Graying the Black Box: Understanding DQNs – Zahavy et al. 2016
It’s hard to escape the excitement around deep learning these days. Over the last couple of days we looked at some of the lessons learned by Google’s machine learning systems teams, including the need to develop ways of getting insights into the predictions made by models. Today I’ve chosen a paper that combines these two themes, and tries to give insight into how a particular class of Deep Neural Networks do what they do. This is one of those papers where it feels like every other sentence reveals new levels of my own ignorance to me – but it’s packed with great references if you want to go deeper, and you have to start somewhere!
You may recall the news stories from last year describing how the Google Deep Mind team had built a machine learning system that learned to play Atari computer games, and was as good or better than a professional human player in many of them. The system uses something called reinforcement learning:
In the reinforcement learning (RL) paradigm, an agent autonomously learns from experience in order to maximize some reward signal. Learning to control agents directly from high-dimensional inputs like vision and speech is a hard problem in RL, known as the curse of dimensionality.
Deep Reinforcement Learning (DRL) applies Deep Neural Networks to reinforcement learning. The Deep Mind team used a DRL algorithm called Deep Q-Network (DQN) to learn how to play the Atari games. In ‘Graying the Black Box,’ Zahavy et al. look at three of those games – Breakout, Pacman, and Seaquest – and develop a new visualization and interaction approach that helps to shed insight on what it is that DQN is actually learning.
Similar to Neuro-Science, where reverse engineering methods like fMRI reveal structure in brain activity, we demonstrated how to describe the agent’s policy with simple logic rules by processing the network’s neural activity. This is important since often humans can understand the optimal policy and therefore understand what are the agent’s weaknesses. The ability to understand the hierarchical structure of the policy can help in distilling it into a simpler architecture. Moreover, we can direct learning resources to clusters with inferior performance by prioritized sampling.
The analogy to fMRI is very apt, since the pictures produced by their visualization tool look very much like pictures of brains to me! Are you ready to peer inside a deep mind…?
A little background
The learning agent is watching the video screen image produced by the game, trying actions and seeing what effect they have. Thus it can learn from spatial information (what’s on the screen, where is it), and also from temporal information (how does that change over time). The agent learns to take actions that give it a higher reward.
In contrast to other machine learning benchmarks that exhibit good localization, spatially similar states can often induce different control rules. Translation: this screen looks pretty similar to that other one you saw, but there’s one crucial difference you need to be aware of…
For example, in the Atari2600 game Seaquest, whether or not a diver has been collected (represented by a few pixels) controls the outcome of the submarine surface action (without – lose a life, with – fill air). Another cause for these discontinuities is that for a given problem, two states with similar representations may in fact be far from each other in terms of the number of state transitions required to reach one from the other…. Thus, methods that focus on the temporal structure of the policy have been proposed. Such methods decompose the learning task into simpler subtasks using graph partitioning.
To visualise what is going on in the network, the authors use a high-dimensional data visualization technique called t-SNE which maps each data point to a location in a two or three dimensional map.
The technique is relatively easy to optimize, and reduces the tendency to crowd points together in the center of the map by employing a heavy tailed Student-t distribution in the low dimensional space. It is known to be particularly good at creating a single map that reveals structure at many different scales, which is particularly important for high-dimensional data that lie on several different, but related, low-dimensional manifolds. There~~fore we can visualize the different sub-manifolds learned by the network and interpret their meaning.
MRI for DQN
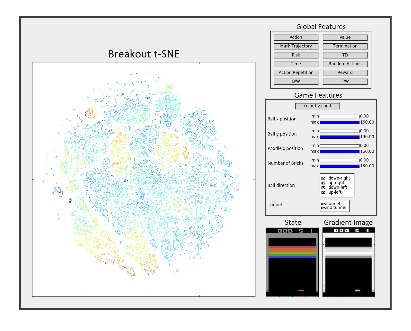
Here’s a picture of the tool in action. On the left-hand side you see the t-SNE visualisation, and on the right-hand side you have tool for visualising global features (top), game specific features (middle), and the chosen state and its corresponding gradient image (bottom). (Here we’re playing Breakout).
Saliency maps help to understand which pixels in the input image affect the value prediction the most:

