Optimizing Hash-Array Mapped Tries for Fast and Lean Immutable JVM Collections – Steinforder & Vinju, 2015
You’d think that the collection classes in modern JVM-based languages would be highly efficient at this point in time – and indeed they are. But the wonderful thing is that there always seems to be room for improvement. Today’s paper examines immutable collections on the JVM – in particular, in Scala and Clojure – and highlights a new CHAMPion data structure that offers 1.3-6.7x faster iteration, and 3-25.4x faster equality checking.
CHAMP stands for Compressed Hash-Array Mapped Prefix-tree.
The use of immutable collections is on the rise…
Immutable collections are a specific area most relevant to functional/object-oriented programming such as practiced by Scala and Clojure programmers. With the advance of functional language constructs in Java 8 and functional APIs such as the stream processing API, immutable collections become more relevant to Java as well. Immutability for collections has a number of benefits: it implies referential transparency without giving up on sharing data; it satisfies safety requirements for having co-variant sub-types; it allows to safely share data in presence of concurrency.
Both Scala and Clojure use a Hash-Array Mapped Trie (HAMT) data structure for immutable collections. The HAMT data structure was originally developed by Bagwell in C/C++. It becomes less efficient when ported to the JVM due to the lack of control over memory layout and the extra indirection caused by arrays also being objects. This paper is all about the quest for an efficient JVM-based derivative of HAMTs.
Fine-tuning data structures for cache locality usually improves their runtime performance. However, HAMTs inherently feature many memory indirections due to their tree-based nature, notably when compared to array-based data structures such as hashtables. Therefore HAMTs presents an optimization challenge on the JVM. Our goal is to optimize HAMT-based data structures such that they become a strong competitor of their optimized array-based counterparts in terms of speed and memory footprints.
A HAMT Primer
Let’s start with the Trie part of HAMT. A general trie is a lookup structure for finite strings that implements a Deterministic Finite Automaton without any loops. Transitions are based on string prefixes. Internal nodes in the trie indicate prefix-sharing, and accept nodes point to values associated with the string.
If we were to encode the sometimes confused strings “Adrian Cockcroft,” “Adrian Cole,” and “Adrian Colyer” in a trie data structure it might look like this:

A Hash-Array Mapped Trie stores binary strings in place of character strings. For each element inserted in the trie, its hashcode is used as the encoding (bit) string. “The prefix tree structure grows lazily upon insertion until the new element can be distinguished unambiguously from all other elements by its hash code prefix. ”
Starting with an empty HAMT, let’s insert a few elements: A,B, C, and D:
hash(A) = 010...
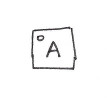
hash(B) = 200...

hash(C) = 204...
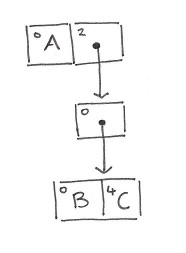
hash(D) = 210...
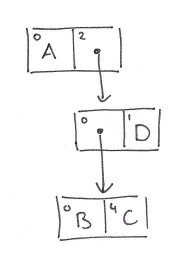
…
At each level we encode one more digit of the hash. If we encode the hash according to some base b, e.g. base 32, then each digit will be in the range 0..(b-1). Using base32 we can therefore encode a level of the tree as an array of length 32. Each entry in the array will contain either a reference to the next level, or an actual value. A 32-bit bitmap is maintained alongside the array so that we can keep track of which slots are in use (and instanceof can be used to distinguish between values and sub-node references for the slots that are in use).
This structure can neatly encode a Set. To encode a Map a common technique is to double the length of the array storing storing the Key as per the Set example, and store the Value in the adjacent array slot. Each index is then multiplied by 2 to skip over the extra slots.
Some of you may be wondering what happens if there is a hash collision. There’s a reason Java says that objects that are not equal should have distinct hashcodes!
Compared to a simple array-based hashtable HAMTs stack up as follows:
HAMTs already feature efficient lookup, insert, and delete operations, however due to their tree-based nature their memory footprints and the runtime performance of iteration and equality checking lag behind array-based counterparts.
