is largely selected live sporting events) and don’t follow the news (I find very little is actionable, and the really important stuff has a way of creeping into my consciousness anyway). I used the freed-up attention budget to learn, and a lot of it goes into reading and writing up research papers.
Imagine that those streams of incoming tweets, articles, videos and so on are instead events streaming into a big data system. The volume and velocity of the incoming data is such that we have exactly the same problem: we can’t meaningfully pay attention to it all – we have to prioritise.
… we believe that the impending era of fast data will be marked by an overabundance of data and a relative scarcity of resources to process and interpret it.
This prioritisation has two stages: first we have to prioritize the attention of our machines (where we choose to spend our computational budget in processing the incoming data), and then we really have to prioritize what information gets flagged up to humans as requiring attention. Human ability to process information has sadly failed to follow Moore’s law ;). You end up with a picture that looks like this:
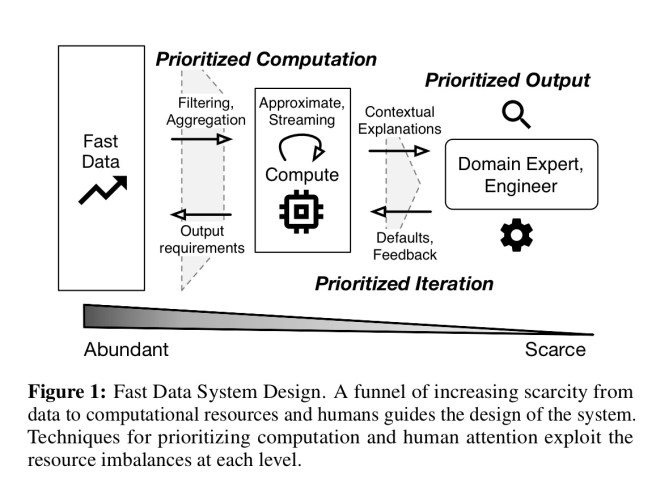
As an example, consider a web service generating millions of events per second. There’s a limit to how much processing you can do as those events fly by – if you fall behind you’re never going to catch up again. Strictly in fact, there are multiple limits (or budgets) – a response time budget, a computational resources budget, and a space budget. Let’s say we’re looking for anomalous patterns in the data – flagging too many of these to human operators is next to useless – they’ll just develop alert-blindness and the really important issues will go unaddressed.
The ‘fast data manifesto‘ the authors propose is based on three principles for designing fast data: prioritize output, prioritize iteration, and prioritize computation.
Prioritize Output: The design must deliver more information using less output. Each result provided to the user costs attention. A few general results are better than many specific results… Fast data systems can prioritize attention by producing summaries and aggregates that contextualize and highlight key behaviors within and across records; for example, instead of reporting all 128K problematic records produced by device 1337, the system can simply return the device ID and a count of records.
As another example of the same phenomenon, one of the companies I’m involved with, Atomist, greatly improved the utility of notifications in their engineering Slack channel by aggregating and contextualising notifications related to builds, deploys, and commits.
Prioritize Iteration: The design should allow iterative feedback-driven development. Give useful defaults, and make it easy to tune analysis pipelines and routines. It is slightly better to be flexible than perfectly precise.
The scarce resource we’re prioritizing the use of here is the human domain experts and the time it takes them to develop high-quality analyses. Iteration is key to this, so that shorter we can make the feedback-cycles, the more productive the team will be.
Prioritize Computation: The design must prioritize computation on inputs that most affect its output. The fastest way to compute is to avoid computation. Avoid computation on inputs that contribute less to output.
When you unpack “prioritizing computation on inputs that most affect outputs” you get to something pretty exciting. Most stream processing systems leave the design of complex analysis routines to their end users, and most ML and statistics methods have historically optimized for prediction quality.
As a result, the trade-offs between quality and speed in a given domain are often unexplored.
(Approximate Query Processing is one area of CS that has explicitly explored some of these trade-offs, also some asynchronous machine learning algorithms).
If you accept that not all inputs will contribute equally to the outputs, then you arrive at a conclusion that has a lot of similarities to the use of backpropagation in machine learning…
Fast data systems should start from the output and work backwards towards the input, doing as little work as needed on each piece of data, priortizing computation over data that matters most. Gluing together black-box functions that are unaware of the final output will miss critical opportunities for fast compute; if a component is unaware of the final output, it is likely to wast time and resources. By quickly identifying inputs that most contribute to the output, we can aggressively prune the amount of computation required.