We assign each state with its measure such as value estimates (value, Q, advantage), generation time, termination, (decide how to show the gui and detail all measure we use), and use it to color the t-SNE map. We also extract hand-crafted features, directly from the emulator raw frames, such as player position, enemy position, number of lives, and so on. We use these features to filter points in the t-SNE image. The filtered images reveal insightful patterns that cannot be seen otherwise…. we use a 3d t-SNE state representation and display transitions upon it with arrows using Mayavi (Ramachandran & Varoquaux, 2011).
How DQN plays Breakout, Pacman, and Seaquest…
The authors argue that ‘DQN is learning a hierarchical spatio-temporal aggregation of the state space using different sub manifolds to represent the policy – thus explaining its success (!).’ Translation: it’s using different parts of the network to represent different states – arranged in a hierarchy – that center around what’s on the screen and/or what’s happening in a time sequence.
If you’ve never played breakout before, the essence of the game is that you bounce a ball off of a paddle at the bottom of the screen (which you can move left-to-right to meet the ball) such that the ball collides with a wall of bricks at the top of the screen. Once the ball has hit a brick a certain number of times, the brick disappears. The goal is to clear the screen. A good strategy is to dig a tunnel through the bricks so that the ball can get to the top of the screen (which it bounces back from) – this allows the ball to bounce repeatedly between the top of the wall and the top of the screen, destroying bricks at no risk to the player.
Here’s a DQN ‘brain’ on breakout:

The agent learns a hierarchical policy: first carve a tunnel in the left side of the screen and then keep the ball above the bricks as long as possible. In clusters (1-3) the agent is carving the left tunnel. Once the agent enters those clusters it will not leave them until the tunnel is carved, thus, we define them as a landmark option.

The clusters are separated from each other by the ball position and direction. In cluster 1 the ball is heading toward the tunnel, in cluster 2 the ball is at the right side and in cluster 3 the ball bounces back from the tunnel after hitting bricks. As less bricks remain in the tunnel the value is gradually rising till the tunnel is carved and the value is maximal (this makes sense since the agent is enjoying high reward rate straight after reaching it). Once the tunnel is carved, the option is terminated and the agent moves to clusters 4-7 (dashed red line), sorted by the ball position with regard to the bricks. Again the clusters are distinguished by the ball position and direction. In cluster 4 and 6 the ball is above the bricks and in 5 it is below them. Clusters 8 and 9 represent termination and initial states respectively.
Cluster 7 is interesting because it exploits a bug in the game! This permits the ball to pass through a tunnel without the tunnel being completely cleared in some situations. The agent learned to represent this and to assign it high reward – which proves it is learning based on game dynamics (temporal) and not just on what it sees on the screen (the state of the pixels).
I found it quite easy to get caught up in the description of how to play the game (‘well, of course that’s how you play breakout…’) and forget what’s really happening here. As a reminder:
- We start out with a learning agent that has never seen Breakout before
- It figures out for itself an effective strategy for playing the game
- That strategy is embodied in a DQN – which just a black box full of meaningless coefficients from a human understanding perspective
- Using their DQN MRI tool the authors were able to make sense of regions in the network (sub-manifolds) that had specialized to handle certain states, and how those regions were connected.
- From this, they were able to infer the learned logical rules that inform the DQNs gameplay strategy.
This is important since often humans can understand the optimal policy and therefore understand what are the agent’s weaknesses. The ability to understand the hierarchical structure of the policy can help in distilling it into a simpler architecture. Moreover, we can direct learning resources to clusters with inferior performance by prioritized sampling.
In the case of playing Breakout of course, another way to learn the agent’s strategy is to watch it playing Breakout! But that would be an exterior understanding, missing an understanding of how the DQN facilitates that strategy. Thanks to this understanding we can begin to appreciate not only that Deep Reinforcement Learning systems work, but also how they work.
If you’re interested in knowing the strategies the DQN learned for playing Pacman and Seaquest, see the full paper for details.
Our experiments on ALE (Atari Learning Environment) indicate that the features learned by DQN map the state space to different sub-manifolds, in each, different features are present. By analyzing the dynamics in these clusters and between them we were able to identify hierarchical structures. In particular we are able to identify options with defined initial and termination rules. The states aggregation gives the agent the ability to learn specific policies for the different regions, thus giving an explanation to the success of DRL agents.
If you’re interested in learning more about Google’s Deep Mind, the team at Snips.ai just published an excellent blog post and open source library reproducing the Deep Mind ‘Neural Turing Machines‘ paper. I’ll look into covering that sometime soon on The Morning Paper.

I enjoyed reading this paper. I was a bit surprised it got in ICML given that it’s of a different flavor/style, but it certainly provided me with intuition on t-SNE and what the agent might be learning.