- Increased memory overhead. “Each internal trie node adds an overhead over a direct array-based encoding, so finding a small representation for internal nodes is crucial. On the other hand, HAMTs do not need expensive table resizing and do not waste (much) space on null references.”
- Delete is efficient on HAMT structures, however it can cause them to deviate from their most compact representation. Delete on most hashtable implementations is a lot less consequential.
- Iteration is slower due to non-locality – with an array-based hashtable you can simply do a linear scan through a continuous array
- Equality checking of collections can be expensive due to non-locality and the possibility of a degenerate structure due to deletes.
A new CHAMP
CHAMP is designed to provide smaller footprint and better cache locality. In the standard HAMT structure there is one array encoding both sub-node references and data values. Thus the order of child nodes and internal values may vary arbitrarily.
An in-order traversal for iteration will switch between the trie nodes a few times, because values and internal nodes alternate positions in the array, causing a bad cache performance. For iteration, the HAMT design requires to go through each node at most m + n times, where n equals the HAMT’s total number of sub-tree references and m equals the total number of references to internal data entries.
To improve things we can conceptually split the array into two: one for values, and one for sub-node references. This also removes the need for the instanceof test.
For iteration, the proposed CHAMP design reduces the complexity from O(m + n) to O(n). A full traversal in CHAMP requires exactly n node visits, because it can yield all internal values before descending for each sub-node exactly once.
To save space, we actually split the one array into two halves and store a compressed array sequence in each. To make this work, we need two 32-bit bitmaps: the datamap indicates whether a branch is absent or is a value refererence, and the nodemap indicates whether a branch is absent or is a sub-node reference.
We have increased data locality at the cost of a more expensive index calculation that requires an extra bitmap and additional bit-level operations. This directly influences the runtime performance of lookup, insertion, and deletion. Each of these operations now requires a case distinction with, in worst case, two separate lookups in the two distinct bitmaps, to decide in which group an element is present. Because we compactly store both groups in a single array, we need to perform offset-based indexing when accessing the second group of sub-node references. Both the offset and the index calculations require more bit-level operations on the datamap and nodemap…
The second key element of CHAMP is keeping the Trie in a compact canonical form, even after deleting elements:
Clojure’s HAMT implementations do not compact on delete at all, whereas Scala’s implementations do. In the remainder of this section we contribute a formalization (based on predicates and an invariant) that details how a HAMT with inline values can efficiently be kept in a compact canonical form when deleting elements. Bagwell’s original version of insert is enough to keep the tree canonical for that operation. All other operations having an effect on the shape of the trie nodes can be expressed using insertion and deletion.
See the full paper for details of the canonical representation and how to preserve the structure invariant on delete.
Tree compaction on delete lays the groundwork for faster (structural) equality checking. In an ideal world without hash collisions we would short-circuit recursive equality checks without further ado: if two nodes that are reachable by the same prefix have different bitmaps it is guaranteed that their contents differ. Together with short-circuiting on equal references (then the sub-tries are guaranteed equal), the short-circuiting on unequal bitmaps makes equality checking a sub-linear operation in practice.
The paper also includes a discussion on memoization (increases memory usage in return for improved worst-case performance in lookup, insert, and delete). Scala and the JDK implement forms of memoization, Clojure and Google’s Guava do not. A variant of CHAMP is shown, MEMCHAMP, which includes memoization support – once more, see the full paper for details.
Comparing CHAMP to the HAMT implementations in Scala and Clojure
We further evaluate the performance characteristics of CHAMP and MEMCHAMP. While the former is most comparable to Clojure’s HAMTs, the latter is most comparable to Scala’s implementations. Specifically, we compare to Clojure’s PersistentHash{Set,Map} and Scala’s immutable Hash{Set,Map} implementations. We used latest stable versions available of Scala (2.11.6) and Clojure (1.6.0) at the time of evaluation.
