Asynchronous methods for deep reinforcement learning Mnih et al. ICML 2016
You know something interesting is going on when you see a scalability plot that looks like this:
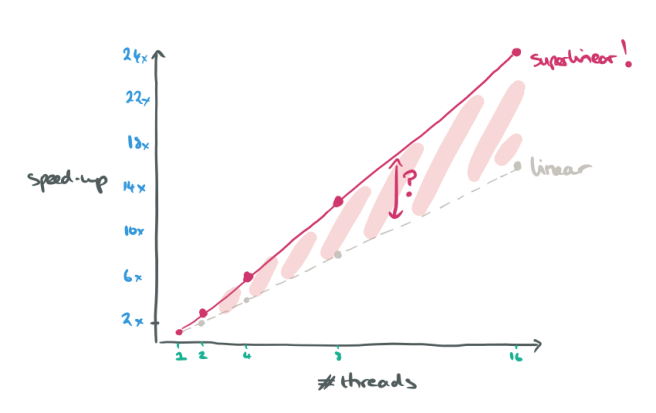
That’s a superlinear speedup as we increase the number of threads, giving a 24x performance improvement with 16 threads as compared to a single thread. The result comes from the Google DeepMind team’s research on asynchronous methods for deep reinforcement learning. In fact, of the four asynchronous algorithms that Mnih et al experimented with, the “asynchronous 1-step Q-learning” algorithm whose scalability results are plotted above is not the best overall. That honour goes to “A3C”, the Asynchronous Advantage Actor-Critic, which exhibits regular slightly sub-linear scaling as you add threads. How come it’s the best then? Because its absolute performance, as measured by how long it takes to achieve a given reference score when learning to play Atari games, is the best.
DeepMind’s DQN sytem is a Deep-Q-Network reinforcement learning system that learned to play Atari games. DQN relied heavily on GPUs. A3C beats DQN easily, using just CPUs:
When applied to a variety of Atari 2600 domains, on many games asynchronous reinforcement learning achieves better results, in far less time than previous GPU-based algorithms, using far less resource than massively distributed approaches.
Here you can see a comparison of the learning speed of the asynchronous algorithms vs DQN, with DQN trained on a single GPU, and the asynchronous algorithms trained using 16 CPU cores on a single machine.
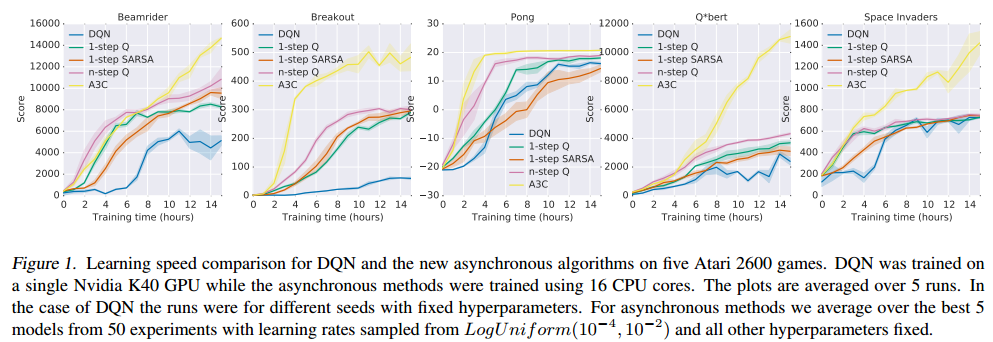
(Click for larger view)
And when it comes to overall performance levels achieved, look how well A3C does compared to many other state of the art systems, despite significantly reduced training times.
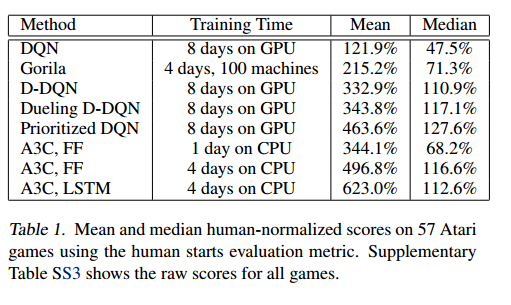
Let’s take a step back and explore what’s going on here.
Asynchronous learning
We’re talking about reinforcement learning systems, and in particular for the experiments conducted in this paper, reinforcement learning systems used to learn how to play Atari games (57 of them), drive a car in the TORCS car racing simulator:
Solve manipulation and locomotion problems in rigid-body physics domains:
And explore previously unseen 3D maze environments in the game Labyrinth:
We’ve looked at a few papers introducing asynchronous support to machine learning, including those that rely on convergence properties of particular algorithms. Last week we looked at Cyclades that parallelises large classes of machine learning algorithms across multiple CPUs.
Whereas those methods are variations on a theme of ‘do the same thing (or a very close approximation to the same thing), but in parallel’, the asynchronous methods here exploit the parallel nature of multiple threads to enable a different approach altogether. DQN and other deep reinforcement learning algorithms use experience replay, capturing an agent’s data which can subsequently be batched and/or sampled over different time-steps.
Deep RL algorithms based on experience replay have achieved unprecedented success in challenging domains such as Atari 2600. However, experience replay has several drawbacks: it uses more memory and computation per real interaction; and it requires off-policy learning algorithms that can update from data generated by an older policy.
Instead of experience replay, one of the key insights in this paper is that you can achieve many of the same objectives of experience replay by playing many instances of the game in parallel.
