Asynchronous Complex Analytics in a Distributed Dataflow Architecture – Gonzalez et al. 2015
Here’s a theme we’ve seen before: the programming model offered by large scale distributed systems doesn’t always lend itself to efficient algorithms for solving certain classes of problems. In today’s paper, Gonzalez et al. examine the growing gap between efficient machine learning algorithms exploiting asynchrony and fine-grained communication, and commodity distributed dataflow systems (Hadoop and Spark) that are optimized for coarse-grained models.
We’ve also seen how effective coordination avoidance can be in the context of distributed datastores. The same theme is emerging in machine learning where for some algorithms non-serializable lock-free implementations offer significant speed-ups, and the statistical nature of the problem means that these implementations can still guarantee correctness.
Consider stochastic gradient descent:
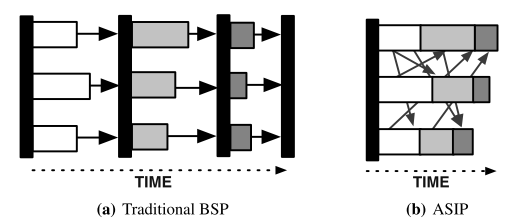
If we wish to use an algorithm like SGD on large datasets, it would be advantageous to parallelize the calculation. A classic technique—adopted by large-scale machine learning frameworks such as MLbase/MLlib —is mini-batch gradient descent in which, at each step, the average gradient is calculated in parallel for a random subset of the data and then applied to the previous best solution. This is, in effect, BSP execution, with the gradient evaluation done in parallel and the actual gradient step performed serially.
This approach is well-matched to Apache Spark’s processing model. BSP has periodic synchronization to move processes from one superstep to another. In place of this periodic synchronous communication though, the ML community is looking towards continuous asynchronous communication. This is not well suited to the Apache Spark model.
Recent work in the machine learning community has examined an alternative approach: instead of simply parallelizing gradient computation, a set of parallel solvers proceeds entirely concurrently, relying on asynchronous communication of intermediate gradient steps. As an example, the HOGWILD! implementation of SGD places a single copy of the model in the memory of a multi-core server and runs multiple worker processes that simultaneously run gradient steps in parallel. Each gradient update may partially or completely overwrite or be overwritten by another solver’s update, leading to non-serializable execution. However, empirically, this “lock-free” approach can deliver substantial speedups over serializable mechanisms like locking. Dropping synchronization barriers improves performance without compromising correctness (at least on a single machine). The rationale behind HOGWILD! is that, with sufficiently rare conflicts and sufficiently fast communication (i.e., cache coherency delays on the order of tens or hundreds of cycles), correctness can still be guaranteed—even theoretically. The statistical robustness inherent in the SGD algorithm as well as limited read/write inconsistency still leads to a good solution—without incurring the overhead of more coordination-intensive approaches like BSP or locking.
The asynchronous approach is being applied to many problems including coordinate descent, deep learning, and portfolio optimization. On single-node systems the approach yields order-of-magnitude improvements in performance. If BSP-based dataflow engines can’t support this model, are we heading towards a fork in the road?
The technological trajectory outlined by recent research suggests a divide between widely-deployed dataflow-based cluster compute frameworks and specialized asynchronous optimization mechanisms, which largely rely on a shared memory abstraction… The architectural underpinnings of systems such as Spark, Hadoop, and Tez favor large-scale, bulk data movement and transformation via shared-nothing parallel dataflow. The fine-grained communication required by this new class of asynchronous algorithms is largely unsupported by these system architectures and implementations.
Do we need to abandon Apache Spark and Hadoop when performing asynchronous statistical optimization in a distributed setting? The authors show that this is not the case, by introducing an asynchronous communications mechanism into these frameworks:
…to retain the strengths, considerable engineering investments, and, pragmatically, large (and growing) install bases of these frameworks we develop a method to enable asynchronous convex programming within a general-purpose distributed dataflow framework. Somewhat surprisingly, enabling these optimization tasks only requires a minor change to their popular BSP-like iterator interface. However, this in turn raises several new challenges, including support for fault tolerance and efficient task scheduling
The minor change is the introduction of an Asynchronous Sideways Information Passing (ASIP) interface which allows communication between operators of the same stage.
The ASIP interface adds the ability to push a message to other operators, and to receive messages via a non-blocking poll.
Like the exchange operator, the exact details of cross-operator distribution and physical layout are opaque to the operator implementation. Instead, programmers using ASIP implementers can simply treat the ASIP iterator as a special operator from which they can send and receive intermediate data from concurrently-executing physical operator instances within the same datflow stage. Unlike a BSP model, in which communication between operators is delayed until the end of each process’s pass through its partition data, under ASIP, processes communicate asynchronously via ASIP. Thus, ASIP adapts the BSP model by eliminating the explicit synchronous barrier in each step of computation and instead allows individual steps to proceed out of phase
Programming with ASIP
The authors present two examples of algorithms adapted to use ASIP: ASIP Stochastic Gradient Descent, and ASIP Alternating Direction Method of Multipliers (ADMM).
