Weld: A common runtime for high performance data analytics Palkar et al. CIDR 2017
This is the first in a series of posts looking at papers from CIDR 2017. See yesterday’s post for my conference overview.
We have a proliferation of data and analytics libraries and frameworks – for example, Spark, TensorFlow, MxNet, Numpy, Pandas, and so on. As modern applications increasingly embrace machine learning and graph analytics in addition to relational processing, we also see diverse mixes of frameworks within an application.
Unfortunately, this increased diversity has also made it harder to achieve high performance. In the past, an application could push all of the data processing work to an RDBMS, which would optimize the entire application. Today, in contrast, no single system understands the whole application.
Each individual framework may optimise its individual operations, but data movement across the functions can dominate the execution time. This is the case even when all of the movement is done within memory. Moreover, as we’ll see, the function boundaries prevent important optimisations that could otherwise fuse loops and operators.
The cost of data movement through memory is already too high to ignore in current workloads, and will likely get worse with the growing gap between processor and memory speeds. The traditional method of composing libraries, through functions that pass data to in-memory data, will be unacceptably slow.
So what are our options? One approach would be to design a single data processing system that encompasses all modes and algorithms, and heavily optimise within it. That has a couple of drawbacks: firstly, the diversity and rate and pace of development of data processing makes it very hard to keep up – trying to integrate all new developments into a single framework will be slower to market at best, and likely quite inefficient. Secondly, the one-size-fits-all universal framework, at least when it comes to extracting the best performance, is probably a fool’s errand as one of my favourite papers from 2015, Musketeer (part 1) demonstrated.
If we’re going to continue to use a variety of tools and frameworks then we’ll need another approach. Musketeer (part 2) gives us a hint: it defines a DAG-based intermediate representation (IR) that sits above any one store and can map a computation into the most appropriate runtime. Weld also defines an IR, but this time situates it underneath existing libraries and frameworks – application developers continue to use the familiar framework APIs. Weld integrations in the frameworks map the operations to Weld IR, and then optimisations can be applied at the IR level. The IR is designed in such a way that cross-function (and hence also cross-framework) optimisations can be automatically applied.

The benefits of IR and its optimisations turn out to be significant even when using a single framework and only a single core.
… we have integrated Weld into Spark SQL, NumPy, Pandas, and TensorFlow. Without changing the user APIs of these frameworks, Weld provides speedups of up to 6x for Spark SQL, 32x for TensorFlow, and 30x for Pandas. Moreover, in applications that combine these libraries, cross-library optimization enables speedups of up to 31x.
Needless to say, a 31x speed-up is a very significant result!
High level overview
Weld provides a runtime API that allows libraries to implement parts of their computation as Weld IR fragments. Integration of Weld itself into TensorFlow, Spark SQL, Pandas, and NumPy required on the order of a few days effort and about 500 loc per framework. From that point, each individual operator ported to Weld (e.g., a Weld implementation of numpy.sum) required about 50-100 lines of code. As an example, Spark SQL already generates Java code, so all that had to be done there was to provide an alternative implementation to generated Weld.
As applications call Weld-enabled functions, the system builds a DAG of such fragments, but only executes them lazily when libraries force an evaluation. This lets the system optimize across different fragments.
Optimisations are done as Weld transformations (Weld -> Weld). A compiler backend maps the final, combined Weld IR program to efficient multi-threaded code. This backend is implemented using LLVM.
Because the Weld IR is explicitly parallel, our backend automatically implements multithreading and vectorization using Intel AVX2.
The Weld IR
The design of Weld IR dictates what workloads can run on Weld, and what optimizations can easily be applied. It supports composition and nesting so that fragments from multiple libraries can easily be combined, and explicit parallelism in its operators.
Our IR is based on parallel loops and a construct for merging results called “builders.” Parallel loops can be nested arbitrarily, which allows complex composition of functions. Within these loops, the program can update various types of builders, which are declarative data types for constructing the results in parallel (e.g. computing a sum or adding items to a list). Multiple builders can be updated in the same loop, making it easy to express optimizations such as loop fusion or tiling, which change the order of execution but produce the same result.
Here are some very basic examples of using builders to give a feel for the IR:

Weld’s loops and builders can be used to implement a wide range of programming abstractions – all of the functional operators in systems like Spark for example, as well as all of the physical operators needed for relational algebra.
As a small worked example, consider this Python code using both Pandas and Numpy:

We need Weld implementations of > for Pandas DataFrames, and sum for NumPy, which are trivially expressed as:

With this is place Weld can save one whole data scan and fuse the Pandas and NumPy loops into one. The optimised Weld program looks like this:

