Using word embedding to enable semantic queries in relational databases Bordawekar and Shmeuli, DEEM’17
As I’m sure some of you have figured out, I’ve started to work through a collection of papers from SIGMOD’17. Strictly speaking, this paper comes from the DEEM workshop held in conjunction with SIGMOD, but it sparked my imagination and I hope you’ll enjoy it too. Plus, as a bonus it’s only four pages long!
What do you get if you cross word embedding vectors with a relational database? The ability to ask a new class of queries, which the authors term cognitive intelligence (CI) queries, that ask about the semantic relationship between tokens in the database, rather than just syntactic matching as is supported by current queries. It’s a really interesting example of AI infusing everyday systems.
We begin with a simple observation: there is a large amount of untapped latent information within a database relation. This is intuitively clear for columns that contain unstructured text. But even columns that contain different types of data, e.g., strings, numerical values, images, dates, etc., possess significant latent information in the form of inter- and intra-column relationships.
If we understood the meaning of these tokens in the database (at least in some abstract way that was comparable), we could ask queries such as “show me all the rows similar to this.” That’s something you can’t easily do with relational databases today – excepting perhaps for range queries on specific types such as dates. Where can we get comparable abstract representations of meaning though? The answer is already given away in the paper title of course – this is exactly what word embedding vectors do for us!
If you’re not familiar with word embedding vectors, we covered word2vec and GloVe in The Morning Paper a while back. In fact, “The Amazing Power of Word Vectors” continues to be one of the most read pieces on this blog. In short:
The idea of word embedding is to fix a d-dimensional vector space and for each word in a text corpus associate a dimension d vector of reals numbers that encodes the meaning of that word… If two words have similar meaning, their word vectors point in very similar directions.
The authors use word2vec in their work, though as they point out they could equally have used GloVe.
How do we get word embedding vectors for database content?
One approach is to use word vectors that have been pre-trained from external sources. You can also learn directly from the database itself. Think of each row as corresponding to a sentence, and a relation as a document.
Word embedding then can extract latent semantic information in terms of word (and in general, token) associations and co-occurrences and encode it in word vectors. Thus, these vectors capture first inter- and intra-attribute relationships within a row (sentence) and then aggregate these relationships across the relation (document) to compute the collective semantic relationships.
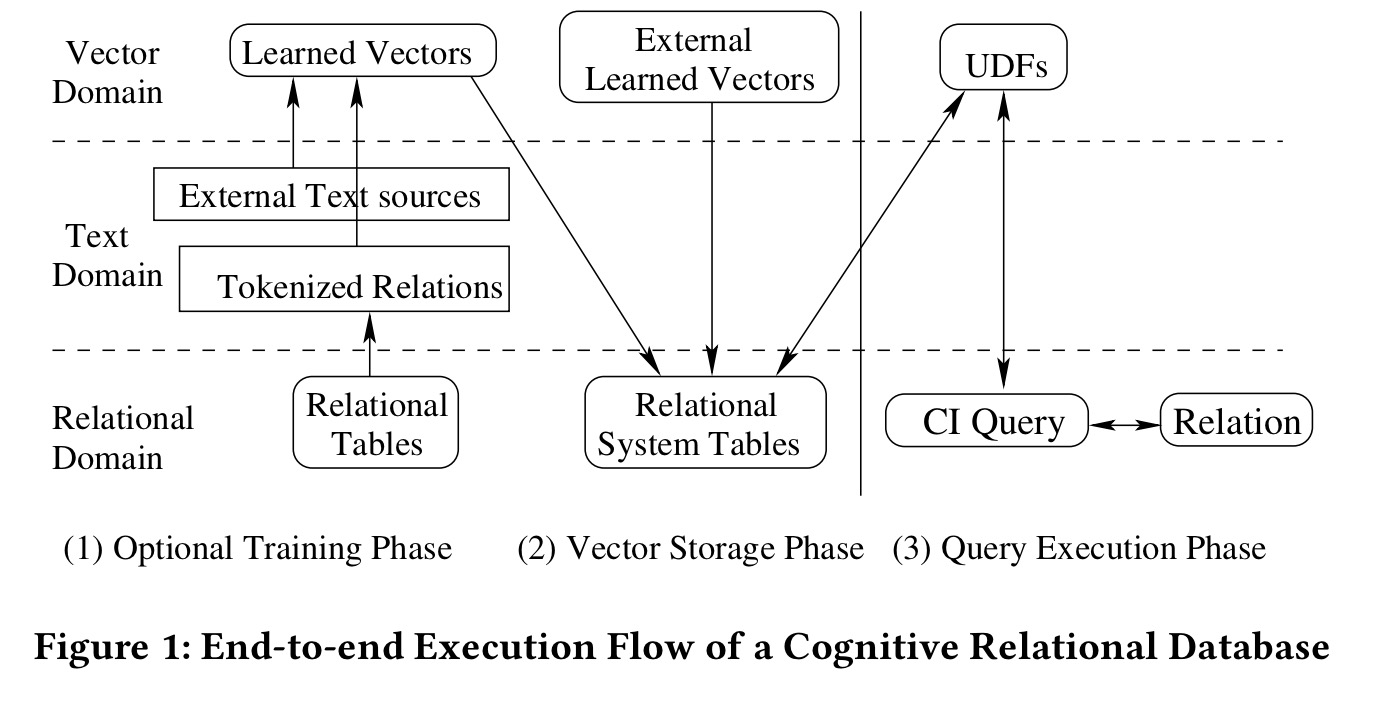
In their prototype implementation, the authors first textify (!) the data in a database table (e.g., using a view), and then use a modified version of word2vec to learn vectors for the words (database tokens) in the extracted text. This phase can also use an external source (e.g. Wikipedia articles) for model training.
We use word as a synonym to token although some tokens may not be valid words in any natural language. Following vector training, the resultant vectors are stored in a relational system table.
At runtime, the system (built on Spark using Spark SQL and the DataFrames API) uses UDFs to fetch trained vectors from the system and answer CI queries.
CI Queries
Broadly, there are two classes of cognitive intelligence queries: similarity and prediction queries… The key characteristic of the CI queries is that these queries are executed, in part, using the vectors in the word embedding model. If the word embedding model is generated using the database being queried, it captures meaning in the context of the associated relational table, as specified by the relational view. If a model is rebuilt using a different relational view, a CI query may return different results for the new model.
It’s time to look at some concrete examples to make all this a bit clearer. Given a similarityUDF that can tell us how similar two sets of word vectors are, we can ask a query such as:

