On purpose and by necessity: compliance under the GDPR Basin et al., FC’18
A year ago it seemed like hardly anyone in a technical role had heard of GDPR. Now it seems to be front of mind for everyone! Not surprising perhaps, as it comes into force on the 25th May this year. In today’s paper choice, Basin et al. consider how an organisation might go about establishing compliance with the law.
[The GDPR] requires not only that data is only collected after obtaining consent from the user, but also that data is collected and used only for specific purposes, and must be deleted when those purposes are no longer applicable. The GDPR spells out these requirements in its notions of purpose limitation and data minimisation, its treatment of consent, and the right to be forgotten.
- Personal data shall be collected for specified, explicit and legitimate purposes (and not further processed in a manner incompatible with them)— Article 5, §1
- Personal data shall be adequate, relevant, and limited to what is necessary in relation to the purposes…— Article 5, §1
- Consent should be given by a clear affirmative act establishing a freely given, specific, informed and unambiguous indication of the data subject’s agreement to the processing of personal data relating to him or her … when the processing has multiple purposes, consent should be given for all of them — Recital 32
In short, data must:
- be collected for a purpose,
- to which the user has consented, and
- be necessary to achieve that purpose;
- moreover the collected data must be deleted when it is no longer necessary for any purpose
As with any regulation that applies to computer systems, we are faced with two key questions: (1) How do we build a computer system in a manner guaranteeing compliance? (2) How do we analyse or audit a computer system for compliance?
In simple access control schemes, access rights are independent of context. In the world of GDPR, access control becomes relative to a purpose. I.e., it’s not just ‘can I access this data?,’ but ‘am I allowed to access this data for this purpose?’ If you equate purpose with role, then that looks a lot like RBAC. But the flows of data through an organisation can quickly become more complex.
The central idea in the paper is that business process modelling can be a powerful tool for managing purpose and compliance. I’m not sure how practical that is when your architecture looks like a death star and you’re on a journey towards 10,000 deploys a day, but you’re certainly going to need some way of tracking and managing data, consent, and purpose.
We propose exploiting the formal notion of a business process model as a bridge between a system implementation and the GDPR. In doing so, we exploit that a business process model by its very nature embodies a particular purpose, while at the same time it specifies at what points data is collected and used.
Online retailer example
