How good are query optimizers, really? Leis et al., VLBD 2015
Last week we looked at cardinality estimation using index-based sampling, evaluated using the Join Order Benchmark. Today’s choice is the paper that introduces the Join Order Benchmark (JOB) itself. It’s a great evaluation paper, and along the way we’ll learn a lot about mainstream query optimisers. The evaluated databases are PostgresQL, HyPer, and three commercial databases named ‘DBMS A’, B, and C. We don’t know what those databases are, but if I had to make an educated guess I’d say they’re likely to be SQLServer, DB/2, and Oracle (in some order) based on a few hints scattered through the paper.
The goal of this paper is to investigate the contribution of all relevant query optimizer components to end-to-end query performance in a realistic setting.
The heart of the paper is an investigation into the performance of industrial-strength cardinality estimators: the authors show that cardinality estimation is the most important factor in producing good query plans. Cost models (that consume those estimates) are also important, but not as significant. Finally, and perhaps unsurprisingly, the more query plans a DBMS considers, the better the overall result.
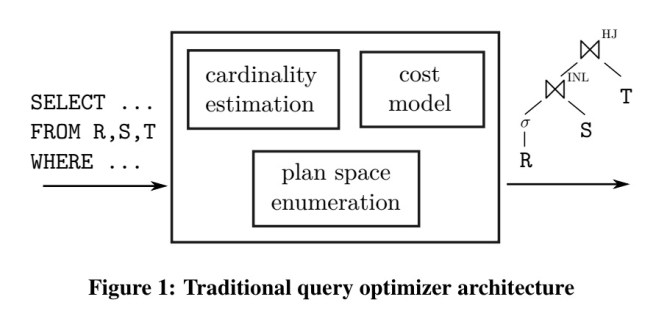
PostgreSQL optimiser
For background, let’s start out by looking at how the PostgreSQL query optimizer works.
- Cardinalities of base tables are estimated using histograms (quantile statistics), most common values with their frequencies, and domain cardinalities (distinct value counts). These per-attribute statistics are computed by the analyze command using a sample of the relation. Join sizes are estimated using:
|T1 ⋈x=y T2| = (|T1||T2|) / max(dom(x),dom(y))
- Join orders, including bushy trees but excluding trees with cross products, are enumerated using dynamic programming.
- The cost model used to determine which plan is cheapest is comprised of over 4000 lines of C code and takes into account many subtle factors. At the core, it combines CPU and I/O costs with certain weights. “Specifically, the cost of an operator is defined as a weighted sum of the number of accessed disk pages (both sequential and random) and the amount of data processed in memory.” Setting the weights of those cost variables is a dark art.
The Join Order Benchmark
Many research papers on query processing and optimization use standard benchmarks like TPC-H, TPC-DS, or the Star Schema Benchmark (SSB)… we argue they are not good benchmarks for the cardinality estimation component of query optimizers. The reason is that in order to easily be able to scale the benchmark data, the data generators are using the very same simplifying assumptions (uniformity, independence, principle of inclusion) that query optimizers make.
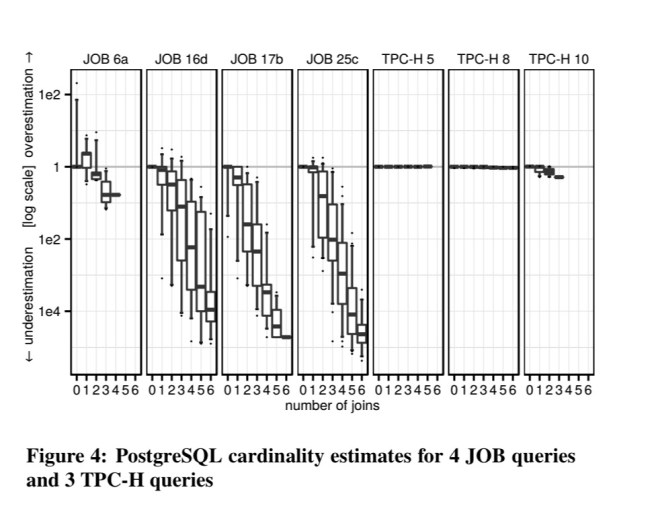
To reinforce the point, take a look at the cardinality estimation errors in PostgreSQL for four representative queries from JOB vs three from TPC-H (note the log scale, and significant underestimation on ‘real data’ cardinalities):
The Join Order Benchmark is based on the Internet Movie Data Base (IMDB). “Like most real-world data sets IMDB is full of correlations and non-uniform data distributions, and is therefore much more challenging than most synthetic data sets.”
JOB consists of a total of 113 queries over IMDB, with between 3 and 16 joins per query and an average of 8. The queries all answer questions that may reasonably have been asked by a movie enthusiast.
