Morpheus: Towards automated SLOs for enterprise clusters Jyothi et al. OSDI 2016
I’m really impressed with this paper – it covers all the bases from user studies to find out what’s really important to end users, to data-driven engineering, a sprinkling of algorithms, a pragmatic implementation being made available in open source, and of course, impactful results. If I was running a big-data cluster, I’d definitely be paying close attention! Morpheus is a cluster scheduler that optimises for user satisfaction (we don’t see that often enough as a goal!), and along the way makes up to an order-of-magnitude reduction in the number of jobs that miss their deadlines while maintaining cluster utilisation and lowering cluster footprint by 14-28%.
In this paper, we present Morpheus, a system designed to resolve the tension between predictability and utilization—that we discovered thorough analysis of cluster workloads and operator/user dynamics. Morpheus builds on three key ideas: automatically deriving SLOs and job resource models from historical data, relying on recurrent reservations and packing algorithms to enforce SLOs, and dynamic reprovisioning to mitigate inherent execution variance.
What do users of big data clusters care about?
The team gathered some very interesting insights into what goes on in (Microsoft’s ?) big data clusters by a process of:
- Analyzing execution logs from millions of jobs running on clusters with over 50K nodes
- Looking at infrastructure deployment and upgrade logs
- End user interviews, analysis of discussion threads and escalation tickets from end-users, operators, and decision makers, and
- A selection of targeted micro-benchmarks
The findings are fascinating in their own right.
Based on interviews with cluster operators and users, we isolate one observable metric which users care about: job completion by a deadline. Specifically, from analysing the escalation tickets, some users seem to form expectations such as: “95% of job X runs should complete by 5pm”. Other users are not able to specify a concrete deadline; but do state that other teams rely on the output of their job, and may need it in a timely manner.
- Over 75% of the workload is production jobs
- Users are 120x more likely to complain about performance (un)predictability than about fairness
- Over 60% of the jobs in the largest clusters are recurrent. Most of these recurring jobs are production jobs operating on continuously arriving data, hence are periodic in nature. The periods tend to be natural values (once an hour, once a day etc.).
- Manual tuning of jobs is hard: 75% of jobs are over-provisioned even at their peak. 20% of jobs are more than 10x over-provisioned!
- Users don’t change the provisioning settings for their periodic jobs beyond the initial set-up (80% of periodic jobs saw no change in their resource provisioning)
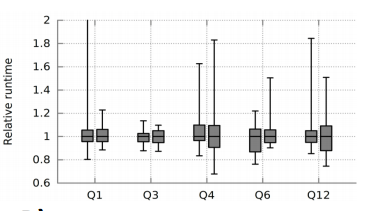
- Runtimes are unpredictable – noisy neighbours (the amount of sharing) have some impact, but even when removing common sources of inherent variability (data availability, failures, network congestion), runtime remain unpredictable (e.g. due to stragglers). The chart below shows the wide variability in runtimes of five different TPC-H queries on a 500 container system:
- Cluster hardware keeps evolving. For example over a one year period the ratio between machines of type SKU1 and machines of type SKU2 changed from 80/20 to 55/45, as well as the total number of nodes also changing.
This is notable, because even seemingly minor hardware differences can impact job runtime significantly – e.g., 40% difference in runtime on SKU1 vs SKU2 for a Spark production job.
- Jobs don’t stand still – within a one-month trace of data, 15-20% of periodic jobs had at least one large code delta (more than 10% code difference), and over 50% had at least one small delta.
Even an optimal static tuning is likely going to drift out of optimality over time.
Based on their findings, the team concluded that:
- History-based approaches can model the “normal” behaviour of a job
- Handling outliers without wasting resources requires a dynamic component that performs reprovisioning online, and
- While each source of variance can be addressed with an ad-hoc solution, providing a general-purpose line of defence is paramount.
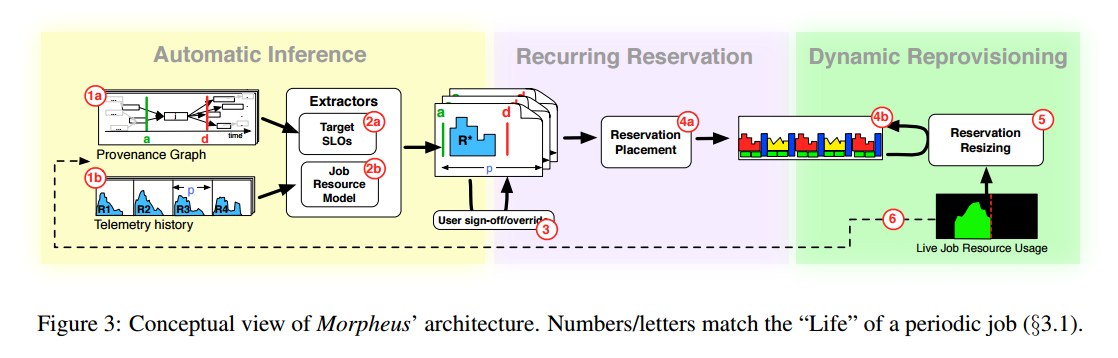
Morpheus overview
Given a job that is periodically submitted by a user (with manually provisioned resources), Morpheus quietly monitors the job over time and captures:
- a provenance graph with data dependencies and ingress/egress operations
- telemetry history in the form of resource skylines capturing resource utilisation
Following a number of successful runs of the job, an SLO inference component performs an offline analysis. Using the provenance graph it determines a deadline for completion, the SLO (Service Level Objective), and using the skylines it determines a model of the job resource demand over time.
