The measure and mismeasure of fairness: a critical review of fair machine learning, Corbett-Davies & Goel, arXiv 2018
With many thanks to Ben Fried and the ACM Queue editorial board for the paper recommendation.
We’ve visited the topic of fairness in the context of machine learning several times on The Morning Paper (see e.g. [1]1, [2]2, [3]3, [4]4). I’m still picking up new insights every time I revisit the topic though, and today’s paper choice is no exception.
In 1911 Russell & Whitehead published Principia Mathematica, with the goal of providing a solid foundation for all of mathematics. In 1931 Gödel’s Incompleteness Theorem shattered the dream, showing that for any consistent axiomatic system there will always be theorems that cannot be proven within the system. In case you’re wondering where on earth I’m going with this… it’s a very stretched analogy I’ve been playing with in my mind. One premise of many models of fairness in machine learning is that you can measure (‘prove’) fairness of a machine learning model from within the system – i.e. from properties of the model itself and perhaps the data it is trained on. Beyond the questions of whether any one model of fairness is better or worse than another, I’m coming to the realisation that this doesn’t hold. To show that a machine learning model is fair, you need information from outside of the system. For example, that there are no measurement errors or sampling biases in the data used to train the model. That’s not something you can show as a property just of the data itself without reference to outside information.
In security we have the notion of a Trusted Compute Base (TCB) – the piece that you just have to take on faith, and so long as our security assumptions about the TCB hold, we can show the rest of the system to be secure. Is there some equivalent Trusted Information Base (TIB), a set of information that we need to take on faith and then we can show the system is fair from that point on? If so, does the TIB need to be all of the training data, or can it be a subset? Perhaps the TIB just needs to be a set of assertions about properties of the training data and the way that reflects the real world? How small can we make a TIB?
Anyway, it’s time for me to stop making random associations and get down to the question of the paper in hand. Corbett-Davies and Goel look at three popular models of fairness and show that all of them have drawbacks. In contrast, a methodology that appears more troubling on the surface because it explicitly includes ‘protected characteristics’ turns out to be a better match with some properties we generally believe to be desirable.
The need to build fair algorithms will only grow over time, as automated decisions become even more widespread. As such, it is critical to address limitations in past formulations of fairness, to identify best practices moving forward, and to outline important open research questions.
Fairness, justice, and discrimination
The questions of fairness and justice, what they mean, and how to achieve them have been debated for millennia, so it’s not too surprising we find them difficult to grapple with in the context of machine learning. From an economic perspective there are two dominant categories of discrimination: statistical and taste-based.
In statistical discrimination, decision makers explicitly make use of protected attributes in order to achieve a non-prejudicial goal. For example, an auto-insurer charging a premium to male drivers. In taste-based discrimination decision makers sacrifice profit to avoid certain transactions, demonstrating a ‘taste’ for bias. For example, failing to hire exceptionally qualified minority applicants. These are both utility based definitions.
As opposed to utility-based definitions, the dominant legal doctrine of discrimination focuses on a decision maker’s motivations. Specifically, equal protection law – as established by the U.S. Constitution’s Fourteenth Amendment – prohibits government agents from acting with ‘discriminatory purpose.’
Taste-based discrimination is barred, as is classification based on protected attributes. The use of protected attributes can be allowed though when used to achieve equitable ends – e.g. with affirmative action. In some situations (particularly those concerning housing and employment practices), a practice can be deemed discriminatory even in the absence of categorisation or taste-based discrimination (‘animus’).
Algorithmic models of fairness
Three popular algorithmic definitions of fairness are anti-classification, classification parity, and calibration. Suppose we have a decision function $d(x)$ that takes an input vector of features $x$ and outputs a decision selecting one from a number of possible actions. The input vector $x$ can be partitioned into protected and unprotected features, $x_p$ and $x_u$.
Anti-classification
Under anti-classification, decisions do not make use of protected attributes, so we have that for all $x, x’$ where $x_u = x’_u$, $d(x) = d(x’)$.
Some definitions of anti-classification go further to also prohibit use of features correlated with prohibited attributes.