For cardinality estimators the queries are challenging due to the significant number of joins and the correlations contained in the data set. However, we did not try to “trick” the query optimizer, e.g., by picking attributes with extreme correlations.
The JOB query set is available online at http://www-db.in.tum.de/˜leis/qo/job.tgz.
All experiments are done using PostgreSQL in a system with 64GB of RAM, so the full dataset fits in memory.
Cardinality estimation
Cardinality estimates are the most important ingredient for finding a good query plan. Even exhaustive join order enumeration and a perfectly accurate cost model are worthless unless the cardinality estimates are (roughly) correct. It is well known, however, that cardinality estimates are sometimes wrong by orders of magnitude, and that such errors are usually the reason for slow queries.
Just looking at base table selection size estimates, the following table shows the factor (q-error) by which table size estimates are off in each of the five databases under study:
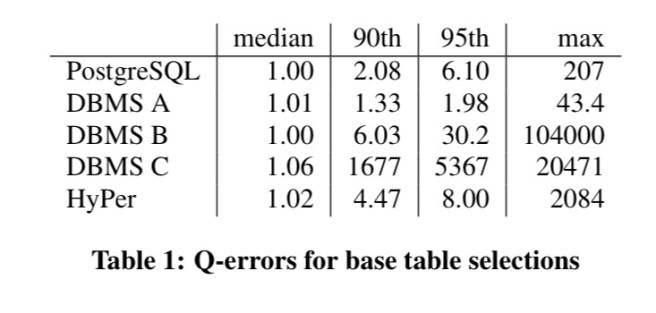
The two dbs using a form of sampling (DBMS A and HyPer) have the largest errors when the selectivity of the query is very low (e.g., 10-5 or 10-6). At this point they seem to fall back onto ‘magic constants.’ The estimates of the systems using per-attribute histograms tend to be worse.
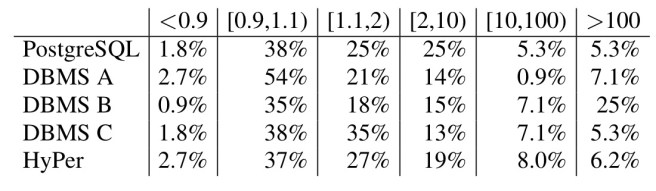
When it comes to cardinality estimation for join results (intermediate results) we see very significant errors. The figure below uses a log scale, and shows underestimation by up to a factor of 108 and over estimation by up to a factor of 104.
…the errors grow exponentially as the number of joins increases. For PostgreSQL 16% of the estimates for 1 join are wrong by a factor of 10 or more. This percentage increases to 32% with 2 joins, and to 52% with 3 joins… Another striking observation is that all tested systems – though DBMS A to a lesser degree – tend to systematically underestimate the results sizes of queries with multiple joins.
None of the tested systems could detect cross-join correlations (example: actors born in Paris are more likely to star in French movies).
Impact of cardinality estimations on query runtimes
To assess the impact of cardinality misestimation on query performance the authors injected the estimates obtained from the different systems into PostgreSQL and executed the resulting query plans. For comparison, the true cardinalities were also injected.
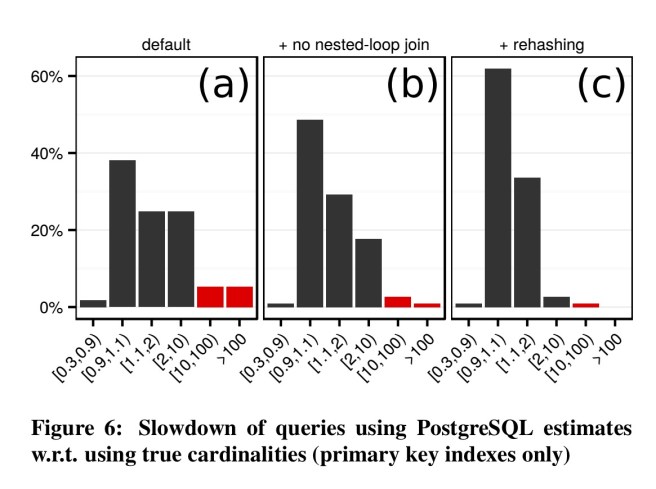
Starting out using indices on primary keys only, we see the following relative performance as compared to the optimum plan:
For DBMS A, 75% of queries are within 2x of the plan generated using the true cardinalities, for DBMS B only 53% are…
Unfortunately, all estimators occasionally lead to plans that take an unreasonable time and lead to a timeout.
The queries that timed out tended to have one thing in common: the PostgreSQL optimizer deciding to use a nested loop join (without an index lookup) due to a very low cardinality estimate.