(See also Weld that we looked at earlier this week for another example of the value of understanding the desired end output when optimising).
MacroBase
MacroBase is a fast data system built to explore the fast data principles above. We looked at an early version of MacroBase on The Morning Paper last March. MacroBase has since generalized from the single analytics workflow used as the basis for the initial exploration.
MacroBase provides a set of composable, streaming dataflow operators designed to prioritize attention. These operators perform tasks including feature extraction, supervised and unsupervised classification, explanation and summarization.
MacroBase is based on a dataflow model, and takes advantage of underlying dataflow engines instead of reinventing the wheel there.
Although MacroBase’s core computational primitives continue to evolve, we have found that expressing them via a dataflow computation model is useful. Many developers of recent specialized analytics engines expended considerable effort devising new techniques for scheduling, partitioning, and scaling their specialized analytics only to see most performance gains recouped (or even surpassed) by traditional dataflow-oriented engines.
When it comes to prioritizing output MacroBase allows users to highlight highlight fields of interest within inputs as either key performance metrics, or as important explanatory attributes. MacroBase then outputs a set of explanations regarding correlated behaviors within the selected metrics. There are some similarities here to DBSherlock that we looked at last year, although that starts with the user highlighting an anomalous region of interest.
Looking forward, we believe current practice in high-volume error explanation and diagnosis is especially ripe for improvement.
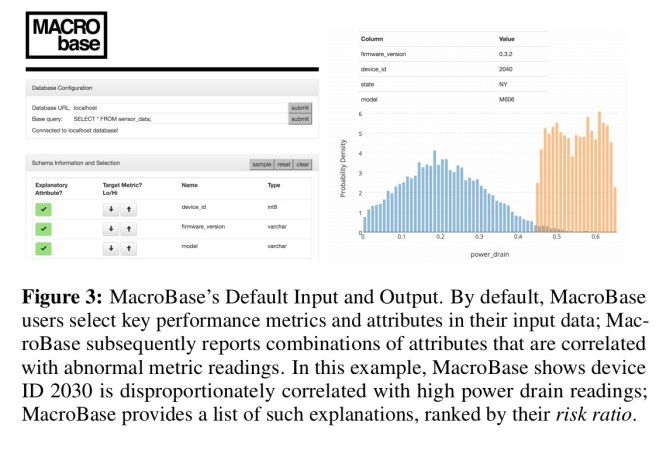
MacroBase supports fast iteration by allowing users to interact at three different levels. A point-and-click interface allows a user to specify a source from which to ingest data, identify the key attributes as above, and see explanations in the form of combinations of attributes correlated with abnormal metrics.
At the next level down, users can use Java to configure custom pipelines and incorporate domain-specific logic. Finally, at the lowest level of the system users can implement new analytics operators.

The prioritized computation pieces of MacroBase look to be especially exciting, though what we mostly get here is a teaser for information to be expounded in more depth in a forthcoming SIGMOD 2017 paper.
Bailis et al. found that the most accurate techniques were often too slow for MacroBase use cases – for example, an initial prototype explanation operator became too slow even at 100K point datasets. Drawing on their database systems pedigree, the authors are not afraid to challenge the status quo:
Applying classical systems techniques – including predicate pushdown, incremental memorization, partial materialization, cardinality estimation, approximate query processing, and shared scans — has accelerated common operations in MacroBase. Per the principle of prioritizing computation, by focusing on the end results of the computation, we can avoid a great deal of unnecessary work…. Stacked end-to-end, the several order-of-magnitude speedups we have achieved via the above techniques enable analysis over larger datasets (e.g., response times reduced from hours to seconds).
There’s plenty more interesting material in the paper itself, but space precludes me from covering it all. If this has piqued your interest at all, it’s well worth reading the full paper. I’ll leave you with the following concluding remark from the authors:
We view MacroBase as a concrete instantiation of a larger trend towards systems that not only train models but also enable end-to-end data product development and model deployment; solely addressing model training ignores both the end-to-end needs of users and opportunities for optimization throughout the analysis pipeline.

2 thoughts on “Prioritizing attention in fast data: principles and promise”
Comments are closed.