Do we need specialized graph databases? Benchmarking real-time social networking applications Pacaci et al., GRADES’17
Today’s paper comes from the GRADES workshop co-located with SIGMOD. The authors take an established graph data management system benchmark suite (LDBC) and run it across a variety of graph and relational stores. The findings make for very interesting reading, and may make you think twice before you break out the graph store on your next OLTP-like application.
The highly-connected structure of many natural phenomena, such as road, biological, and social networks make graphs an obvious choice in modelling. Recently, storage and processing of such graph-structured data have attracted significant interest both from industry and academia and have led to the development of many graph analytics systems and graph databases.
Analytics systems such as Pregel, Giraph, and PowerGraph specialize in OLAP-like batch processing of graph algorithms. Graph databases focus on real-time querying and manipulation of entities, relationships, and the graph structure.
Many studies focus on comparisons between different graph database engines and graph analytics systems. Although there are some studies comparing graph databases with relational models, the real-time aspect of graph applications is mostly ignored and more complex graph traversals are not tested.
The work in this paper fills that gap.
Finding a fair workload for benchmarking
If you want to say “my database is better than your database” then you really also need to specify “for what?”. And if you want to evaluate whether graph databases really do earn their keep as compared to relational databases, you really want to do the comparison on the home turf of the graph databases – the use cases they claim to be good at.
The Linked Data Benchmark Council (LDBC) is a joint effort from academia and industry to establish benchmarking practices for evaluating RDF and graph data management systems, similar to the Transaction Processing Performance Council (TPC).
The LDBC Social Network Benchmark (SNB) models a social graph, and three different workloads based on top of it. Of these, the SNB Interactive workload is an OLTP-like workload designed to simulate real-world interactions in social networking applications.
If you have a joint benchmarking council going to all the trouble of specifying graph based benchmarks, it seems reasonable to assume the council believe these to be representative of the kinds of workloads graph databases are expected to be used for in the wild. So that seems a pretty good choice to use to compare different graph systems and relational systems.
Strictly of course all we can say from the results of this paper is that “for the LDBC SNB Interactive Workload running on a single 32 core node, this is what we found.” There may be other workloads which show graph databases in a stronger light (and vice-versa). But it’s a very good start, and a little extrapolation is justified I feel.
The LDBC SNB Interactive Workload species a set of read-only traversals that touch a small portion of the graph and concurrent update transactions that modify the social network’s structure. The majority of the read-only traversals are simple, common social networking operations that involve transitive closure, one-hop neighbourhood, etc. The rest of the read-only traversals are complex operations that are usually beyond the functionality of real-world social network systems due to their online nature.
The primary goal of the benchmark is to evaluate technical choke points in the underlying systems under test.
Systems under test
Representing highly-connected data in the relational model results in a large amount of many-to-many relations, which can produce complex, join-heavy SQL statements for graph queries. By focusing not on the entities but rather the relationships among the entities, graph databases and RDF stores can offer efficient processing of graph operations like reachability queries and pattern matching.
RDF stores represent graphs as collections of triples and use a standardised query language called SPARQL. Graph databases mostly use adjacency lists for storing adjacency information next to each entity. This enables index-free adjacency access with relationships traversed directly by pointers. Most graph databases support a proprietary query API (e.g. Neo4j’s Cypher), and there are also efforts to provide a uniform querying API across stores, most notably Apache TinkerPop3. TinkerPop3 provides the Gremlin Structure API and the Gremlin query language. For TinkerPop3-compliant databases, Gremlin queries are supported through the Gremlin server.
