Blockbench: a framework for analyzing private blockchains Dinh et al., SIGMOD’17
Here’s a paper which delivers way more than you might expect from the title alone. First we get a good discussion of private blockchains and why interest in them is growing rapidly. Then the authors analyse the core layers in a private blockchain, and show how existing systems make different trade-offs in each of these areas. Finally, using the Blockbench tool we get a whole new level of understanding of how well the systems work in practice and their various strengths and weaknesses. Based on their findings, the authors conclude with a set of recommendations for future private blockchain designs. Even the appendices are great! Especially if you’re interested in future applications of blockchain technology beyond cryptocurrencies, it’s well worth a read.
Introducing private blockchains
Interest from the industry has started to drive development of new blockchain platforms that are designed for private settings in which participants are authenticated. Blockchain systems in such environments are called private (or permissioned), as opposed to the early systems operating in public (or permissionless) environments where anyone can join and leave. Applications for security trading and settlement, asset and finance management, banking and insurance are being built and evaluated.
Most of these applications currently run on traditional enterprise databases. Why is blockchain so exciting for these use cases?
- Blockchain immutability and transparency help reduce human errors and the need for manual intervention due to conflicting data.
- Blockchain can streamline processes by removing duplicate efforts in data governance.
- Blockchain provides a basis for cooperation among competing entities that may not fully trust each other.
Goldman Sachs estimated 6 billion saving in current capital markets, and J.P. Morgan forecast that blockchains will start to replace currently redundant infrastructure by 2020.
For private blockchain use cases, we need more complex state than just the digital coins (cryptocurrency) supported in Bitcoin, and we need trusted logic to manipulate that state. A good example is Ethereum with its smart contracts (which we looked at previously).
Ethereum extends Bitcoin to support user-defined and Turing complete state machines. In particular, Ethereum blockchain lets the user define any complex computations in the form of smart contracts.
Ethereum uses proof-of-work (PoW) based consensus, as do nearly all public blockchain systems. In permissioned environments PoW can still be used, but there are more efficient and deterministic approaches where node identities are known.
Recent permissioned blockchains either use PBFT, as in Hyperledger, or develop their own variants, as in Parity, Ripple, and ErisDB… As a result, permissioned blockchains can execute complex applications more efficiently than PoW-based blockchains, while being Byzantine fault tolerant. These properties and the commercial interests from major banking and financial institutions have bestowed on private blockchains the potential to disrupt the current practice in data management.
An abstract model of a blockchain system
The multitude of blockchain based systems all have different design points. As a basis for comparison, the authors use the following abstract model:
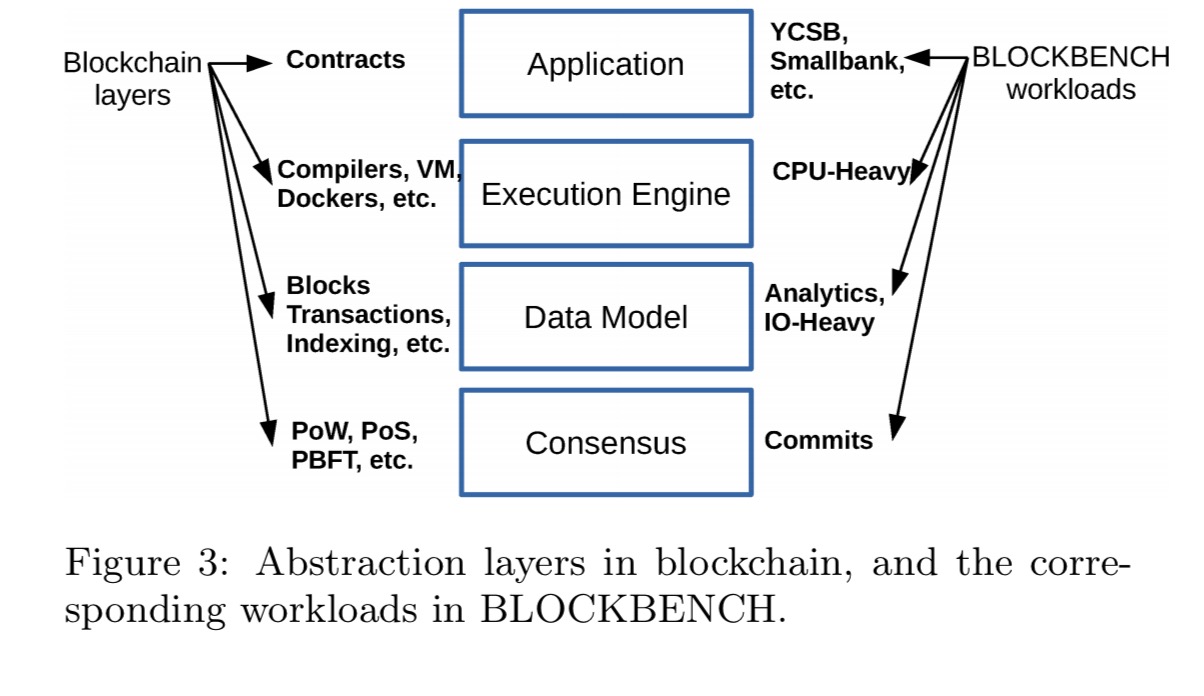
Starting from the bottom,
- the consensus layer is responsible for reaching agreement on when a block is added to the blockchain,
- the data layer contains the structure, content and operations on the blockchain data itself,
- the execution engine is the runtime environment supporting blockchain operations, and
- the application layer includes classes of blockchain applications.
