“Why Should I Trust You? Explaining the Predictions of Any Classifier Ribeiro et al., KDD 2016
You’ve trained a classifier and it’s performing well on the validation set – but does the model exhibit sound judgement or is it making decisions based on spurious criteria? Can we trust the model in the real world? And can we trust a prediction (classification) it makes well enough to act on it? Can we explain why the model made the decision it did, even if the inner workings of the model are not easily understandable by humans? These are the questions that Ribeiro et al. pose in this paper, and they answer them by building LIME – an algorithm to explain the predictions of any classifier, and SP-LIME, a method for building trust in the predictions of a model overall. Another really nice result is that by explaining to a human how the model made a certain prediction, the human is able to give feedback on whether the reasoning is ‘sound’ and suggest features to remove from the model – this leads to classifiers that generalize much better to real world data.
Consider two classifiers (Algorithm 1 and Algorithm 2 in the figure below) both trained to determine whether a document is about Christianity or atheism. Algorithm 2 performs much better in hold-out tests, but when we see why it is making its decisions, we realise it is actually much worse…

Magenta words are those contributing to the atheism class, green for Christianity. The second algorithm is basing its decision on “Posting”, “Host”, “Re” and “nntp” – words that have no connection to either Christianity or atheism, but happen to feature heavily in the headers of newsgroup postings about atheism in the training set.
What makes a good explanation?
It must be easily understandable by a human!
For example, if hundreds or thousands of features significantly contribute to a prediction, it is not reasonable to expect any user to comprehend why the prediction was made, even if individual weights can be inspected.
And it must meaningfully connect input variables to the response:
..which is not necessarily tue of the features used by the model, and thus the “input variables” in the explanation may need to be different than the features.
Furthermore, an explanation must have local fidelity: it should correspond to how the model behaves in the vicinity of the instance being predicted.
The ideal explainer, should also be able to explain any model, and thus be model-agnostic.
A key insight – local interpretation
Creating a globally faithful interpreter of a model’s decisions might require a complete description of the model itself. But to explain an individual decision we only need to understand how it behaves in a small local region. The idea reminds me a little bit of differentiation – overall the shape of the curve may be very complex, but if we look at just a small part we can figure out the gradient in that region.
Here’s a toy example from the paper – the true decision boundary in the model is represented by the blue/pink background. In the immediate vicinity of the decision (the bold red cross) though we can learn a much simpler explanation that is locally faithful even if not globally faithful.
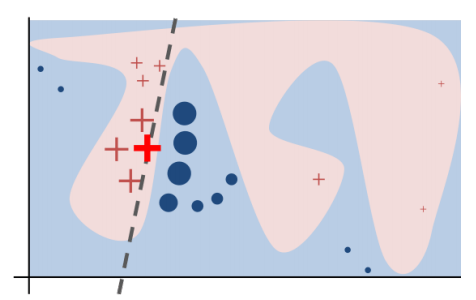
The LIME algorithm produces Local Interpretable Model-agnostic Explanations.
The overall goal of LIME is to identify an interpretable model over the interpretable representation that is locally faithful to the classifier.
For text classification, an interpretable representation could be a vector indicating the presence or absence of a word, even though the classifier may use more complex word embeddings. For image classification an interpretable representation might be an binary vector indicating the ‘presence’ or ‘absence’ of a contiguous patch of similar pixels.
LIME works by drawing samples in the vicinity of the input to be explained and learning a linear classifier using locally weighted square loss, with a limit K set on the number of interpretable features.
Since [the algorithm] produces an explanation for an individual prediction, its complexity does not depend on the size of the dataset, but instead on time to compute f(x) [a model prediction] and on the number of samples N. In practice, explaining random forests with 1000 trees using scikit-learn on a laptop with N = 5000 takes under 3 seconds without any optimizations such as using gpus or parallelization. Explaining each prediction of the Inception network for image classification takes around 10 minutes.

From local explanation to model trust
The central idea here is that if we understand and trust the reasoning behind an individual prediction, and we repeat this process for a number of predictions that give good coverage of the input space, then we can start to build global trust in the model itself.
We propose to give a global understanding of the model by explaining a set of individual instances. This approach is still model agnostic, and is complementary to computing summary statistics such as held-out accuracy. Even though explanations of multiple instances can be insightful, these instances need to be selected judiciously, since users may not have the time to examine a large number of explanations. We represent the time/patience that humans have by a budget B that denotes the number of explanations they are willing to look at in order to understand a model. Given a set of instances X, we define the pick step as the task of selecting B instances for the user to inspect.
Examining the instances X, we know the features that are locally important in making the prediction at X. Features that are locally important for many instances are globally important. Instances B are picked so as to cover the globally important features first, and to avoid redundancy in explanation between them.
With a little help from my friends
Using human subjects recruited via Amazon Mechanical Turk – by no means machine learning experts, but with a basic knowledge of religion – the team provided explanations for the predictions of two different models classifying documents as atheist or Christian and asked the subjects which would generalize better (perform the best in the real world). Using LIME coupled with the mechanism just described to create representative instances, the human subjects were able to choose the correct model 89% of the time.
A second experiment asked Amazon Mechanical Turk users to identify which words from the explanations should be removed from subsequent training, for the worst classifier.
If one notes that a classifier is untrustworthy, a common task in machine learning is feature engineering, i.e. modifying the set of features and retraining in order to improve generalization. Explanations can aid in this process by presenting the important features, particularly for removing features that the users feel do not generalize.
The users are not ML experts, and don’t know anything about the dataset. Starting with 10 users, 10 classifiers are trained (one for each subject, with their suggested words removed). These are presented to five users each, resulting in another 50 classifiers. Each of these are presented to five users, giving 250 final models.
It is clear… that the crowd workers are able to improve the model by removing features they deem unimportant for the task… Each subject took an average of 3.6 minutes per round of cleaning, resulting in just under 11 minutes to produce a classifier that generalizes much better to real world data.
High agreement among users on the words to be removed indicated that users are converging to similar correct models.. “This evaluation is an example of how explanations make it easy to improve an untrustworthy classifier – in this case easy enough that machine learning knowledge is not required.”

Reblogged this on Pradnya Chavan and commented:
This is a very interesting approach and partly answers universal question “Can we trust predictive model”. Sometime we see really weird results. As data increases understanding classifier becomes more difficult. I always felt building correct data set is very important which is a data prep stage. This approach taps into local feature extraction.