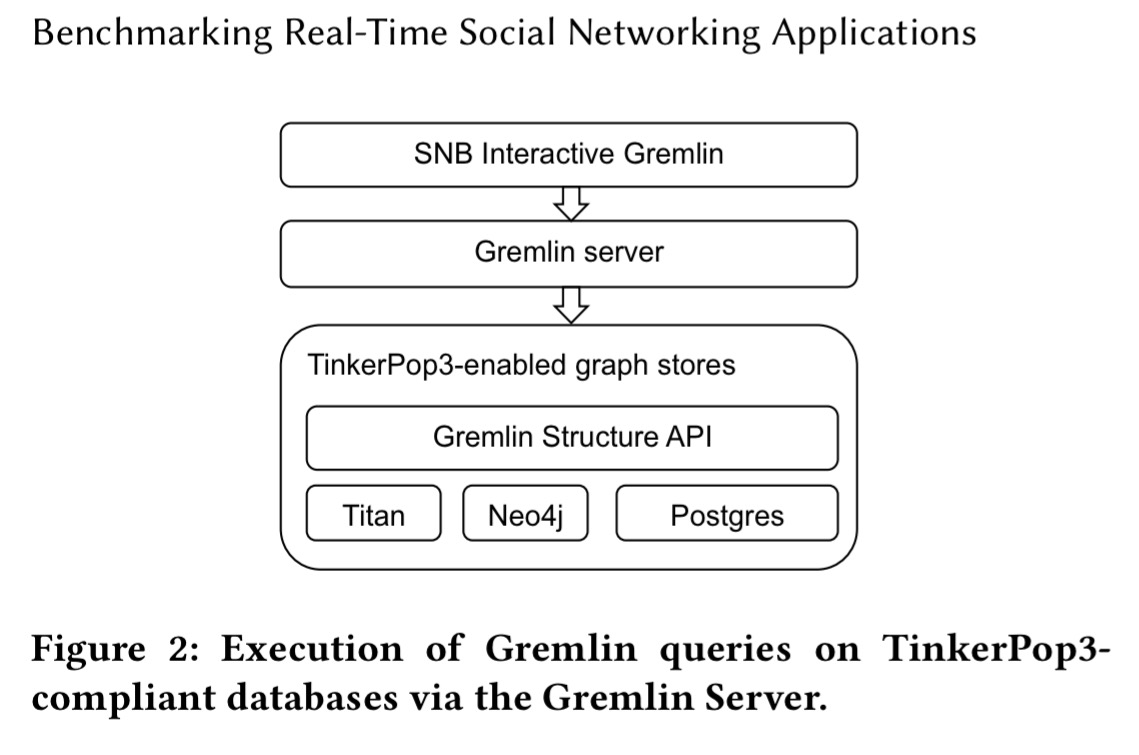
The authors created reference implementations of the LDBC SNB Interactive workload in Gremlin and in SQL as well as using the database proprietary APIs. The SQL implementation maps each vertex type and edge type to separate tables.
The full list of evaluated systems is as follows:
- TitanDB v1.1 with Cassandra (Titan-C) and BerkeleyDB (Titan-B) storage backends. (Gremlin query language)
- Neo4j 2.3.6 with both Gremlin and Cypher
- Virtuouso Opensource v7.2.4 – a column store RDBMS with support for RDF processing. Tested with both SQL and SPARQL queries (i.e. RDF, and non-RDF).
- Postgres v9.5, using native SQL queries
- Sqlq v1.3.3 – a TinkerPop3 implementation on top of Postgres (Gremlin query language)
The systems were run on a 32x 2.6 GHz core machine with 256 GM RAM, and configured to load the entire dataset into main memory.
Workloads were created using the LDBC data generator at two different scale factors (3 and 10), resulting in the following dataset statistics:
 (Enlarge)
(Enlarge)
Key results
Examining read-only graph queries first (point lookups, one-hop traversals, two-hop traversals, and single-pair shortest path queries), the authors found that the relational databases provide the lowest query latency across all query types. They also found that Gremlin support comes with high overheads:
For Neo4j, the Gremlin interface introduces up to two orders of magnitude of performance degradation compared to the native Cypher interface. Similarly, Postgres (SQL) significantly outperforms Sqlg (Gremlin) even though both systems have the same underlying data model and storage engine.
The more complex the query, the worse Gremlin seems to do, as show in the following result tables: one for the scale 3 dataset, and one for scale 10 (highlights mine).