Blockbench, which we’ll come onto shortly, contains benchmarks designed to evaluate the performance of different implementations in each of these layers.
Consensus
Blockchain systems employ a spectrum of Byzantine fault-tolerant protocols. Bitcoin uses a proof of work scheme at a difficulty level achieving a rate of one block every 10 minutes. Ethereum also uses proof of work, but tuned to achieve a rate of one block every 14 seconds.
[PoW] consumes a lot of energy and computing power, as nodes spend their CPU cycles solving puzzles instead of doing otherwise useful work. Worst still, it does not guarantee safety: two nodes may both be selected to append to the blockchain, and both blocks can be accepted. This causes a fork in the blockchain, and most PoW-based systems add additional rules, for example, only blocks on the longest chain are considered accepted.
At the other end of the spectrum, HyperLedger uses PBFT (Practical Byzantine Fault Tolerance) which has communication overhead in 

PBFT has been shown to achieve liveness and safety properties in a partially asynchronous model, thus unlike PoW, once the block is appended it is confirmed immediately.
PBFT does require the node identities to be known, and is limited in scale due to the communication overhead.
In-between full PoW and PBFT there are a variety of design points, for example Byzcoin and Elastico use PoW to determine random smaller consensus groups which then run PBFT. Other models include proof-of-stake systems, of which an interesting variant is proof-of-authority: each pre-determined authority is assigned a fixed time-slot within which it can generate blocks.
Data model
In Bitcoin, transactions are first class citizens: they are system states representing digital coins in the network. Private blockchains depart from this model, by focusing on accounts. One immediate benefit is simplicity, especially for applications involving crypto-currencies.
Ethereum smart contract accounts combine executable code and private states. The code can read the state of other non-contract accounts, and can send new transactions. Hyperledger has accounts called chaincode which are like Ethereum’s contracts, only chaincode can only access its own private storage.
Parity keeps block content in memory. Ethereum and Hyperledger use two-layered data structures with disk-based key-value storage. There are also variations in Merkle trees (e.g. Patricia-Merkle trees supporting efficient update and search, and Bucket-Merkle trees which use hashing to group states into a list of buckets from which a Merkle tree is built).
Execution engine
Execution must be fast, since multiple contracts and transactions in a block must all be verified by a node, and it must be deterministic so that unnecessary inconsistency in transaction input and output leading to blocks being aborted can be avoided.
Ethereum develops its own machine language (bytecode) and a virtual machine (called EVM) for executing the code, which is also adopted by Parity.
This enables Ethereum to keep track of gas, the tax on execution. HyperLedger doesn’t have this concept, and simply supports running Docker images. The HyperLedger API exposes only putState and getState (key-value), whereas Ethereum and Parity support richer data types such as map, array, and composite structures.
Application layer
Many applications are being proposed for blockchain, leveraging the latter’s two key properties. First, data in the blockchain is immutable and transparent to the participants, meaning that once a record is appended, it can never be changed. Second, it is resilient to dishonest and malicious participants. Even in permissioned settings, participants can be mutually distrustful. The most popular application, however, is still crypto-currency.