PostgreSQL will always prefer the nested-loop algorithm even if there is a equality join predicate, which allows one to use hashing. Of course, given the O(n\2\) complexity of nested-loop join and O(n) complexity of hash join, and given the fact that underestimates are quite frequent, this decision is extremely risky.
The potential performance benefit even if we do guess right is pretty small. The authors therefore disabled non-index based nested-loop joins for all following experiments, which eliminated timeouts. With this enhancement, and with a change to resize hash tables at runtime (included in PostgreSQL v9.5) based on the number of rows actually stored in a hash table, the performance of most queries becomes close to the one obtained using the true cardinality estimates. This is mostly due to the lack of foreign key indices, so that most large fact tables need to fully scanned and these costs dominate.
When adding foreign key indices, the relative performance of the queries is significantly worse (see (b) below) – 40% of queries are slower by a factor of 2:
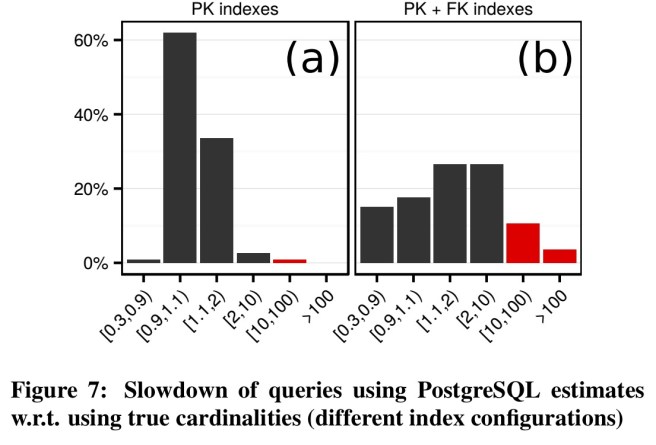
Note that these results do not mean that adding more indexes decreases performance (although this can occasionally happen). Indeed, overall performance generally increases significantly, but the more indexes are available the harder the job of the query optimizer becomes.
Cost models
The cost models guides the selection of plans from the search space. Plot (a) below shows the correlation between the cost and runtime of PostgreSQL queries when using cardinality estimates, and (b) shows the correlation using true cardinalities.
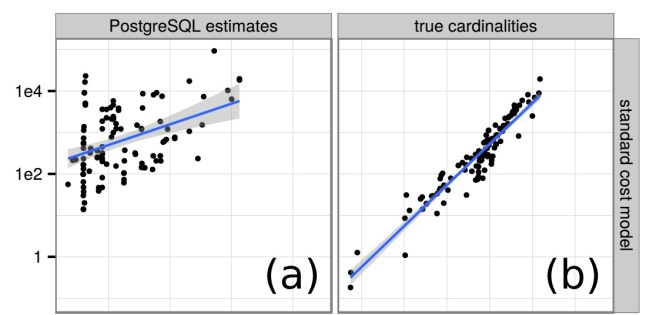
The predicted cost of a query correlates with its runtime in both scenarios. Poor cardinality estimates, however, lead to a large number of outliers and a very wide standard error.
Recall that the default PostgreSQL cost model has parameters for both CPU costs and I/O costs. When data sets fit entirely into main memory though, the relative costs of I/O vs CPU processing is too high. To narrow the gap, the authors multiplied the CPU cost weight by 50. The results are shown in (c) and (d) below – again, for cardinality estimations and true cardinalities respectively.
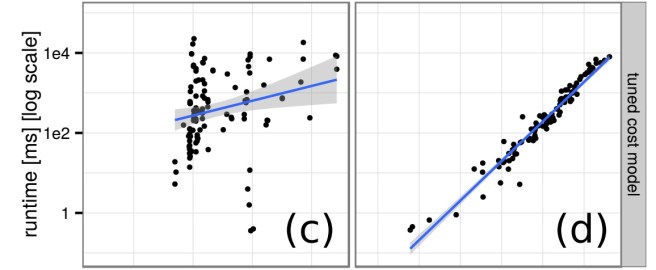
Finally, replacing the PostgreSQL cost optimizer with a very simple one that just counts the number of tuples passing through each operator. Using the true cardinalities, even this cost function is able to fairly accurately predict the true cardinalities.
In terms of the geometric mean over all queries, our tuned cost model yields 41% faster runtimes than the standard PostgreSQL model, but even a simple cost function makes queries 34% faster than the built-in cost function. This improvement is not insignificant, but on the other hand it is dwarfed by the improvement in query runtime observed when we replace estimated cardinalities with the real ones.
Cost models do matter, but accurate cardinality estimation matters much more!

DB2 not db/2
Query optimizer is a critical DBMS component that analyzes SQL queries and determines efficient execution mechanism.And it generates one or more query plans so it interns helps in optimising the sql queries.