One limitation of the current version of the IR is that it is fully deterministic, so it cannot express asynchronous algorithms where threads race to update a result, such as Hogwild! We plan to investigate adding such primitives in a future version of the IR.
Experimental results
To test the raw speed of the code Weld generates, Weld implementations of a TPC-H workload for SQL, PageRank for graph analytics, and Word2Vec for ML were hand-written and compared against both a hand-optimized C++ version, and also an existing high-performance framework. As an example, here are the TPC-H results for four queries:
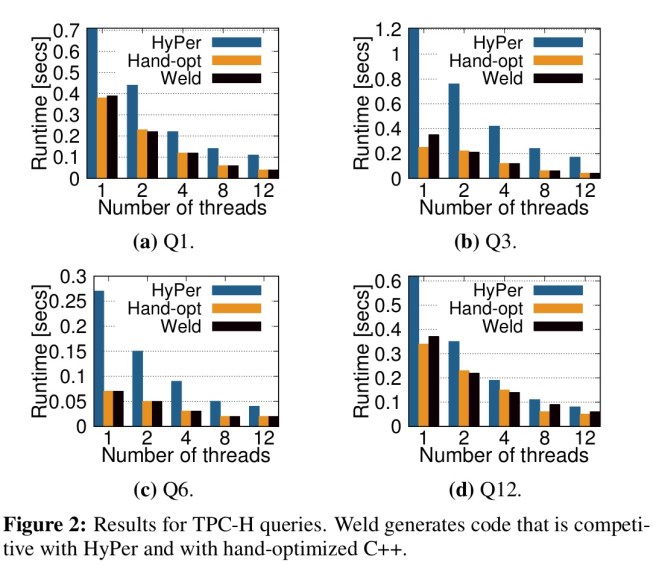
The result show that…
Weld can generate parallel code competitive with state-of-the-art systems across at least three domains.
The next stage of the evaluation was to see what benefits Weld can bring when used just with a single framework. Here are the results of using Weld with (a) TensorFlow, (b) Spark SQL, and(c) Pandas:
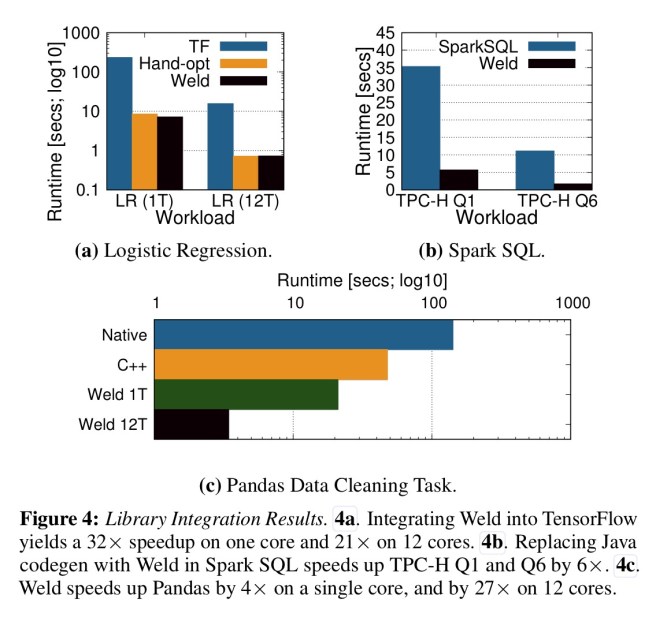
The TensorFlow application is a binary logistic classifier trained on MNIST, the Spark SQL example is running TPC-H queries, and the Pandas example is based on an online data science tutorial for cleaning a dataset of zipcodes.
Weld’s runtime API also enables a substantial optimization across libraries. We illustrate this using a Spark SQL query that calls a User-Defined Function (UDF) written in Scala, as well as a Python data science workload that combines Pandas and NumPy.

On the Spark Scala workload we see a 14x speedup. On the data science workload we see a 31x speedup even on a single core….
With multiple cores, we see a further 8x speedup over single-threaded Weld execution, for an overall 250x speedup over the Pandas baseline.
Future work for Weld includes extending the set of supported back-ends to target GPUs and FPGAs in addition to CPUs. “In many domains, these platforms have become essential for performance…”

So what exactly do numpy, pandas, spark, etc. provide once they’ve been hooked into Weld? Is they idea that you’ve cut down on the operations to re-implement to only the primitives of each library? Or is the idea to mix LLVM-generated code execution with JVM and Python bytecode execution?
My interpretation is that this would be a bit like implementing selected functions in C, only using the IR instead that would allow further optimisations. For some of the cross-framework stuff though, it would seem that you need sufficient coverage of the Weld impls to make it work.