Beyond cryptocurrencies though, new applications which build on the immutability and transparency of blockchains are emerging.
For example, security settlements and insurance processes can be sped up by storing data on the blockchain. Another example is sharing economy applications, such as AirBnB, which can use blockchain to evaluate reputation and trust in a decentralized settings, because historical activities of any users are available and immutable. This also extends to Internet of Things settings, where devices need to establish trust among each other.
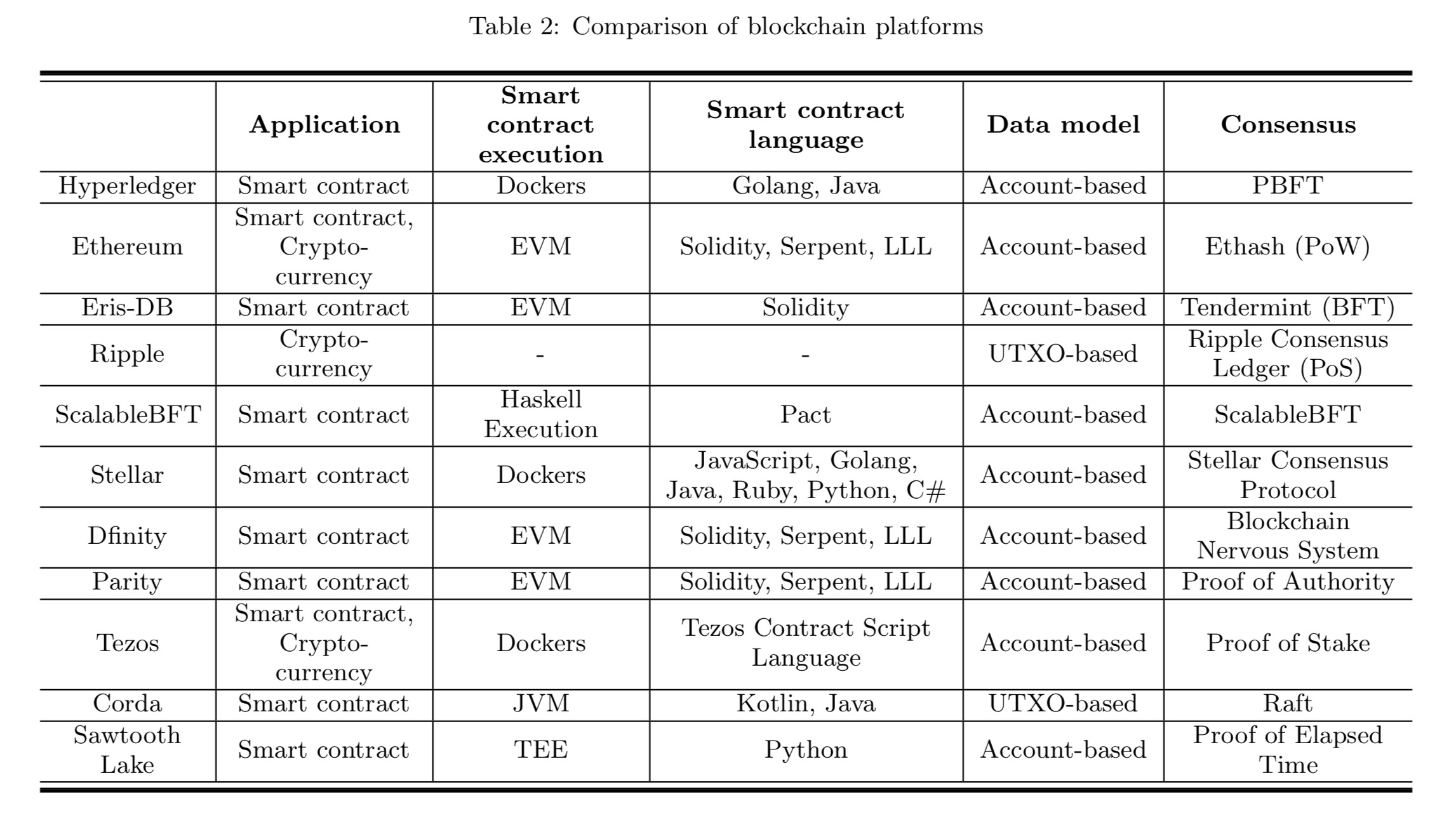
Design choices for selected systems
The following table from the appendix shows the choices made at each layer by a variety of blockchain platforms.