In BSP-based SGD gradients are computed for a number of samples in parallel, and then gradients are collected and summed at a synchronization barrier before proceeding to the next step. ASIP-SGD avoids this blocking and allows individual parallel workers to proceed in parallel, exchanging information via the ASIP operator. Workers push their gradients to ASIP and upon receipt of a new gradient via poll, apply it (i.e. add it) to their current model.
ASIP-ADMM similarly breaks down the BSP barrier required between the primal and dual stages in the original algorithm, and allows solvers to proceed in parallel. “After solving its kth primal stage, each local solver performs a push of its current model and issues a set of poll requests to receive other solvers’s most recent primal variables and update the consensus and Lagrangian terms before continuing.”
See the full paper for detailed descriptions of both algorithms.
Supporting ASIP within Apache Spark
The ASIP operator poses challenges to implementation in a synchronous distributed dataflow system such as Hadoop or Spark. One could simulate an ASIP-like operation by discretely time-stepping via individual BSP rounds. However, this is conceptually at odds with the asynchronous nature of the tasks we study here and potentially expensive for fine-grained messaging in a distributed setting. Instead, the most straightforward integration within an existing dataflow system is to provide a communication layer between parallel dataflow tasks via the local network.
The prototype is implemented on top of Apache Spark and exploits Spark’s existing actor-based control channel.
Spark maintains a communications network that is used for cluster maintenance and scheduling, based on Akka’s Actor system. To implement ASIP, we register a per-ASIP operator actor instance with each partition within Spark and obtain actor references for all other parallel ASIP operator instances. The ASIP actor within Spark facilitates both push—via one-way messages to other actors—and poll—via an in-actor message queue that is appended to upon message receipt
If all of the data to be passed between operators was sent through the ASIP channels, the serialization and deserialization overheads could easily dwarf any benefits from the actual optimization. Instead ASIP messages should be used as a control channel, and actual data transfer should be via Spark’s distribution network.
This also preserves any native scheduler functionality providing data locality for individual operator placements. Neither of our ASIP algorithms uses ASIP for actual data transfer between partitions (e.g., re-partitioning training data across machines)—rather, the ASIP operator conveys information about model updates.
To perform asynchronous learning, operators need to be able to exchange information as they are running – which means they need to be running at the same time! “Thus, we adopt a gang-scheduled approach to ASIP stage execution, and, for correct execution, all operators should—in the limit —be able exchange messages. It is unclear how much asynchronous algorithms would benefit from ASIP in a non-gang-scheduled environment (e.g., repeatedly execute a smaller set of isolated ASIP tasks).” The actual message exchange in the prototype is a simple uniform broadcast. As in Volcano other implementations could be used transparently to the program, including variants of multicast, point-to-point communication, and aggregration trees.
In Apache Spark, deterministic execution greatly simplifies fault tolerance. Yet ASIP is non-deterministic…
It might appear that ASIP is hopelessly at odds with the these systems’ operational model. However, in the context of our asynchronous learning tasks, ASIP is actually quite compatible with these dataflow engines.
Neither ASIP-SGD nor ASIP-ADMM is serializable, yet alone determinstic. But the algorithms themselves have a built-in statistical fault-tolerance:
Specifically, a key property of ASIP in the context of these algorithms is that the information exchanged via the ASIP iterator is sufficient—on its own—to (approximately) recover the state of a lost physical operator. If a particular partition fails (or is restarted due to stragglers), the data on that partition can be re-loaded and the operator re-started; the excellent conver- gence guarantees of dual averaging and ADMM ensure that, despite any temporary deviation from the partition’s predecessor state, the partition’s successor task will eventually converge. Thus, these algorithms are statistically fault tolerant. We empirically evaluate the effect of restarts in our prototype in the next section, and demonstrate that, under reasonable delays, system restarts do not destabilize the ASIP-enabled algorithms.
How well does it work?
The ASIP-SGD and ADMM implementations were compared to their BSP based alternatives across four real-world publicly available datasets and four different learning tasks.
Across all the combination of objective function and datasets we
observe a few common trends. In general, naïve averaging performs poorly, while the ASIP-SGD generally substantially outperforms the other algorithms. In general, the asynchronous variants ASIP-SGD and ASIP-ADMM out performed their synchronous counterparts, with ASIP-SGD often outperforming GD by more than an order of magnitude. In particular, if we consider the average ratio of the objective at 10 seconds into the computation across all experiments we find that ASIP-SGD is 74 times lower than that of GD. While the objective of ASIP-ADMM is only 1.2 times lower than that ADMM we show in Figure 6 that in the presence of a single straggler ASIP-ADMM can yield more than an order of magnitude reduction in objective value.

7 thoughts on “Asynchronous Complex Analytics in a Distributed Dataflow Architecture”
Comments are closed.