Self-driving database management systems Pavlo et al., CIDR 2017
We’ve previously seen many papers looking into how distributed and database systems technologies can support machine learning workloads. Today’s paper choice explores what happens when you do it the other way round – i.e., embed machine learning into a DBMS in order to continuously optimise its runtime performance. In the spirit of CIDR’s innovation charter it’s a directional paper with only preliminary results – but no less interesting for that. I find that format very stimulating in this case because it encourages the reader to engage with the material and ask a lot of “what if?” and “have you thought about?” questions that don’t yet have answers in the evaluation.
Tuning a modern DBMS has become a black art – it requires DBAs who are expert in the internals of the system, and often the use of tools that analyse the effects of possible changes on offline copies of the database using workload traces.
In this paper, we make the case that self-driving database systems are now achievable. We begin by discussing the key challenges with such a system. We then present the architecture of Peloton, the first DBMS that is designed for autonomous operation. We conclude with some initial results on using Peloton’s deep learning framework for workload forecasting and action deployment.
You can find PelotonDB online at http://pelotondb.io/.
What should/could a self-driving DBMS do?
At the core of the job is the need to understand an application’s workload type. For example, is it mostly an OLTP or OLAP application? OLTP workloads are best served by row-oriented layouts, and OLAP by column-oriented. HTAP (hybrid transaction-analytical processing) systems combine both within one DBMS. A self-driving DBMS should be able to automatically determine the appropriate OLTP or OLAP optimisations for different database segments.
A self-driving DBMS must also have a forecasting model that lets it predict what is about to happen, and thus prepare itself to best meet anticipated demand. The possible actions a self-driving database might take are shown in the following table. Each action has a cost to implement (change the database), and a potential benefit. These costs and benefits may themselves need to be part of some estimation model.

