Musketeer: all for one, one for all in data processing systems – Gog et al. 2015
For between 40-80% of the jobs submitted to MapReduce systems, you’d be better off just running them on a single machine…
It was Eurosys 2015 last week, and a great new crop of papers were presented. Gog et al. from the Cambridge Systems at Scale (CamSaS) initiative published today’s choice, ‘Musketeer’. In fact, it’s going to be tomorrow’s choice as well since there’s more good material here than I can do justice to in one write-up. Today I want to focus on the motivation section from the Musketeer paper, which sheds a lot of light on the question “what’s the best big data processing system?” Tomorrow we’ll look at Musketeer itself.
What’s the best big data processing system?
“For what?” should probably be your first question here. No-one system is universally best. The Musketeers conducted a very interesting study that looked into this:
We evaluated a range of contemporary data processing systems – Hadoop, Spark, Naiad, PowerGraph, Metis and GraphChi – under controlled and comparable conditions. We found that (i) their performance varies widely depending on the high-level workflow; (ii) no single system always out-performs all others; and (iii) almost every system performs best under some circumstances
It’s common sense that each system must have a design point, and therefore you should expect it to work best with workloads close to that design point. But it’s easy to lose sight of this in religious wars over the ‘best’ data processing system – which can often take place without any context.
Let’s assume you do have a particular workload in mind, so that we can ask the much better question: “what’s the best data processing system for this workload?”. Even then…
Choosing the “right” parallel data processing system is difficult. It requires significant expert knowledge about the programming paradigm, design goals and implementation of the many available systems.
Tomorrow we’ll see how Musketeer can help make this choice for you, and even retarget your workflow to the back-end for which it is best suited. Even if you don’t use Musketeer though, the analysis from section 2 of the paper is of interest.
Gog et al. examined makespan – the entire time to execute a workflow including not only the computation itself, but also any data loading, pre-processing, and output materialization. From this, they determine four key factors that influence system performance:
- The size of the input data. Single machine frameworks outperform distributed ones for smaller inputs.
- The structure of the data. Skew and selectivity impact I/O performance and work distribution.
- Engineering decisions made during the constructing of the data processing system itself. For example, how efficiently it can load data.
- The computation type, since specialized systems operate more efficiently.
In all systems they studied, the ultimate source and sink of data is files in HDFS.
Do you really need that fancy distributed framework?
You might recall the story from last year of awk and grep on the command-line of a single machine outperforming a Hadoop cluster by a factor of 235.
Gog et al. studied the effect on input size on framework performance. Take a look at their figure 2a, below:
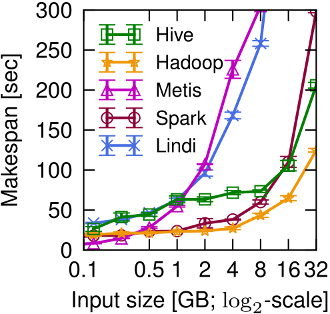
For small inputs (≤0.5GB), the Metis single-machine MapReduce system performs best. This matters, as small inputs are common in practice: 40– 80% of Cloudera customers’ MapReduce jobs and 70% of jobs in a Facebook trace have ≤ 1GB of input.
This last point bears repeating, and if I can generalize slightly: for between 40-80% of the jobs submitted to MapReduce systems, you’d be better off just running them on a single machine.
Likewise a join workflow producing 1.9GB of data runs best on a single machine. A larger join producing 29GB works best on Hadoop. See figure 2b below.
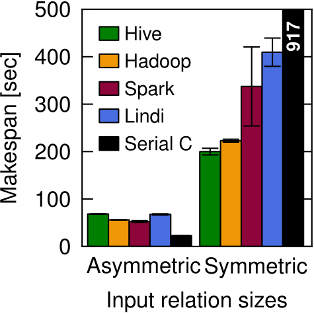
Do you really need that new shiny thing?
Well, maybe! But likewise there is no universal guarantee that e.g. Spark is better than Hadoop MR. It depends on what you’re trying to do…
Once the data size grows, Hive, Spark and Hadoop all surpass the single-machine Metis, not least since they can stream data from and to HDFS in parallel. However, since there is no data re-use in this workflow, Spark performs worse than Hadoop: it loads all data into a distributed in-memory RDD before performing the projection.
What are you optimising for?
For workflows involving iterative computations on graphs, it won’t surprise you to learn that specialized graph processing systems do well.
It is evident that graph-oriented paradigms have significant advantages for this computation: a GraphLINQ implementation running on Naiad outperforms all other systems. PowerGraph also performs very well, since its vertex-centric sharding reduces the communication overhead that dominates PageRank… However, the fastest system is not always the most efficient.
Look at figure 3a below. With smaller graphs the 100 node clusters may be the fastest, but you’re getting nowhere near a 100x speed-up for all that investment (we’re on the RHS of the Universal Scalability Law curve). If you prepared to wait just a little longer for results, you can get your answer with dramatically less compute power (also compare e.g. PowerGraph on 16 nodes with GraphChi on one).
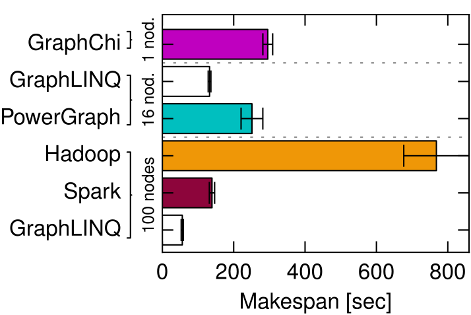
Yes, but what’s the best data processing system?
Our experiments show that the “best” system for a given workflow varies considerably. The right choice – i.e., the fastest or most efficient system – depends on the workflow, the input data size and the scale of parallelism available.