Classification parity
Classification parity says that some given measure of classification error is equal across groups defined by the protected attributes. If we choose the proportion of positive decisions as the measure then this is known as demographic parity. Here the protected attributes cannot introduce any bias towards a positive outcome:
$\displaystyle Pr(d(X) = 1 | X_p) = Pr(d(X) = 1)$
Calibration
Calibration says that outcomes should be independent of protected attributes, conditioned on risk score. Let $s(x)$ be the computed risk score, an approximation to the true risk $r(x)$. Calibration is satisfied when:
$\displaystyle Pr(Y=1 | s(X), X_p) = Pr(Y= 1| s(X))$
Threshold policies
Threshold rules use the computed risk score $s(x)$ to set $d(x) = 1$ only if $s(x)$ is greater than some threshold value. For example, in a banking context $s(x)$ may be the estimation of the risk of default, and loans may be denied to all applications with a risk of default greater than a threshold.
This strategy, while not explicitly referencing fairness, satisfies a compelling notion of equity, with all individuals evaluated according to the same standard. When the threshold is chosen appropriately, threshold rules also satisfy the economic and legal concepts of fairness described above.
Note that under a threshold rule, error rates will generally differ across groups, violating classification policy. The analysis also gets more complex when the costs and benefits of decisions varies across individuals, or when the level of uncertainty does. "Despite these complications, threshold rules are often a natural starting point."