Existing blockchain systems under the microscope
Blockbench is an open source benchmarking system developed by the authors to evaluate a variety of different blockchain platforms under a set of workloads designed to exercise them at each layer.
Blockbench is structured such that you can write an adapter to plugin the blockchain platform of your choice.
We selected Ethereum, Parity, and Hyperledger for our study, as they occupy different positions in the blockchain design space, and also for their codebase maturity.
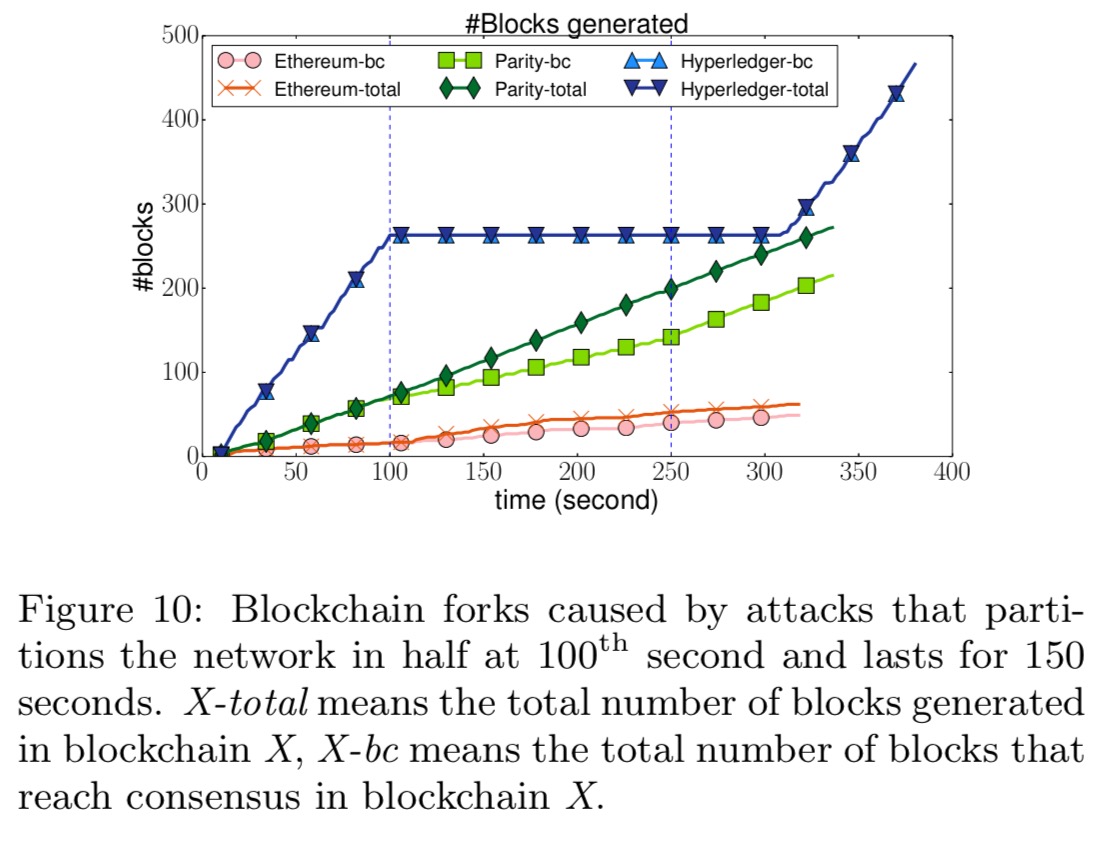
Blockbench measures throughput, latency, scalability, and fault tolerance (by injecting crash failures, network delays, and random responses). It can also measure security, defined as the number of blocks in forks, which represent the window in which an attacker can perform double spending or selfish mining. Blockbench simulates attacks, including BGP hijacking by partitioning the network for a given duration. The security score is the ratio between the total number of blocks included in the main branch, and the total number of blocks confirmed by users.
