European Union regulations on algorithmic decision-making and a “right to explanation” Goodman & Flaxman, 2016
In just over a year, the General Data Protection Regulation (GDPR) becomes law in European member states. This paper focuses on just one particular aspect of the new law, article 22, as it relates to profiling, non-discrimination, and the right to an explanation.
Article 22: Automated individual decision-making, including profiling, potentially prohibits a wide swath of algorithms currently in use in, e.g., recommendation systems, credit and insurance risk assessments, computational advertising, and social networks. This raises important issues that are of particular concern to the machine learning community. In its current form, the GDPR’s requirements could require a complete overhaul of standard and widely used algorithmic techniques.

Profiling has a very inclusive definition, being anything “aimed at analysing or predicting aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behaviour, location, or movements.” Underlying this is the right to non-discrimination.
Non-discrimination
The use of algorithmic profiling for the allocation of resources is, in a certain sense, inherently discriminatory: profiling takes place when data subjects are grouped in categories according to various variables, and decisions are made on the basis of subjects falling within so-defined groups. It is thus not surprising that concerns over discrimination have begun to take root in discussion over the ethics of big data.
Personal data is any information relating to an identified or identifiable natural person. Sensitive personal data includes “personal data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade-union membership, and the processing of genetic data, biometric data for the purpose of uniquely identifying a natural person, data concerning health or data concerning a natural person’s sex life or sexual orientation…” Profiling using personal data is permitted when explicit consent is obtained, it is deemed necessary for the contract between a subject and a data controller, and suitable measures are in place to safeguard the data subject’s rights and freedoms. However, such profiling is not permitted if it involves sensitive data.
Goodman and Flaxman discuss two possible interpretations of the prohibition on the use of sensitive data in profiling. The minimal interpretation says that it refers only to cases where an algorithm makes explicit direct use of sensitive data.
However, it is widely acknowledged that simply removing certain variables from a model does not ensure predictions that are, in effect, uncorrelated to those variables. For example, if a certain geographic region has a high number of low income or minority residents, an algorithm that employs geographic data to determine loan eligibility is likely to produce results that are, in effect, informed by race and income.
(On this point, I recently read and enjoyed “Weapons of Math Destruction” by Cathy O’Neil – with thanks to Daniel Bryant for the recommendation).
A second maximal interpretation is therefore possible in which decisions based on sensitive data extend to those using variables correlated with sensitive data. The difficulty here is that correlations can be very difficult to detect.
The link between geography and income may be obvious, but less obvious correlations – say between IP address and race – are likely to exist within large enough datasets and could lead to discriminatory effects… With sufficiently large data sets, the task of exhaustively identifying and excluding data features correlated with “sensitive categories” a priori may be impossible. Companies may also be reluctant to exclude certain covariates – web-browsing patterns are a very good predictor for various recommendation systems, but they are also correlated with sensitive categories.
In another example of ‘bias in, bias out’, Goodman and Flaxman provide a thought-provoking example whereby purging variables from the dataset still leaves open a door for unintentional discrimination. They call this uncertainty bias, and it arises under two conditions:
- One group is underrepresented in the sample, so there is more uncertainty associated with predictions about that group.
- The algorithm is risk averse, so it will ceteris paribus prefer to make decisions about which it is more confident (i.e., those with smaller confidence intervals.
Here’s a concrete example showing how biased decisions can emerge under such conditions:
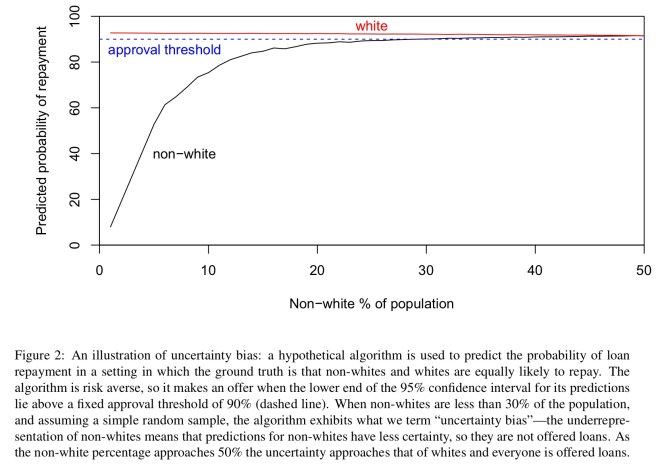
A classifier that genuinely had ‘white’ and ‘non-white’ categories would definitely fall under all interpretations of sensitive data. However in practice a classifier will most likely use complicated combinations of multiple categories (occupation, location, consumption patterns, etc.), and any rare combinations will have very few observations.
The complexity and multifaceted nature of algorithmic discrimination suggests that appropriate solutions will require an understanding of how it arises in practice. This highlights the need for human-intelligible explanations of algorithmic decision making.
The right to an explanation
When profiling takes place, a data subject has the right to “meaningful information about the logic involved.” In “How the machine thinks: understanding opacity in machine learning algorithms” Burrell outlines three barriers to transparency:
- Intentional concealment on the part of corporations or other institutions, where decision making procedures are kept from public scrutiny
- Gaps in technical literacy which mean that, for most people, simply having access to underlying code is insufficient
- A “mismatch between the mathematical optimization in high-dimensionality characteristic of machine learning and the demands of human-scale reasoning and styles of interpretation.”
The first barrier is addressed by the requirement for information to be made available to the data subject. For the second barrier, the GDPR requires that communication with data subjects is in a “concise, intelligible, and easily accessible form” (emphasis mine). The third barrier is mostly a function of algorithmic selection and design (though see e.g. “Why should I trust you? Explaining the predictions of any classifier” for a system that attempts to explain classifier results ex post facto).
Putting aside any barriers arising from technical fluency, and also ignoring the importance of training the model, it stands to reason that an algorithm can only be explained if the trained model can be articulated and understood by a human. It is reasonable to suppose that any adequate explanation would, at a minimum, provide an account of how input features relate to predictions, allowing one to answer questions such as: Is the model more or less likely to recommend a loan if the applicant is a minority Which features play the largest role in prediction?
A description of your network architecture and the values of all of the parameters is unlikely to cut it.
The last word
Above all else, the GDPR is a vital acknowledgement that, when algorithms are deployed in society, few if any decisions are purely “technical”. Rather, the ethical design of algorithms requires coordination between technical and philosophical resources of the highest caliber. A start has been made, but there is far to go.

It is not easy to design or train an effective algorithm, and many things can go wrong as discussed. Because of the complexity of such systems, I highly doubt such legal measures would be effective, as there is plenty of plausible denialability, fudging and obfuscating.
On the other hand, I would recommend looking how designers of such algorithms lose (popularity, marketshare, revenue) to competitors who are better tackling those problems. I don’t expect a silver bullet, but rather the continuous pressure to improve.
This is one of those laws that sounds good in theory, but the practicality is very very messy.
http://shape-of-code.coding-guidelines.com/2016/12/21/is-sorting-a-list-of-names-racial-discrimination/
I agree, and that’s a great example. I started out by saying “suppose this was a requirements doc, what would I have to do” – and the more I look into it the more confusing it gets!
Called it. https://considerforexample.com/big-data-is-coming-and-its-going-to-get-ugly/