It’s not fair!
We now argue that the dominant mathematical formalizations of fairness – anti-classification, classification parity, and calibration – all suffer from significant limitations which, if not addressed, threaten to exacerbate the very problems of equity they seek to mitigate.
Anti-classification limitations
One limitation of anti-classification is that there are many non-protected attributes which may correlate (or even strongly correlate) with protected attributes. Even more interesting though, is that the authors show examples where the exclusion of protected attributes ends up harming the groups you are trying to protect. For example, a model looking at the likelihood of re-offending that doesn’t take gender into account is likely to overstate the recidivism risk of women (all things being equal, women tend to re-offend less than men). Some states explicitly allow gender-specific risk assessment tools for this reason.
When gender or other protected traits add predictive value, excluding these attributes will in general lead to unjustified disparate impacts…
Classification parity limitations
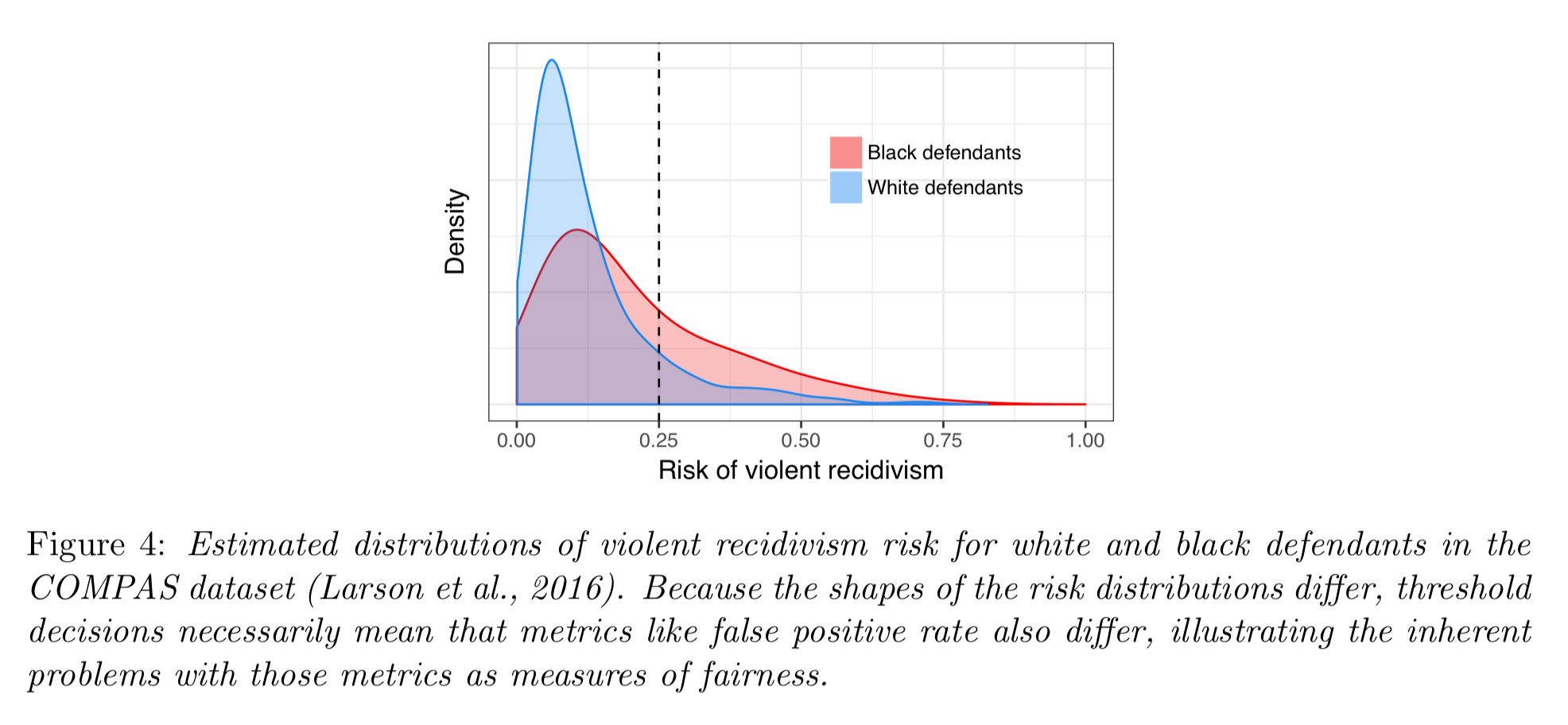
Classification parity includes many of the most popular mathematical definitions of fairness. But they run into trouble when the risk distributions are different for different groups.
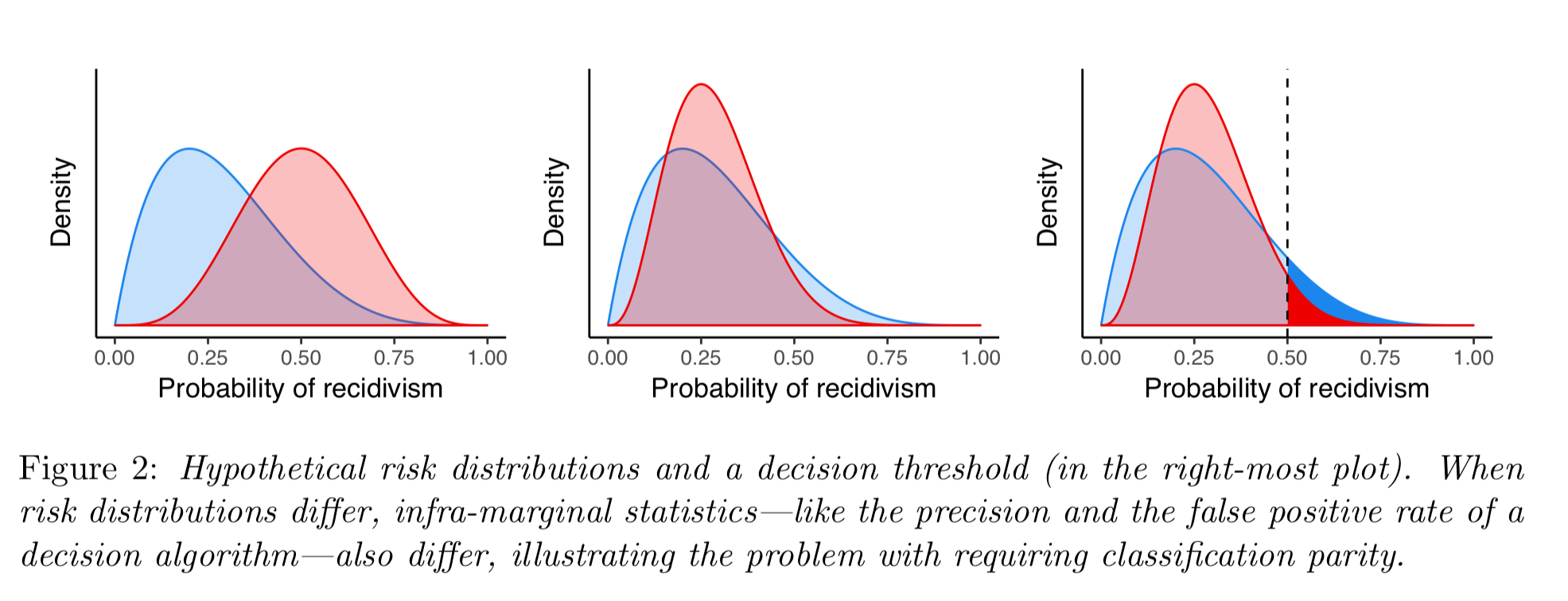
This sets us up for a fascinating discussion (in section 3.2 of the paper) on the problem of infra-marginality.