If you think a little carefully about what you’re trying to achieve – when you really need fully precise results vs. good approximations; when you really need to run on a distributed framework vs. a single machine; when you really need results quickly vs. waiting a little bit longer but being much more efficient – you can significantly improve the overall effectiveness of your data platform.
Tomorrow we’ll see how Musketeer can help to make all this more practical and manageable by enabling workflows to be written once and mapped to many systems – even combining systems within a workflow.
Postscript
The authors did something very neat with this paper – in the pdf version, every figure is actually a link to a webpage describing the experiments and data sets behind it. Really great idea, thanks!

Pretty cool paper and kudos to the authors to have web-based information.
Based on this sentence from the paper: “However, since there is no data re-use in this workflow … it loads all data into a distributed in-memory RDD before performing the projection.”
I feel there’s misunderstanding about how Spark works, which partially is our own fault in how we discussed Spark in its early days. RDD is really just an interface telling the system how to get data, similar to the volcano style database iterators. There is nothing inherent about RDD data being in-memory, or loading data in memory before a projection.
On a different note, I myself did a few “whole system” research projects (Shark, GraphX) back in the days when it was very easy to compare and conduct research, because development for mainstream projects (MapReduce, Hive, etc) mostly stagnated.
One challenge I see with “whole systems” research now is that unlike Hadoop MapReduce, Spark itself is actually advancing at a very fast pace. This makes it very challenging for papers to compare or improve. I’ve seen papers proposing newer algorithms that made certain things 50% more efficient than Spark at the time of writing, but at the time of publication Spark itself became a lot faster for that workload.
[Disclaimer: one of the Musketeer authors]
Thanks for the comments, Reynold! :)
Our explanation of the PROJECT benchmark is brief and somewhat simplified for space reasons. We ended up cutting a lot of more in-depth discussion of what we found impacted each system’s performance, both in order to restrict complexity and because feedback from readers suggested that we should get to the point about Musketeer more quickly!
In the particular PROJECT experiment, we hypothesized that RDD-related overheads might come into it. However, as you point out, there is nothing inherent in the Spark model that *necessitates* this overhead: instead, Spark can just stream the data through (although in practice, surely the current implementation makes an RDD if you process data via d = sc.textFile() -> d.map() -> d.saveAsText?).
We also observed two other factors in our small, heterogeneous test cluster (which we used for the relatively small-scale PROJECT experiment):
1) Spark’s scheduler (in v0.9, mind you) had some difficulty with many-core machines: it would either under-utilize the machine or over-commit the disk, and we struggled to find a happy equilibrium using the parallelism level and worker count configuration directives.
2) With large data sets, Spark (again, v0.9) sometimes struggled with GC’ing a very large heap. While this probably did not have a big impact on the PROJECT experiment (where we go to at most a few GB of heap size), we definitely saw it with PageRank on the Twitter graph. For a 64 GB heap, we saw GC-related stragglers and Spark workers even sometimes “failed” spuriously because they were GC’ing for over a minute. Of course, that’s far from a fundamental issue and GC performance for big data is itself of research interest (cf. our upcoming Broom work at HotOS, http://www.cl.cam.ac.uk/~ms705/pub/papers/2015-hotos-broom.pdf).
I couldn’t agree more with your point on fast-paced evolution: while we worked on Musketeer, Spark went from v0.6 to v1.3, and Naiad similarly went kept evolving “under our feet”. The evaluation in the paper captures the state of systems as of ca. summer 2014, and some of the results might differ now, while others are inherent. However, we believe that this only strengthens the case for a Musketeer-style indirection: most users won’t keep track of all these changes, but a set of domain experts (such as each system’s developers) can.
>I feel there’s misunderstanding about how Spark works, which partially is our own fault in how we discussed Spark in its early days.
Interesting point. In the context, the authors were trying to explain the poor performance of Spark relative to Hive/Hadoop for this particular workload. Given your experience with the system, I’d be interested to hear an alternative explanation which takes into account a better understanding of how the system works.
It’s hard to know for sure unless I profile it, but my guess would be garbage collection due to a large heap. Most cases where I see Spark is slower than Hadoop MapReduce is due to the overhead of GC kicking in, which is possible to tune to reduce that. However, since it is hard and a black magic, we are doing this so Spark users won’t need to worry about GC anymore:
https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html
> This last point bears repeating, and if I can generalize slightly: for between 40-80% of the jobs submitted to MapReduce systems, you’d be better off just running them on a single machine.
Indeed! You might find this an interesting reference: http://www.frankmcsherry.org/graph/scalability/cost/2015/01/15/COST.html
A version of which will appear at HotOS 2015 (https://www.usenix.org/conference/hotos15/workshop-program/presentation/mcsherry)
The high level takeaway is:
> Here are two helpful guidelines (for largely disjoint populations):
> If you are going to use a big data system for yourself, see if it is faster than your laptop.
> If you are going to build a big data system for others, see that it is faster than my laptop.
This is a great comparison and discussion!
Is the data used to benchmark available? I would love to try it on BigQuery.
If you click on any of the figures in the paper, they link to details on the datasets etc. used to generate them. See for example: http://www.cl.cam.ac.uk/research/srg/netos/musketeer/eurosys2015/fig2a.html. It looks from there like you might be able to get hold of the data soon – would be super interesting to see your results!
Woah! I’m really loving the template/theme of this blog.
It’s simple, yet effective. A lot of times it’s challenging to get that “perfect balance” between superb usability and appearance.
I must say you’ve done a very good job with this. Additionally, the blog loads super
fast for me on Firefox. Excellent Blog!