… we make the observation that multiple actor-learners running in parallel are likely to be exploring different parts of the environment. Moreover, one can explicitly use different exploration policies in each actor-learner to maximize this diversity. By running different exploration policies in different threads, the overall changes being made to the parameters by multiple actor-learners applying online updates in parallel are likely to be less correlated in time than a single agent applying online updates. Hence, we do not use a replay memory and rely on parallel actors employing different exploration policies to perform the stabilizing role undertaken by experience replay in the DQN training algorithm.
This explains the superlinear speed-up in training time required to reach a given level of skill: the more games are being explored in parallel, the better the training input to the network.
I really like this idea that the very nature of doing things in parallel opens up the possibility to use a fundamentally different approach. I don’t think that insight would naturally occur to me, and it makes me wonder if there are other scenarios where it might also apply. A
The algorithms
In reinforcement learning an agent interacts with an environment by taking actions and receiving a reward. At each time step the agent receives the state of the world and a reward score from the previous time step, and selects an action from some universe of possible actions. An action value function, typically represented as Q determines the expected reward for choosing a given action in a given state when following some policy π. There are two broad approaches to learning: value-based and policy-based.
In value-based model-free reinforcement learning methods the action value function is represented using a function approximation, such as a neural network…. In contrast to value-based methods, policy-based model-free methods directly parameterize the policy π(a|s;θ) and update the parameters θ by performing, typically approximate, gradient descent.
(a represents an action, s the state).
Because the parallel approach no longer relies on experience replay, it becomes possible to use ‘on-policy’ reinforcement learning methods such as Sarsa and actor-critic. The authors create asynchronous variants of one-step Q-learning, one-step Sarsa, n-step Q-learning, and advantage actor-critic. Since the asynchronous advantage actor-critic (A3C) algorithm appears to dominate all the others, I’ll just concentrate on that one.
A3C uses a ‘forward-view’ and n-step updates. Forward view means that the algorithm selects actions using its exploration policy for up to tmax steps in the future. The agent will then receive up to tmax rewards from the environment since its last update. The policy and value functions are then updated for each state-action pair and associated reward over the tmax steps. For each update, the algorithm use “the longest possible n-step return.” In other words, the update includes all steps up to and including the step we are currently performing the update for: a 2-step update for the second state-action, reward pair, a 3-step update for the third , and so on.
Here’s the pseudo-code for the algorithm, taken from the supplementary materials:

(V is a function that determines the value of some state s under policy π.)
We typically use a convolutional neural network that has one softmax output for the policy π(at|st;θ) and one linear output for the value function _V(st;θv), with all non-output layers shared.
Experiments
If you watch some of the videos I linked earlier you can see how well A3C learns to perform a variety of tasks. Playing Atari games has been well covered before. The TORCS car racing simulator is more challenging:
TORCS not only has more realistic graphics than Atari 2600 games, but also requires the agent to learn the dynamics of the car it is controlling…. A3C reached between roughly 75% and 90% of the score obtained by a human tester on all four game configurations in about 12 hours of training.
The Mujoco physics engine simulations required a reinforcement learning approach adapted to continuous actions, which A3C was able to do. It was tested on a number of manipulation and locomotion tasks, and found good solutions in less than 24 hours, and often just a few hours.
The final experiments used A3C on a new 3D maze environment called Labyrinth:
This task is much more challenging than the TORCS driving domain because the agent is faced with a new maze in each episode and must learn a general strategy for exploring random mazes… The final average score indicates that the agent learned a reasonable strategy for exploring random 3D mazes using only a visual input.
Closing thoughts
We’ve seen a number of papers showing how various machine learning tasks can be made more efficient in terms of elapsed training time by exploiting asynchronous parallel workers, as well as more efficient algorithms. There’s another kind of efficiency that’s equally important though: data efficiency, a concept that was much discussed at the recent London Deep Learning Summit. Data efficiency refers to the amount of data that an algorithm needs to achieve a given level of performance. Breakthroughs in data efficiency could have an even bigger impact than breakthroughs in computational efficiency.
And on the topic of computers learning to play games, since Go has now fallen, when will we see a reinforcement learning system beat the (human) champions in esports games too? That would make a great theatre for a battle :).

An unimportant question: what do you use for your drawings? They look cool!
Hi Victor,
I use Notability on an iPad Pro…
Regards, Adrian.
Excellent article, please keep it up. I am now a fan and you have made me very curious!
A few questions on my side (as a novice on these topics):
a) Learning: Is it really learning if it can only be applied to a certain game? These frameworks, rules, and etc are the implementation of humans leveraging computers (is anyone amazed nowadays that Excel can complete spreadsheets faster and more accurate than humans?) I believe this would answer the question of eSport games, yes eventually with enough computational power it should be able to respond in real-time?
b) Asynchronous parallel workers: Before multiple cores/threads, the ‘trick’ serial computers (developers) used to accomplished this task was by time splicing. Now, although multiple cores & speed are a vast improvement is it that appealing? Is it only impressive because it is running on a ‘fast’ supercomputer? Couldn’t a regular computer compute the same result but of course much slower? Is this interesting because it is more entertaining due to its near real-time nature?
c) Incentive: As long as computers don’t have a positive (change) / negative (neutral) feedback (does the program really care if it makes a mistake?)
Don’t mean to start off the wrong angle but would like to hear others opinions!