Because the risk distributions of protected groups will in general differ, threshold-based decisions will typically yield error metrics that also differ by group… This general phenomenon is known as the problem of infra-marginality in the economics and statistics literatures and has long been known to plague tests of discrimination in human decisions.
Most legal and economic understandings of fairness are concerned with what happens at the margin, whereas popular error metrics assess behaviour away from the margin.
When risk distributions differ, enforcing classification parity can often decrease utility for all groups.
Calibration limitations
Calibration is open to manipulation of risk distributions for different groups. For example, by changing the way data is aggregated in feature representations you can change the outcome. The penny dropped for me here when I realised this is just like Simpson’s Paradox. By adding or removing a grouping feature, just like in Simpson’s paradox, we could cause a trend to reverse! Think e.g. of elections and the differing outcomes of first-pass-the-post vs proportional representation. The paper describes a redlining example: take a model using individual risk scores in a certain area, and replace those scores with a risk score equal to the group mean; doing this concentrates the distribution around the mean resulting in it being less likely for e.g. a loan threshold to be met.
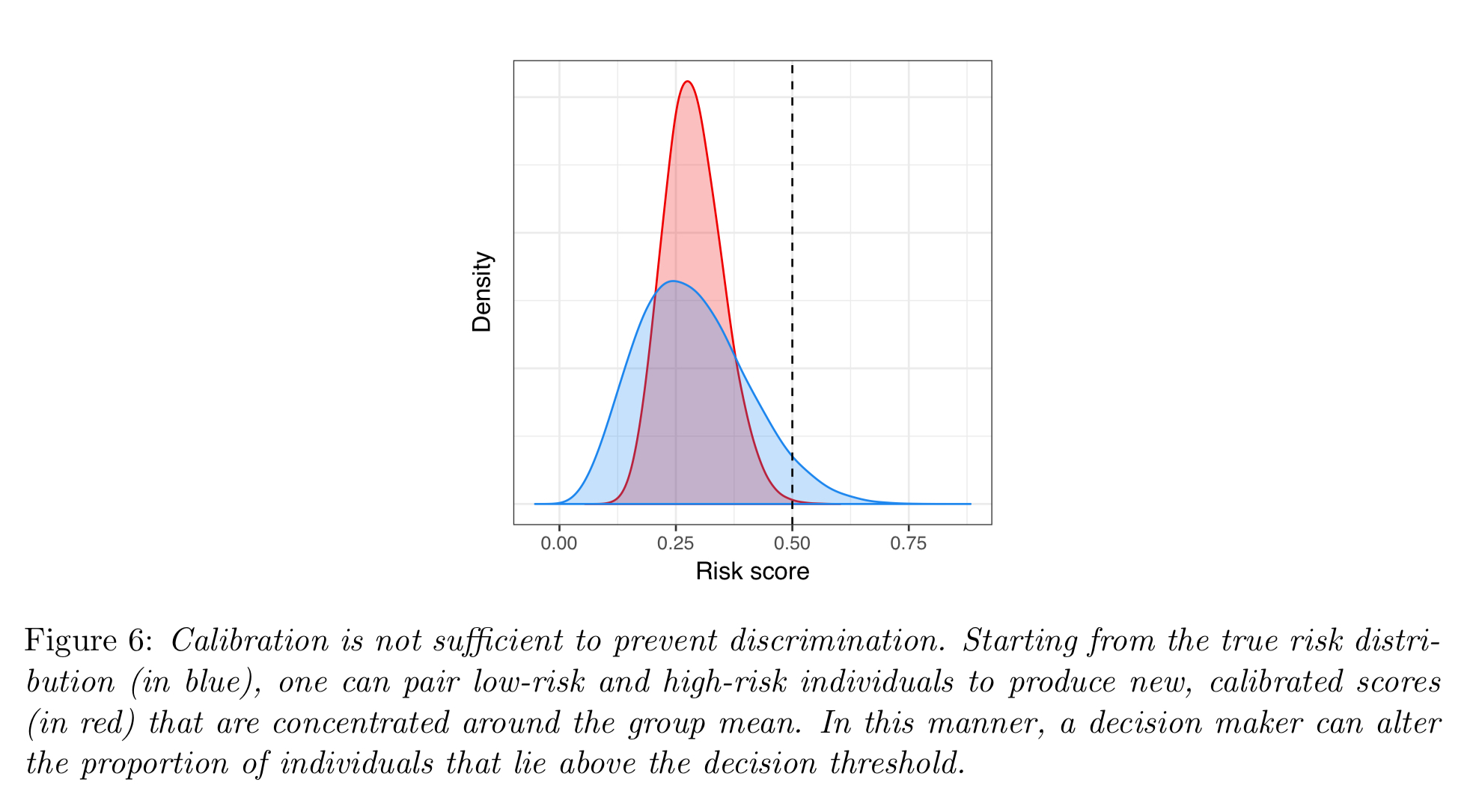
So how do you design an equitable algorithm?
Unfortunately, there is no simple procedure or metric to ensure algorithmic decisions are fair.
The authors do outline four key principles to help us on the way though:
- Whatever model we are using, all bets are off if our dataset is not representative of reality. Therefore we need to work hard to eliminate label bias and feature bias. Label bias is inaccuracy in the outcome labels in the training data, feature bias is inaccuracy in the data fed into decision engines. "Label bias is perhaps the most serious obstacle facing fair machine learning… there are no perfect solutions to the problem of label bias."