Consider an online retailer where customers order online, pay with their credit cards, and receive orders by post. The retailer may also engage in marketing — targeted or otherwise — using a variety of channels. Sufficiently zoomed out, the retailer has four core processes:
- Registering customers: customers sign up and provide email, mailing address and credit card information. (Best not to store credit card information unless you really have to of course, and typically the sign-up would be deferred until the customer’s first checkout, but let’s roll with it… )
- Purchase: a registered customer pays using their recorded credit card number, and the retailer sends the product and invoice.
- Mass marketing: customers’ email and/or physical addresses are used to send otherwise untargeted advertising.
- Targeted marketing: customers’ email and/or physical addresses are used to send individually targeted advertisements based on past purchase history
You can lay these out in a high-level BPMN diagram, with one pool for each process (containing a mixture of human and automated process steps).
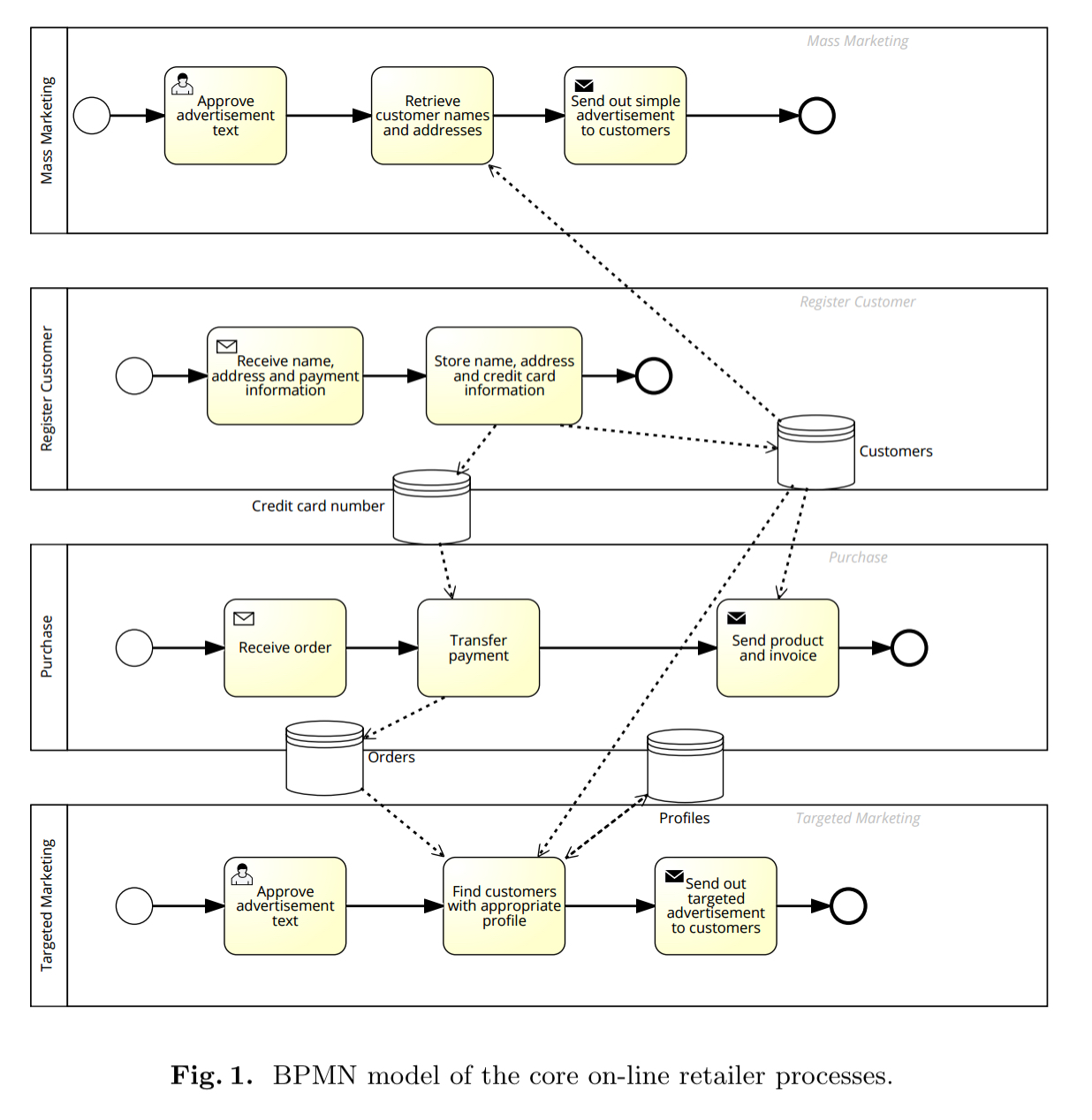
Here the assumption is that a process is associated with a purpose: the purchase process (purpose); the mass marketing process (purpose); the customer satisfaction evaluation process (purpose); and so on.
Interacting processes
In practice a company may collect data about customers in one process and use that data in another… This disconnect mirrors a challenge faced by many companies: whereas the individual processes within a company are usually well-understood by the staff undertaking them, including the interfaces to other processes, the global picture of all processes in the company is rarely well understood. But the GDPR requires such a global understanding: data collected in one process may migrate to other processes, and end-user consent is required for all involved processes.
I take a somewhat different viewpoint here: for many organisations, I contend that an approach requiring a complete, accurate, up-to-date, global understanding of all processes and data flows is probably doomed to failure, as this is an impossible task! And yet we can’t escape the challenges the authors (and the regulations) place before us. My personal sense is that we need to track the provenance of data as it flows through an organisation, including proof of consent and the purposes for which consent was given, and then match the purpose of a process against that consent record. (Having the provenance flow with the data allows for local decisions, rather than requiring a centralised master plan).
Regardless of how you do it, you are at some point going to end up with a collection of business processes and a set of data classes. You’ll need to know which data is collected by which processes, and which data is used by which processes (i.e., for which purposes). The data production (collection) and usage relations can be used to derive the user consents that are needed.