Here are the key findings:
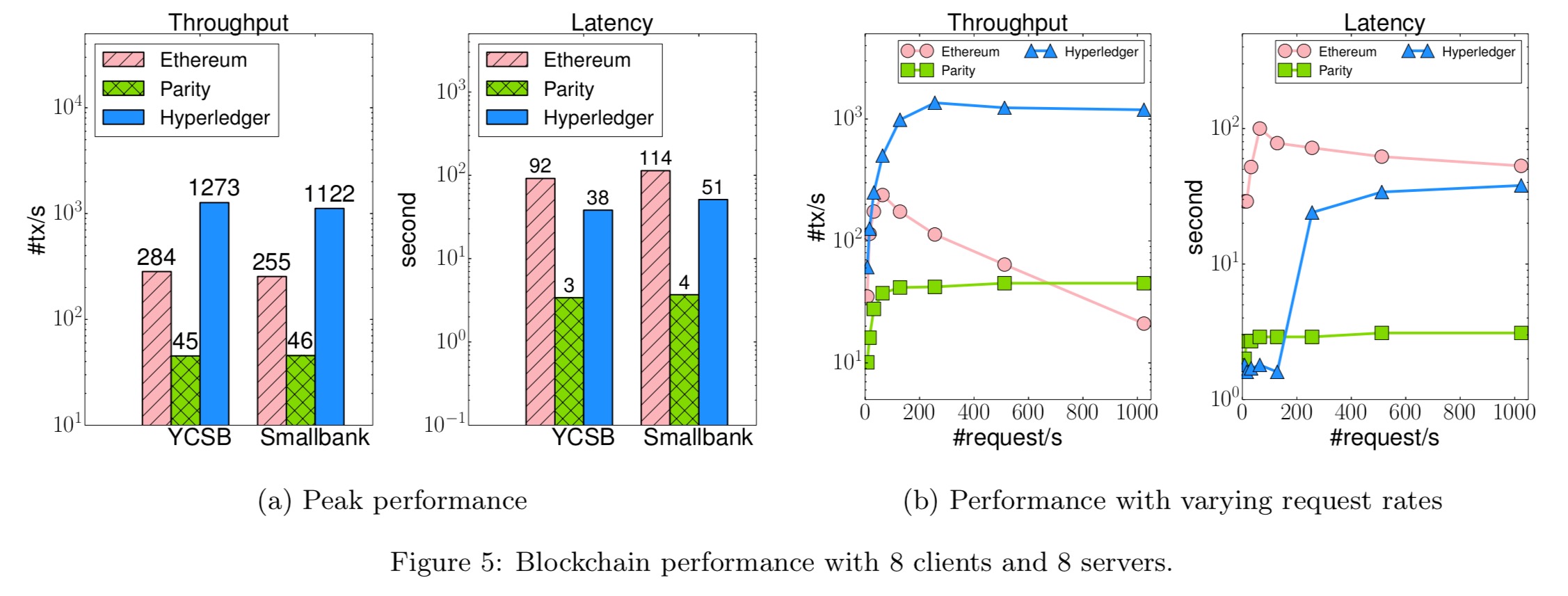
- Hyperledger performs consistently better than Ethereum (5.5x) and Parity (28x) across the benchmarks, but it fails to scale up to more than 16 nodes. (A new implementation of PBFT has now been released for Hyperledger post this study, which may scale better).