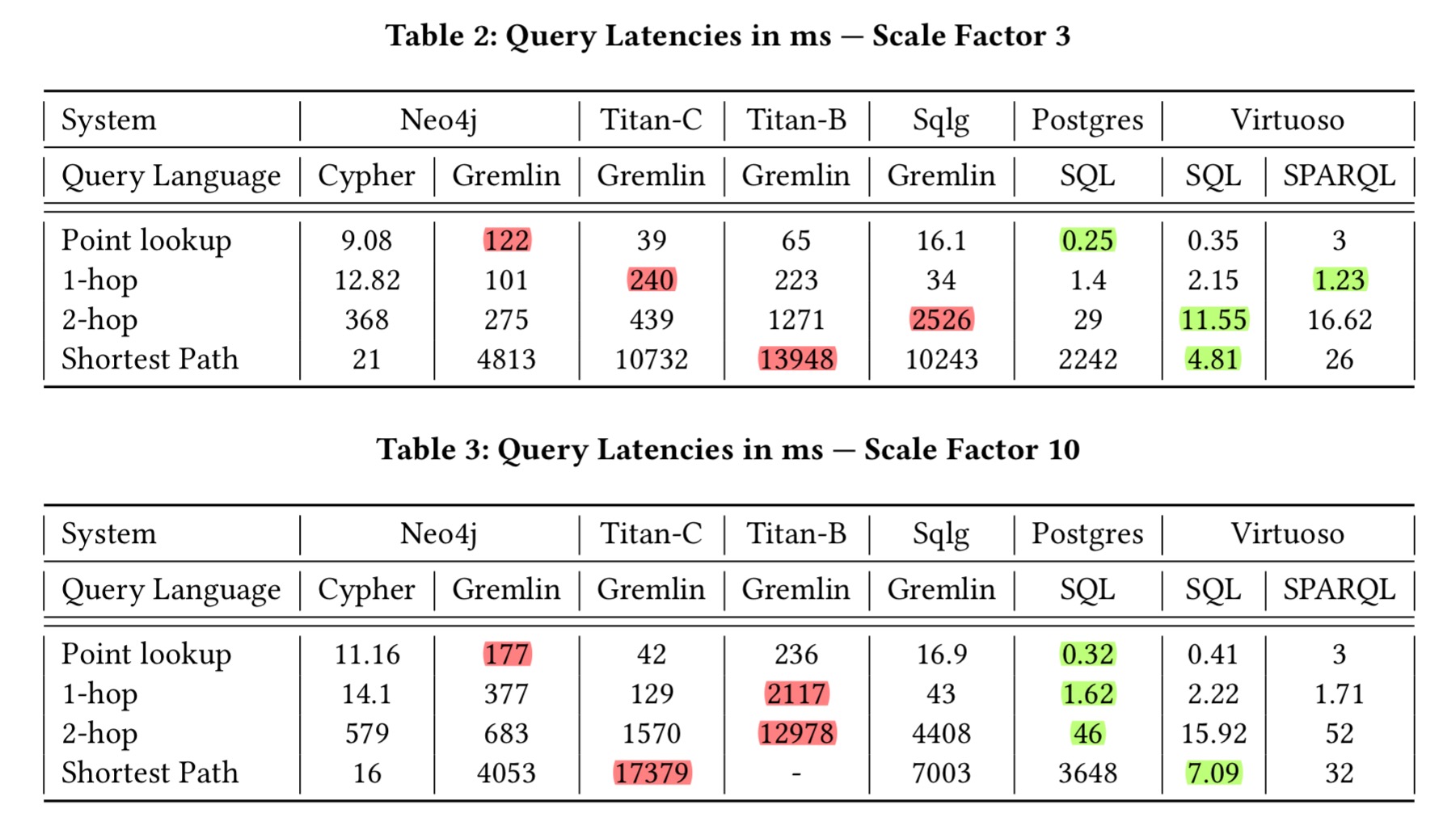
Take a look at the Postgres and Neo4j (Cypher) columns in the scale factor 10 table above. For queries up to two hops (i.e., two joins, not especially stressful for an RDBMS), Postgres outperforms Neo4j by an order of magnitude. For the shortest path query however, Neo4j outperforms Postgres by two orders of magnitude. It’s Virtuoso though that shows the best overall performance across the board, with its SQL interface, even beating Neo4j with Cypher on the shortest path query. Notice that all of my green (best in row) highlights at scale factor 10 are in SQL columns!
Virtuoso (SQL) outperforms Postgres (SQL) in more complex two-hop traversals and single-pair shortest path queries. Virtuoso’s graph-aware engine and optimized transitivity support enable it to execute such complex graph queries eciently. Virtuoso (SPARQL) has slightly lower performance due to query translation costs, even though the benchmark queries are graph queries.