Finally, it must be possible for the DBMS to implement its plans of action efficiently without incurring large overheads. For example,…
… if the system is only able to apply changes once a week, then it is too difficult for it to plan how to correct itself. Hence, what is needed is a flexible, in-memory DBMS architecture that can incrementally apply optimisations with no perceptible impact to the applications during their deployment.
Peloton system architecture
To get the degree of fine-grained control over the DBMS runtime required, and to avoid e.g. the need to restart the system in order to effect changes, the authors decided to build their own DBMS. Two key design points are the use of a multi-version concurrency control mechanism than can interleave OLTP in amongst OLAP queries without blocking them, and an in-memory store manager that allows for fast execution of HTAP workloads. (The preliminary results so far are all centred around switching between row and column-oriented table layouts at runtime).
What we’re all here for though, is to understand how the ‘self-driving’ pieces fit into the architecture:
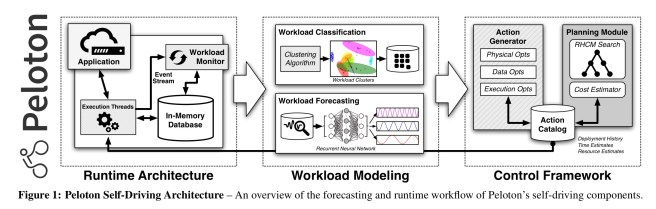
There are three major components:
- Workload classification
- Workload forecasting
- An action planning and execution engine
The workload classification component uses clustering to group queries into clusters. These clusters then become the units of forecasting. Features for clustering can include both features of the query itself, and also runtime metrics from query execution. The former have the advantage that they are stable across different optimisations which may (we hope!) impact the runtime metrics. Peleton currently uses the DBSCAN algorithm for query clustering.
The workload forecasting component contains models to predict the arrival rate of queries for each workload cluster.
After the DBMS executes a query, it tags each query with its cluster identifier and then populates a histogram that tracks the number of queries that arrive per cluster within a time period. Peloton uses this data to train the forecast models that estimate the number of queries per cluster that the application will execute in the future. The DBMS also constructs similar models for the other DBMS/OS metrics in the event stream.
Obviously we need to use deep learning for this ;). I know that you can do time series analysis with LSTMs, but I don’t know enough to understand when that approach makes sense vs more classical methods for separating periodic and underlying trends. See e.g., ‘time series decomposition‘ or even good old DFT. I bet some of The Morning Paper readers know though: if that’s you, please leave a comment to enlighten the rest of us! What I do know, is that the Peloton team chose to address the problem of learning the periodicity and repeating trends in a time-series using LSTMs. Let’s just roll with it for now…
To deal with periodicity at different levels of granularity (e.g. hourly, daily, weekly, monthly, quarterly, yearly) the authors train multiple models, each at different time horizons / interval granularities. It strikes me that fits very well with models for aggregating time-series data in blocks whereby we maintain e.g. by the minute data for several hours, and then this gets rolled up into hourly aggregates at the next level, which get rolled up into daily aggregates, and so on. The further back in time you go, the more coarse-grained the data that is retained.
Combining multiple RNNs (LSTMs) allows the DBMS to handle immediate problems where accuracy is more important as well as to accommodate longer term planning where the estimates can be broad.
The control framework continuously monitors the system performance and plans and executes optimisations to improve performance. It’s like a classical AI agent that observes its environment and makes plans to meet its goals by selecting out of a set of possible actions at each time step. This is also the domain of reinforcement learning therefore, and if we choose to go deep, of architectures such as DQNs. Peloton maintains a catalog of actions available to it, together with a history of what happened when it invoked them in the past.
[From the set of available actions] the DBMS chooses which one to deploy based on its forecasts, the current database configuration, and the objective function (latency minimisation). Control theory offers an effective methodology for tackling this problem. One particular approach, known as the receding-horizon control model (RHCM) is used to manage complex systems like self-driving cars.
The basic idea is quite straightforward. At each time step the agent looks ahead for some finite time horizon using its forecasts, and searches for a sequence of actions to minimise the objective function. It then takes only the first action in that sequence, and waits for this deployment to complete before re-planning what to do next (c.f., STRAW which we looked at a couple of weeks ago, that learns when to stick with multi-action plans, and when to replan).
Under RHCM, the planning process is modelled as a tree where each level contains every action that the DBMS can invoke at that moment. The system explores the tree by estimating the cost-benefit of actions and chooses an action sequence with the best outcome.
Forecasts are weighted by their time horizon so that nearer-in forecasts have greater weight in the cost-benefit analysis.
Initial results
The authors integrated TensorFlow inside Peleton and trained two RNNs on 52 million queries from one month of traffic for a popular site. The first model predicts the number of queries arriving over the next hour at one-minute granularity. It takes as input a 120-element vector with the arrival rates for the past two hours, and outputs a 60-element vector with predictions for the next hour. The second model uses a 24-hour horizon with one-hour granularity. It takes as input an 24-element vector for the previous day, and outputs a scalar prediction for the next day.
Using these models, we then enable the data optimization actions in Peloton where it migrates tables to different layouts based on the type of queries that access them…
The RNNs produce accurate forecasts as can be seen below:

Using these forecasts, the optimiser is able to reduce overall latency by switching layouts between daytime OLTP and night time OLAP queries.

These early results are promising: (1) RNNs accurately predict the expected arrival rate of queries. (2) hardware-accelerated training has a minor impact on the DBMS’s CPU and memory resources, and (3) the system deploys actions without slowing down the application. The next step is to validate our approach using more diverse database workloads and support for additional actions.
Machine learning for system optimisation
It’s not just tuning of DBMSs that has become a black art. One of the companies I’m involved with, Skipjaq, has been studying the opportunities to reduce latencies through automated tuning of cloud instance type, OS, JVM, and framework settings. Optimising the settings across all of those variables for a given workload is also a black art – and one that most teams simply don’t have the resources or skills to undertake. Skipjaq uses machine learning techniques to perform the optimisation and the results with customer workloads so far show that there are significant performance gains to be had for nearly all applications as a result of the process. You can find out more and even give it a test drive at skipjaq.com. Tell them I sent you ;).

we are not so aware about the self driving database management systems.this article helped us to understand about it in very easy and simple manner. thank you for the post.