Instead of the full-blown BPMN model, you can represent the essential information in a high level inter-process diagram which hides the internal details of the processes:
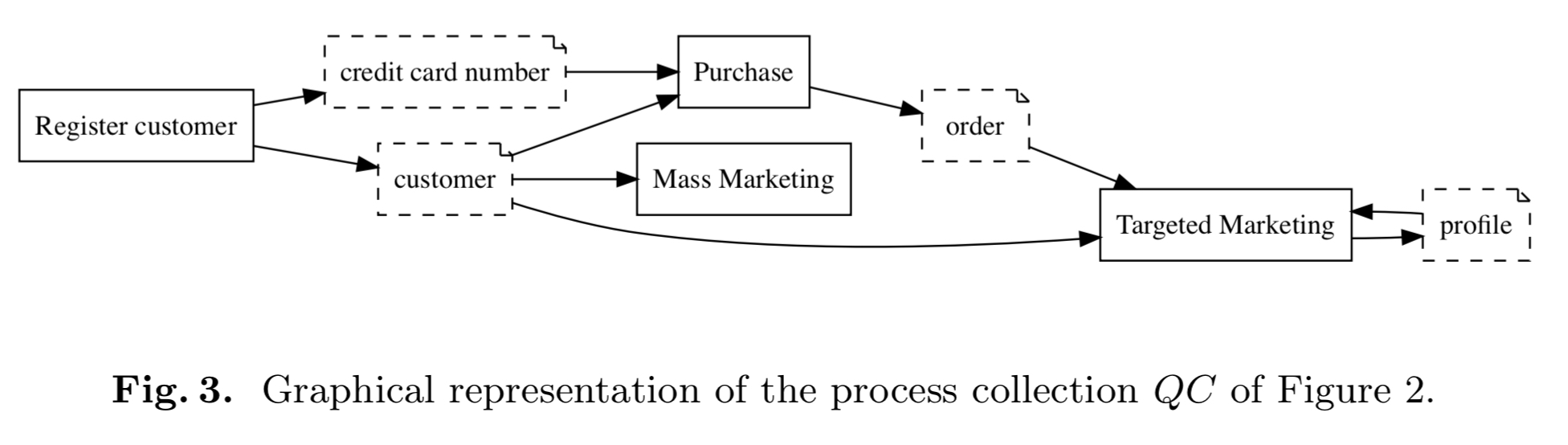
Establishing GDPR compliance
Given such a top level set of business processes/purposes, then demonstrating compliance involves:
- showing that the processes as implemented collect and use data as specified by the process definitions and privacy policy
- showing that the processes follow the GDPR, for example, by deleting data as appropriate
- showing that the privacy policy conforms to the GDPR. For example, it does not make vague statements about the purposes for which data will be used.
(Aside: maybe this helps a little bit, but I’m not sure it really helps a whole lot. It’s not much deeper than simply saying, “you’re compliant if you have a compliant policy and you follow it correctly.”)
Given the usage relation between data and processes (purposes), then the consent statement can take the form “we collect 





Furthermore the model can show us if there is personal data which is collected but not used by any process: “such data is clearly unnecessary, violating data minimisation.”
Third parties
An important area for future work concerns data transfers to third parties. The GDPR has precise rules about who may transfer data to other parties, when these transfers can occur, and under what circumstances other parties can or must delete, produce, or store data. Naturally this opens up questions about audits and compliance similar to the ones addressed in this paper.
Discussion
As I indicated earlier in this post, I’m personally not convinced that centralised business process mapping is going to be the answer here. Nevertheless, the paper sets out nicely the concerns relating to processes, data, consent, and purpose and provides a framework for thinking about them. For more GDPR related material on The Morning Paper, see ‘European Union regulations on algorithmic decision making and a right to explanation’ and ‘Ground: A data context service.’

A large piece for organisations to come to terms with, is providing the ability for an end user to create, manage and revoke what are in essence access control policies. Traditionally this has been done server side by app or systems administrators. Mapping business logic into access management logic. Newer authorization approaches such as OAuth2 and UMA (User Managed Access) will see successful application here as they empower the end user to manage access control and consent themselves.
Completely agree with Simon’s comment. A data exchange needs to be established that allows dynamic policy enforcement and decouples data access and controls from the systems/apps. I’ve written a similar blog on the subject: https://www.immuta.com/data-policies-shouldnt-be-snowflakes/
Also, hidden is the challenge of enabling context switching (e.g. “which data is used by which processes”). While this does sound like RBAC/ABAC, identity management systems do not allow rapid self-service updating (context switching); typical for a user to do multiple times a day. My company, Immuta, is tackling this problem through “analytical projects” with associated purpose restrictions in conjunction with the data exchange mentioned above.
Thanks for this article! I am glad to see that the information is readable and understandable. It is demonstrated in a very nice way to regards in establishing GDPR compliance and showing different kind of processes.
Thanks for this article! I am glad to see that the information is readable and understandable. It is demonstrated in a very nice way to regards in establishing GDPR compliance and showing different kind of processes.
https://www.ndcmanagement.co.uk/