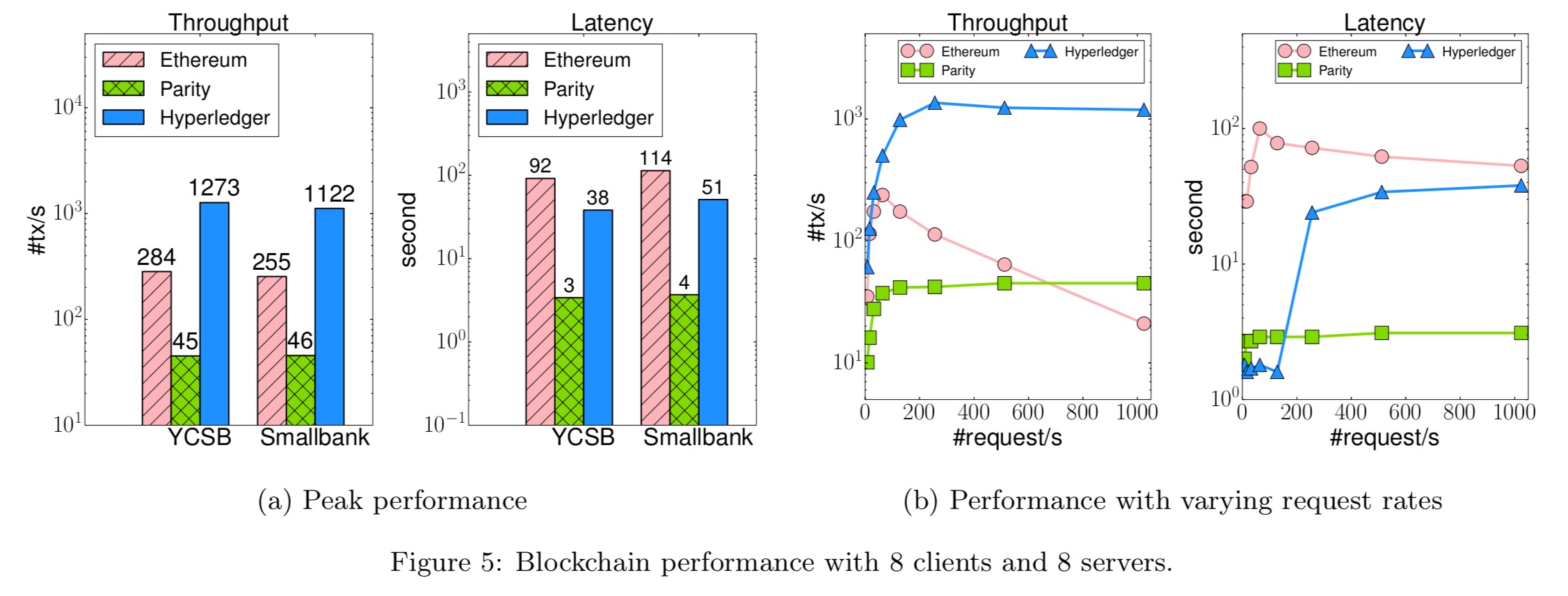
(Enlarge)
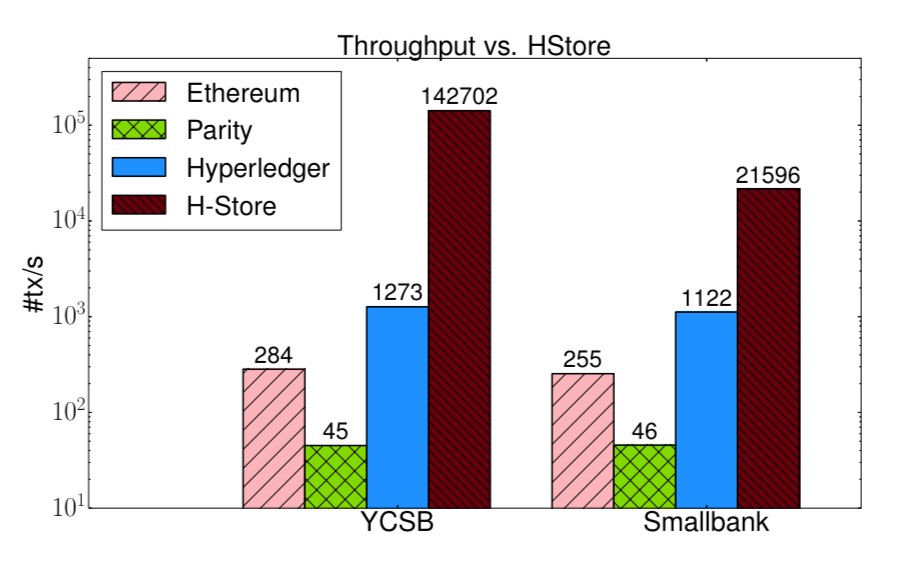
- Even so, you need to put the Hyperledger performance in context compared to for example the H-Store in-memory database (note the log scale!):
- Ethereum and Parity are more resilient to node failures, but they are vulnerable to security attacks that fork the blockchain.