The second part of the evaluation used the full LDBC SNB Interactive workload to simulate the real-time aspects of online social networking applications (the authors processed updates through a dedicated Kafka queue, modelling a structure commonly seen in industrial deployments). The TinkerPop3 systems couldn’t cope with the relatively large numbers of complex queries in the mix specified by the benchmark. The authors chose to change the mix to include just a two-hop neighbourhood-based complex query and a set of short read-only queries. Even then, Titan-B had to be withdrawn from the experiment as its performance degradation was too severe. Personally I would really like to have also seen the results on the original query mix for the systems that could handle it – the choice made by the authors here seems to bias things in favour of the SQL systems.
For the scale 3 dataset this time, here are the aggregrate read and write throughputs obtained:
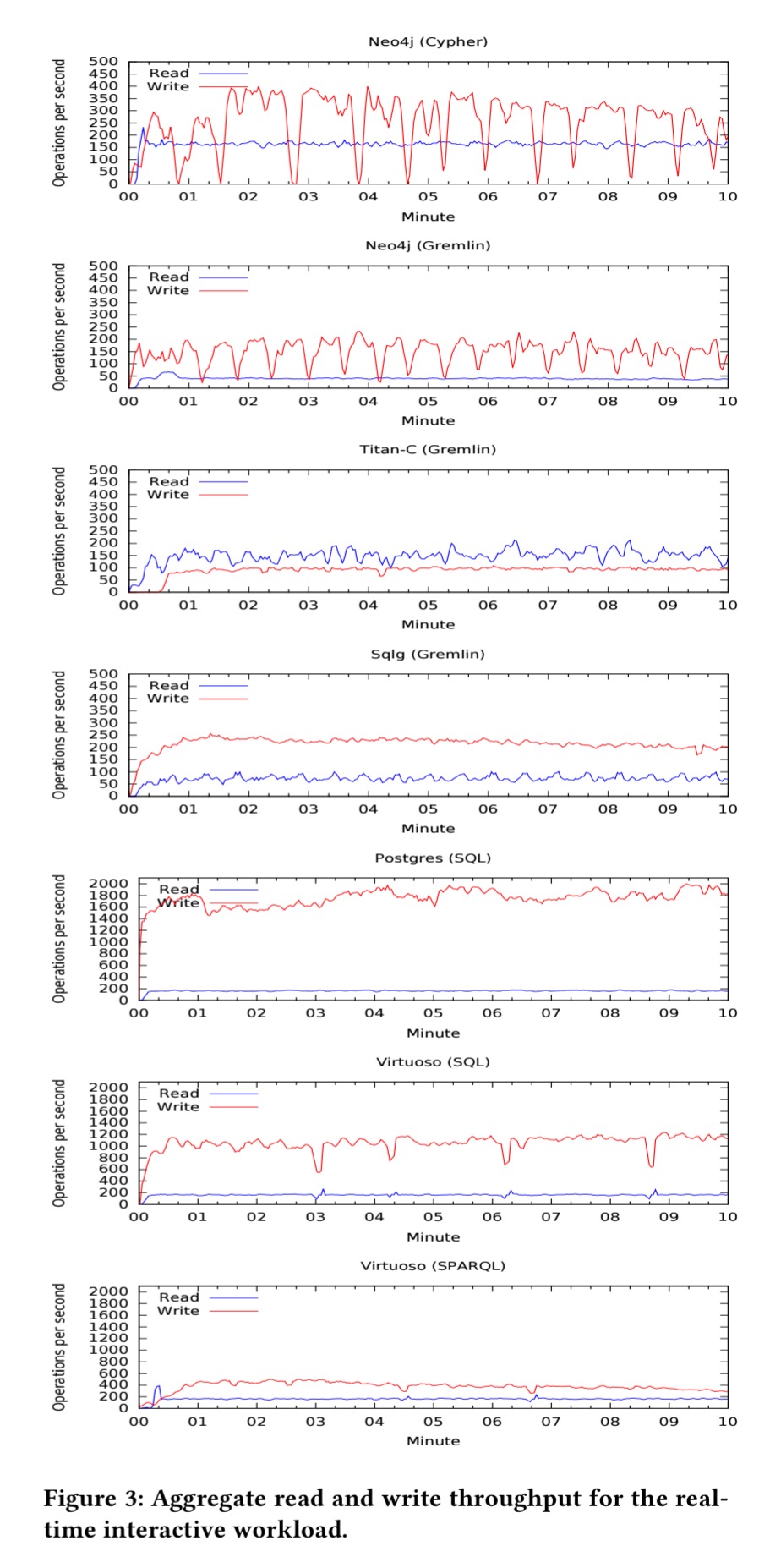
In general, RDBMSes with a native SQL interface provide the best performance under the real-time interactive workload. While read performance of selected systems are comparable and within a factor of four, Postgres (SQL) and Virtuoso (SQL) exhibit significantly better update performance and maintain up to an order of magnitude faster write throughput compared to their competitors.
