Simple testing can prevent most critical failures: an analysis of production failures in distributed data-intensive systems Yuan et al. OSDI 2014
After yesterday’s paper I needed something a little easier to digest today, and ‘Simple testing can prevent most critical failures’ certainly hit the spot. Thanks to Caitie McCaffrey from whom I first heard about it. The authors studied 198 randomly sampled user-reported failures from five data-intensive distributed systems (Cassandra, HBase, HDFS, MapReduce, Redis). Each of these systems is designed to tolerate component failures and is widely used in production environments.
For each failure considered, we carefully studied the failure report, the discussion between users and developers, the logs and the code, and we manually reproduced 73 of the failures to better understand the specific manifestations that occurred.
There are a lot of really interesting findings and immediately applicable advice in this paper. But the best of all for me is the discovery that the more catastrophic the failure (impacting all users, shutting down the whole system etc.), the simpler the root cause tends to be. In fact:
Almost all catastrophic failures (48 in total – 92%) are the result of incorrect handling of non-fatal errors explicitly signalled in software.
And about a third of those (these are failures that brought down entire production systems remember) are caused by trivial mistakes in error handling. They could have been detected by simple code inspection without even requiring any specific knowledge of the system. Here are the three things you want to check for:
- Error handlers that ignore errors (or just contain a log statement). This example led to data loss in HBase:

- Error handlers with “TODO” or “FIXME” in the comment. This example took down a 4000-node production cluster:

- Error handlers that catch an abstract exception type (e.g. Exception or Throwable in Java) and then take drastic action such as aborting the system. This example brought down a whole HDFS cluster:

For these three scenarios, the authors built a static checking tool called Aspirator and used it to check some real world systems, including those in the study.
If Aspirator had been used and the captured bugs fixed, 33% of the Cassandra, HBase, HDFS, and MapReduce’s catastrophic failures we studied could have been prevented.
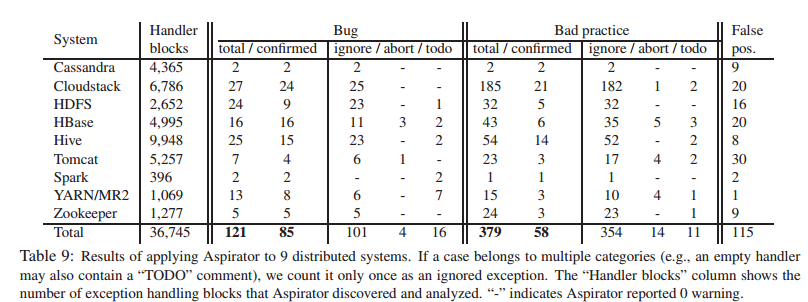
Using Aspirator to check the 9 systems shown in the table below found 500 new bugs and bad practices, along with 115 false-positives. 171 of these were reported as bugs back to developers, and as of the time the paper was published, 143 had been confirmed or fixed by the developers.
Another 57% of catastrophic failures caused by incorrect error handling do require some systems-specific knowledge to detect, but not a lot for a significant proportion of them…
In 23% of the catastrophic failures, while the mistakes in error handling were system specific, they are still easily detectable. More formally, the incorrect error handling in these cases would be exposed by 100% statement coverage testing on the error handling stage… once the problematic basic block in the error handling code is triggered, the failure is guaranteed to be exposed.
The final 34% of catastrophic failures do indeed involve complex bugs in error handling logic. These are much harder to systematically root out, but hey, getting rid of the other 2/3 of potentially catastrophe-inducing bugs is a pretty good start!
Other general findings
Failures are mostly easy to reproduce
A majority of the production failures (77%) can be reproduced by a unit test.
And if you do need a live system to reproduce a failure, you can almost certainly get away with a three-node system:
Almost all (98%) of the failures are guaranteed to manifest on no more than 3 nodes. 84% will manifest on no more than 2 nodes…. It is not necessary to have a large cluster to test for and reproduce failures.
Furthermore, most failures require no more than three input events to get them to manifest. 74% of them are deterministic – that is, they are guaranteed to happen given the right input event sequences.
The information you need is probably in the logs
Right next to that needle.
For a majority (84%) of failures, all of their triggering events are logged. This suggests that it is possible to deterministically replay the majority of failures based on the existing log messages alone.
The logs are noisy though, the median number of log messages printed by each failure was 824, and this is with a minimal configuration and a minimal workload sufficient to reproduce the failure.

Another great morning paper. I’m sure that the distributed systems in question have some type of delivery pipelines which would include some type of review steps/quality gates. What this highlights to me is that nothing is foolproof and human errors can never be completely eradicated. Tools such as SonarQube, IDE plugins, build tool plugins all flag up these issues but I guess we (developers) sometimes become blind to them. See something often enough and eventually you won’t see it. So, if developers are causing these issues then maybe the easiest solution would be better training/guidance.
Very nice article. I can clearly see my own experience in what is related.
Although the number of node was far lower, what I realised at this time was that développer wasn’t even aware of how their code scale on production platform.
I will also pass on the regular “it’s not possible” reply I used to get from them, which forced me to bring them in front of my terminal to explicitly show them real life production bug from their code.
Testing a database custom replication code with 100 entries in test suite, is really useless when same code has to deal with billion of entries in production env. Often having a test env at same scale than prod is impossible in term of cost and politics….