Texture Networks: Feed-forward synthesis of textures and stylized images Ulyanov et al., arXiv, March 2016
During the summer break I mostly stayed away from news feeds and twitter, which induces terrible FOMO (Fear Of Missing Out) to start with. What great research was published / discussed that I missed? Was there a major industry announcement I’m completely ignorant of? One thing I’m glad I didn’t miss was the Prisma app that produces quite beautiful stylized versions of photos from your smartphone. It’s a great example of deep technology behind a simple interface, and also of the rapid packaging and exploitation of research results – today’s choice is the paper describing the technology breakthrough that makes Prisma possible, and it was released to arXiv in March 2016. The source code and models described in the paper can also be found on GitHub.
Gatys et al. recently (2015) showed that deep networks can generate beautiful textures and stylized images from a single texture example. If you want to style a lot of images though (to provide styling-as-a-service for example), you’ll find that their technique is slow and uses a lot of memory. To generate images of equivalent quality, an implementation of Gatys et al. required about 10 seconds and 1.1GB of memory, whereas the approach described by Ulyanov et al. in this paper requires about 20ms and only 170MB of memory. Significantly faster and cheaper therefore, and although the algorithm doesn’t quite match the results of Gatys et al. for all images, it’s still very good.
Just in case you haven’t seen it, here are some examples. First, generating textures in the style of sample image:

And combining a style image with a content image:

If you download the app, you can play with examples using your own photos.
One of the possibilities I’m personally excited about is the opportunities the image creation speed opens up for applying the technique to movies. I like the images, but when I saw the movies created by Ruder et al. using an extension of the Gatys technique I was really blown away [paper,explanation and video]. Update: I just learned about the Artisto app that does this for you!
High-level approach
In general, one may look at the process of generating an image x as the problem of drawing a sample from a certain distribution p(x). In texture synthesis, the distribution is induced by an example texture instance x0 such that we can write x ~ p(x|x0). In style transfer, the distributed is induced by an image x0 representative of the visual style (e.g. an impressionist painting) and a second image x1 representative of the visual content (e.g. a boat), such that x ~ p(x|x0,x1).
Gatys et al. cast this as an optimisation problem looking to minimise the difference between certain image statistics of the generated image, and the statistics of the example image(s). They use an iterative optimisation procedure with back propagation to gradually change the values of the pixels in the generated image until the desired statistics are achieved.
In contrast, in the texture networks approach a feed-forward generation network produces the image, which requires only a single evaluation of the network and does not incur in the cost of backpropagation.
A separate generator network is trained for each texture or style and, once trained, it can synthesize an arbitrary number of images of arbitrary size in an efficient feed-forward manner.
The loss function used in training the generator network is derived from Gatys et al. and compares image statistics extracted from a fixed pre-trained descriptor CNN. This is used to measure the mismatch between the prototype texture and the generated image. The texture loss function compares feature activations across all spatial locations. A similar content loss function compares feature activations at corresponding spatial locations, and therefore preserves spatial information.
Analogously to Gatys et al. we use the texture loss alone when training a generator network for texture synthesis, and we use a weighted combination of the texture loss and the content loss when training a generator network for stylization.
Textures
A texture generator network is trained to transform a noise vector sampled from a certain distribution into texture samples that match, according to the texture loss function, a certain prototype texture x0, a three colour channel tensor.
We experimented with several architectures for the generator network g… we found that multi-scale architectures result in images with small texture loss and better perceptual quality while using fewer parameters and training faster. […] Each random noise tensor is first processed by a sequence of convolutional and non-linear activation layers, then upsampled by a factor of two, and finally concatenated as additional feature channels to the partially processed tensor from the scale below.
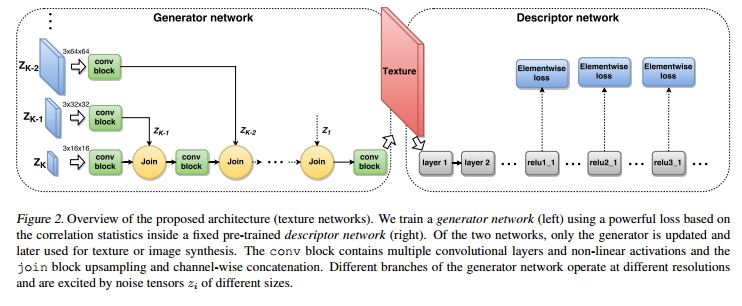
(Click on image for larger view).
Each convolutional block contains three convolutional layers containing respectively 3×3, 3×3, and 1×1 filters applied using circular convolution to remove boundary effects. Each convolutional layer is followed by a ReLU activation layer.
When learning using stochastic gradient descent each iteration draws a mini-batch of noise vectors, performs forward evaluation of the generator network to obtain the corresponding images, and computes the loss vs x0.
… After that, the gradient of the texture loss with respect to the generator network parameters θ is computed using backpropagation, and the gradient is used to update the parameters.
Styling
For stylized image generator networks the network is modified to take as input in addition to the noise vector z , the image y to which the noise should be applied.
The generator network is then trained to output an image x that is close in content to y and in texture/style to a reference texture x0.
The architecture is the same as that used for texture synthesis, _with the important difference that the noise tensors at the K scales are concatenated (as additional feature channels) with downsampled versions of the input image y. The learning objective is to minimize the combination of the content and texture loss.
In practice, we found that learning is surprisingly resilient to overfitting and that it suffices to approximate the distribution on natural images with a very small pool of images (e.g 16).
Broader applicability
The success of this approach highlights the suitability of feed-forward networks for complex data generation and for solving complex tasks in general. The key to this success is the use of complex loss functions that involve different feed-forward architectures serving as “experts” assessing the performance of the feed-forward generator.

5 thoughts on “Texture networks: feed-forward synthesis of textures and stylized images”
Comments are closed.