- Even with accurate features and labels, we still have to avoid sample bias, this is where algorithms are trained on datasets that are not representative of the populations on which they are ultimately applied. When the sample bias leads to differing levels of uncertainty for different groups we have uncertainty bias.
- When the feature space is high-dimensional or the training data is less plentiful, special care must be paid to the model form and its interpretability. "In the risk assessment community, there is a growing push to design statistical models that are simple, transparent, and explainable to domain experts." (See e.g. Rudin’19)
- Consider externalities and equilibrium effects. For example, in some situations it’s better to consider group rather than individual outcomes (e.g. in university admission, a diverse student body may benefit the entire instutition). In other cases the decisions made by an algorithm can create feedback loops with unintended effects (see e.g. ‘Delayed impact of fair machine learning‘)
Decouple risk assessment and intervention
I’ll leave you with this one final thought from the conclusion of the paper:
We recommend decoupling the statistical problem of risk assessment from the policy problem of designing interventions.
Statistical algorithms can estimate the likelihood of different events, but they can never have the full picture. In many scenarios, their output is better placed as one input to a human decision making process rather than deciding outcomes directly from the algorithm.

“In many scenarios, their output is better placed as one input to a human decision making process rather than deciding outcomes directly from the algorithm.”. This highlights the need for model interpretability. How can a human justify the decision of a black box?
The math here rendered fine in the email newsletter, but didn’t render properly on the page above for some reason. Thanks for the post!