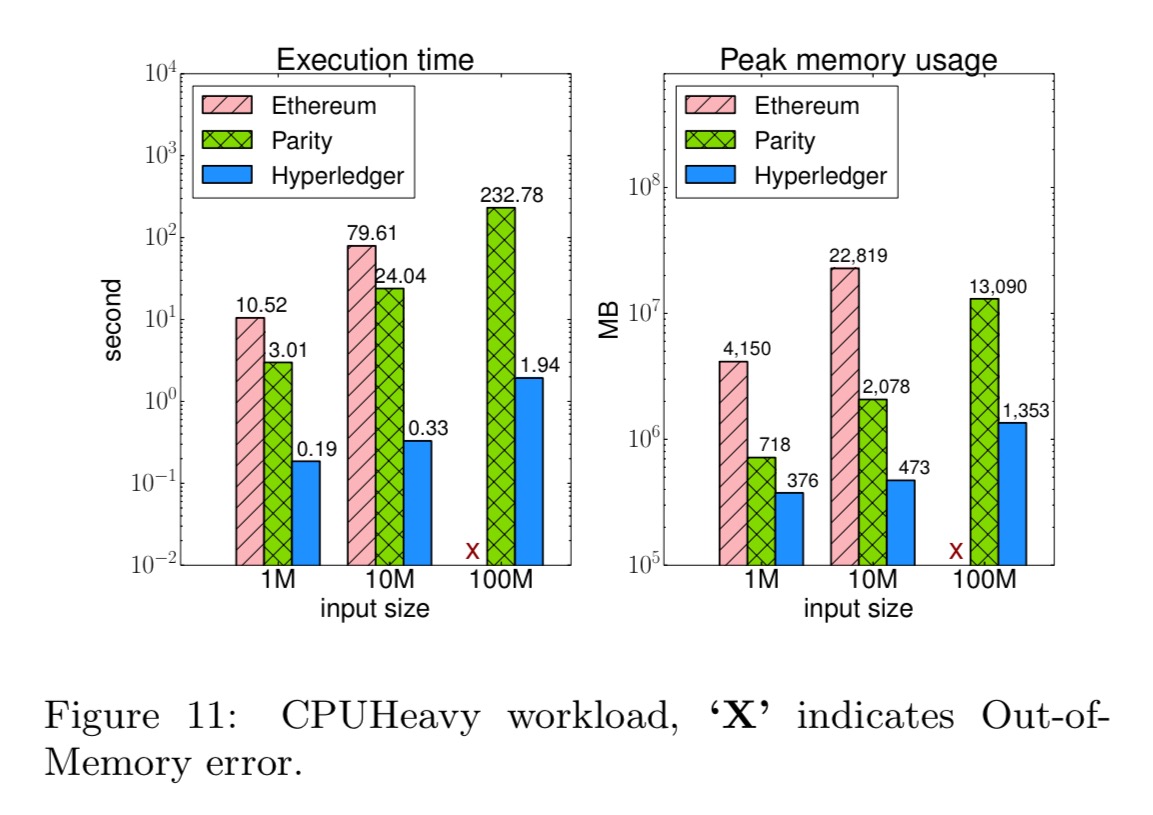
- The main bottlenecks in Hyperledger and Ethereum are the consensus protocols, but for Parity the bottleneck is caused by transaction signing.
- Ethereum and Parity incur large overhead in terms of memory and disk usage compared to Hyperledger (order of magnitude). Their execution engine is also less efficient than that of Hyperledger.
- Hyperledger’s data model is low level, but its flexibility enables customised optimisation for analytical queries of the blockchain data.
There is plenty more interesting detail behind these high-level findings, which you can read in section 4 of the paper.
Recommendations
Our experience in working with the three blockchain systems confirms the belief that in its current state blockchains are not yet ready for mass usage [for permissioned use cases / large-scale data processing workloads? – AC]. Both their designs and codebases are still being refined constantly, and there are no other established applications beyond crypto-currency.
The authors advocate four design principles from the world of database systems which they believe can help to address performance bottlenecks:
- Decouple the storage, execution engine, and consensus layer from each other and then optimise and scale them independently.
- Embrace new hardware primitives to boost performance
- Consider how the concept of sharding might be applied (research agenda)
- Support declarative languages for smart contracts, opening up opportunities for low-level optimisations that speed up contract execution.

{kind=link}
Reblogged this on Người Đến Từ Bình Dương.
Once you know what blockchain is and how it differs from Bitcoin, learn the difference between public and private blockchain.