In this case, the vector sets correspond to the items purchased by the corresponding customers. What this query will return is pairs of customers that have similar purchasing histories!
The pattern observed in this query can be applied to other domains as well, e.g., identifying patients that are taking similar drugs, but with different brand names or identifying food items with similar ingredients, or finding mutual funds with similar investment strategies.
The key difference to a traditional query is that we’re matching by semantic similarity, not by values.
Recall that word embeddings also support inductive reasoning (e.g., the classic King is to Man as Queen is to ? style queries). You can exploit this capability in CI queries too. In the following toy example, we’re looking for food product pairs that relate to each other as ‘peanut-butter’ relates to ‘jelly’. (For example, the query may return the pair ‘chips’, ‘salsa’).

The analogyUDF computes the differences (peanut butter – jelly) and (p1 – p2) and looks at the cosine similarity of those differences.
The analogy capabilities of CI queries have several applications in the enterprise space, e.g., associating customers with either most-common or least-common purchases in a given domain (e.g., books, electronics, etc.).
I understand the analogy query mechanism, but I’m not sure I quite get the example the authors are trying to give above. Neither finding product popularity, nor seeing whether a customer has purchased a low-popularity (high popularity) item seems to need an analogy? Here’s an example of my own – recommendation by analogy: razor is to blade as [product the customer just put in their basket] is to ?. (Probably not about to replace frequent itemset mining anytime soon!)
Our final example shows how embeddings trained using external data can be used in queries. Suppose we trained word embeddings with a data set that reveals information about fruits and their allergenic properties. We would have a relationship between the vector for ‘allergenic’ and the vectors for allergenic fruit names. Now we can ask:

This example demonstrates a very powerful ability of CI queries that enables users to query a database using a token (e.g., allergenic) not present in the database.
The last word
Will all relational databases one day come with CI querying capabilities built-in?
In summary, we believe this work is a step towards empowering database systems with built-in AI capabilities… We believe CI queries are applicable to a broad class of application domains including healthcare, bio-informatics, document searching, retail analysis, and data integration. We are currently working on applying the CI capabilities to some of these domains.

Possible typos there is a quoted section on word vectors which twice says “work vectors”?
Fixed, thank you!
Pretty interesting use of word embeddings but it doesn’t seem practical for real systems. Executing the first query (Figure 2) will imply to obtain the cosine similarities between all pairs of sales in the DB.