Note also the frequent sudden drops in Neo4j’s (Cypher) update performance – attributed to checkpointing.
Takeaways
- Maybe stay away from Gremlin for now. It’s a very worthy goal, but the performance just doesn’t seem to be there to justify it at the moment.
A more concerning problem relates to the performance of the Gremlin Server… it was unable to handle complex queries under a large number of concurrent clients… causing it to hang and eventually crash. Overall our experience reveals the generally poor state of implementations and suggests that TinkerPop3 and specifically the Gremlin Server are not production ready.
- If you don’t have lots of complex graph operations, RDBMSs can provide competitive performance under a concurrent transactional workload:
We believe that robust RDBMS technology can deliver competitive performance for OLTP-like online social networking applications, especially in single-node settings… RDBMSes should not be ignored for interactive transactional graph workloads.
Discussion
Does this mean you shouldn’t use a graph database? I don’t think you can draw that conclusion from this study. On the one hand, the benchmarks used seem to bias the workload towards things which traditional relational databases are very good at, so it’s no suprise they do well. But on the other hand the workload was chosen as representative of an OLTP-like graph workload as selected by an independent benchmarking council. We can conclude that if you have an OLTP-like graph workload it’s well worth checking out the relational alternative before you take the plunge.
You may recall we previously looked at Ground, which captures lineage, model, and version metadata graphs for data. This is a problem most naturally modelled in a graph store (indeed, one of the companies I work with, Atomist, use a graph database for a very similar use case). In the Ground paper we also find some hints about the best kind of store for this workload – they found that relational systems (Postgres) were an order of magnitude slower than graph processing systems for their workload. They also found that even the leading graph databases were lacking in terms of performance at scale.
This theme was also echoed in the ‘Dependency-driven analytics‘ paper: “… this experience indicates that industry is in desperate need for a fully capable, scale-out graph solution that can handle complex, large, and structured graphs…“.

{kind=link}
Gremlin is not just an API, it’s a Turing-complete programming language for graph traversals and transformations. It has dedicated VM for traversals evaluation, that in case of Titan-B or Titan C has its graph data to far from traversal logic (means latency). Gremlin-expressions can be translated to SQL or to any other Turing-complete PL over graphs for execution, and actually it’s the most natural way of executing Gremlin. Those benchmarks just mean that Gremlin-to-SQL pipelines are too weak technically both at the level of Gremlin VM and traversals-using-sql-pipelines. TinkerGraph (ligthweight in-memory implementation of TinkerPop3 API) works very well with Gremlin until it is not restricted with GC. Virtuoso is surprisingly fast at generic graph workload because it is explicitly designing for it. Unfortunately it has overall architecture that is not scaleout-friendly.
This work is immediately invalid with respect to Gremlin because queries are submitted via Gremlin Server (a web server) Vs. direct database via gremlin-driver. The benchmark should have compared like-for-like direct database access.
I’m quite curious about the specific configurations you used, particularly of Virtuoso. Virtuoso’s overall victory does not surprise me, but I still wonder whether it was optimally configured.
I also wonder whether you’ve explored our own detailed discussions of similar benchmark comparisons (e.g., https://www.openlinksw.com/weblog/oerling/?id=1739), or the benchmark-focused AMI (discussed at https://www.openlinksw.com/weblog/oerling/?id=1843)?
Hi Ted, just to be clear, I’m not an author of the original paper, I simply posted a summary and discussion of what I found there. Thanks for the links though, very relevant! Regards, Adrian.
You should benchmark ArangoDB as well. It’s a different data structure that I find a lot more efficient for the sort of queries you’re dealing with here.
Regarding fully capably scale-out graph solutions, I’m curious about solutions like Datastacks Enterprise Graph (Titan), or Apache Spark GraphFrames? Built on distributed systems they are advertised to scale, but I’m not sure they support all the graph operations in the benchmark.
Wondering why RDF-3X was not included in these benchmarks?!