At this point, the system is ready to take over resource provisioning for the job, but before it does so:
The user signs-off (or optionally overrides) the automatically-generated SLO and job resource model.
(Wouldn’t that be great as a user, to know that the system is going to monitor and try to honour an SLO for your jobs!).
Morpheus then uses recurring reservations for each managed job. These set aside resources over time for running the job, based on the job resource model, and each new instance of the job runs using these dedicated resources.
To address variability, a dynamic reprovisioning component monitors job progress online and adjusts the reservation in real-time to mitigate the inherent execution variability.
Job runs continue to be monitored to learn and refine the SLO and job resource model over time.
Let’s look a little more closely at a couple of the key steps
Agreeing on SLOs…
Petabytes of logs gathered daily across the production environments are processed to create a “semantically rich and compact (few TBs!) graph representation of the raw logs.”
This representation gives us a unique vantage point with nearly perfect close-world knowledge of the meaningful events in the cluster.
Periodic jobs are uncovered by looking for (templatized) job name matches, an approximate match on source-code signatures (what is an approximate match for a signature??? I’m guessing this is not a hash-based signature…), and submissions with near-constant inter-arrival time.
We say that a job has an actionable deadline if its output is consumed at an approximately fixed time, relative to the start of the period (e.g., everyday at 4pm), and if there is a non-trivial amount of slack between the job end and the deadline.
Morpheus then collects usage patterns for these jobs and determines resource skylines. It then becomes a linear programming optimisation problem to determine the best resource allocations. The cost function uses one term which penalises for over-allocation, and another term which penalises for under-allocation.
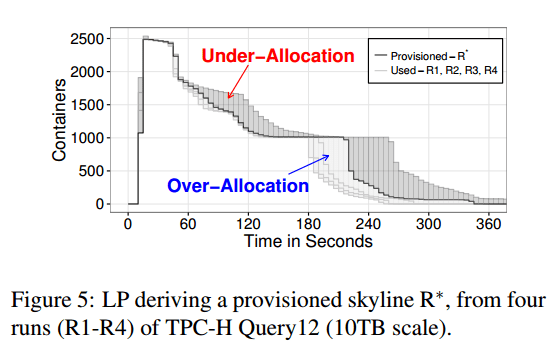
The LP has (O(N ×K)) number of variables and constraints. Our sampling granularity is typically one minute, and we keep roughly one-month worth of data. This generates less than 100K variables and constraints. A state-of-the-art solver (e.g., Gurobi, CPlex) can solve an LP of millions of variables and constraints in up to few minutes. Since we are way below the computational limit of top solvers, we obtain a solution within a few seconds for all periodic jobs in our clusters.
Make it so
With all the requirements collected, a packing algorithm called LowCost is used to match jobs to resources. LowCost allocates containers to all periodic jobs, such that their requirements are met by the deadline, and at the same time it tries to minimize waiting time for non-periodic ad-hoc jobs. The overall objective of LowCost is to minimise the maximum total allocation over time. It does so following a greedy procedure which places containers iteratively at cost-efficient positions.
While reservations can eliminate sharing-induced unpredictability, they provide little protection against inherent unpredictability arising from hard-to-control exogenous causes, such as infrastructure issues (e.g., hardware replacements (see §2), lack of isolation among tasks of multiple jobs, and framework code updates) and job-centric issues (changes in the size, skew, availability of input data, changes in code/functionalities, etc.).
These issues are dealt with by the dynamic reprovisioning algorithm (DRA). DRA continuously monitors the resource consumption of a job, compares it with the resources allocated in the reservation and ‘stretches’ the skyline of resources to accommodate a slower-than-expected job execution.
Key results
In a simulation run from the largest dataset available to the team, Morpheus was able to automatically derive SLOs for over 70% of the millions of instances of periodic jobs in the trace. (The remainder don’t have enough data – eg, they are weekly jobs and so only appear four times in the one-month trace). Compared to the current manual provisioning, Morpheus reduces worst-case SLO misses by 13x! The packing algorithm does a good job of driving utilisation at the same time, lowering the overall cluster cost.
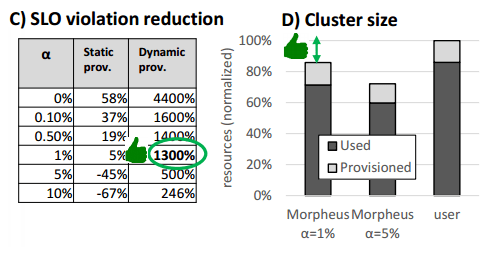
SLO extraction and packing contribute to lower the baseline cluster size by 6%. Job resource modeling (using the extracted skyline rather than user supplied provisioning) lowers cluster size by a further 16%. Combined they give a 19% reduction.
By turning on/off our dynamic reprovisioning, we can either (1) match the user utilization level and deliver 13x lower violations, or (2) match the current SLO attainment and _reduce cluster size by over 60% (since we allow more aggressive tuning of the LP, and repair underallocations dynamically).

Reblogged this on The Rhythm of My Life and commented:
My paper with Microsoft featured in the morning paper.