Compared to Clojure’s Maps
When it comes to performance…
In every runtime measurement CHAMP is better than Clojure. CHAMP improves by a median 72% for Lookup, 24% for Insert, and 32% for Delete. At iteration and equality checking, CHAMP significantly outperforms Clojure. Iteration (Key) improves by a median 83%, and Iteration (Entry) by 73%. Further, CHAMP improves on Equality (Distinct) by a median 96%, and scores several magnitudes better at Equality (Derived).
CHAMP also reduces footprint by a median 16% (32-bit).
Compared to Clojure’s Sets
The speedups are similar, and the footprint is reduced by a median of 30% (32-bit).
Compared to Scala’s Maps
Lookup performance improves by a median 23%, especially at small collections until 128 entries (34–45%). For bigger sizes the advantage is less pronounced… Insertion improves by a median 16%, however with a different pattern from lookup. Insertion performs up to 12% worse at small collections until 25 entries, and then improves again (9–28%). At Insert (Fail) CHAMP improves across the size range (23–47%). Deletion performs with a median runtime reduction of 25% better than Scala, despite of the compaction overhead… For iteration and equality checking, CHAMP clearly improves upon Scala’s immutable hash maps. Iteration (Key) improves by 48% and Iteration (Entry) by 39%. Equality (Distinct) improves by a median 81%. At Equality (Derived), unsurprisingly, we perform 100% better because the operation is in a different complexity class.
CHAMP also reduces footprint by a median 68% (32-bit).
Compared to Scala’s Sets
The results for Sets are fairly similar to Maps, but with the runtime and memory savings slightly lower across the board.
A realistic test case
Next to microbenchmarks which isolate important effects experimentally, we also need to evaluate the new design on a realistic case to be able to observe its relevance in relation to other (unexpected) factors…. We chose to use a classic algorithm from program analysis which is used in optimizing compilers, static analysis, reverse engineering tools and refactoring tools: computing the control flow dominators. Instead of implementing an optimized data structure specifically for the purpose of computing dominators on a Control-Flow Graph (CFG) we picked a most direct implementation finding a maximal solution to the two dominator equations with Scala’s and Clojure’s HAMTs, and CHAMP…
CHAMP computed the biggest CFG sample of size 4096 more than twice as fast as Scala and Clojure could compute the smallest CFG sample of size 128. “Overall, the speedups range from minimal 9.9 x to 28.1 x. The highest speedups were achieved at smaller sample sizes.”
A final word:
It is not true that every algorithm will benefit from CHAMP, but this case does provide a strong indication that if you start from the design decision of immutable intermediate data structures (functional programming), then CHAMP is bound to be faster than the traditional renderings of a HAMT on the JVM.

Not sure if this is always a win. HashSet1 in s.c.i.HashSet caches the HashCode, which might be a win for complex keys (tuples, vectors etc.)
Also, at least for HashSet there is no “degenerate structure due to deletes”. Once a branch has just one leaf, it gets removed. So you could compare HashTrieSets structurally if it wasn’t for the collisions.
Not sure if this is always a win. HashSet1 in scala.collection.immutable.HashSet caches the hashCode, which is a performance advantage for large, complex keys (Tuples, Vectors etc.)
Also, there is no “degenerate structure due to deletes” in s.c.i.HashSet: if a branch has one child after delete, it gets omitted.
This might work well with specialization though, if you want to go there…
You say: “Some of you may be wondering what happens if there is a hash collision. There’s a reason Java says that objects that are not equal should have distinct hashcodes!” Which is fair enough, only Java doesn’t say this. It _does_ say that `equal` objects must have the same hashcode, but the general contract for `hashcode()` also states:
“It is not required that if two objects are unequal according to the equals(java.lang.Object) method, then calling the hashCode method on each of the two objects must produce distinct integer results. However, the programmer should be aware that producing distinct integer results for unequal objects may improve the performance of hash tables.”
So I’m _still_ wondering what happens if there is a hash collision.
Nice article, btw: I love the ‘sketch’ diagrams.