Playing FPS games with deep reinforcement learning Lample et al. arXiv preprint, 2016
When I wrote up ‘Asynchronous methods for deep learning’ last month, I made a throwaway remark that after Go the next challenge for deep learning systems would be to win an esports competition against the best human teams. Can you imagine the theatre!

Source: ‘League of Legends’ video game championship is like the World Cup, Super Bowl combined – Fortune: http://fortune.com/2015/10/29/league-of-legends-video-game-championship/
Since those are team competitions, it would need to be a team of collaborating software agents playing against human teams. Which would make for some very cool AI technology.
Today’s paper isn’t quite at that level yet, but it does show that progress is already being made on playing first-person shooter (FPS) games in 3D environments.
In this paper, we tackle the task of playing an FPS game in a 3D environment. This task is much more challenging than playing most Atari games as it involves a wide variety of skills, such as navigating through a map, collecting items, recognizing and fighting enemies, etc. Furthermore, states are partially observable, and the agent navigates a 3D environment in a first-person perspective, which makes the task more suitable for real-world robotics applications.
Lample and Chaplot develop an AI agent for playing death matches. I’m not really an FPS kind of person, and had no idea what a deathmatch was. It turns out to be a scenario in which the objective is to maximize the number of kills by a player/agent. Nice. The agent uses separate neural networks for navigation tasks and for action tasks. Experimentation is done using the VizDoom framework for developing AI bots that play Doom. It turns out there’s even been a recent VizDoom competition, with the ‘full deathmatch’ category won by a team from Intel Labs. Here’s a video of their entry in action:
Deep Recurrent Q-Networks
The core of the system is built on a DRQN architecture (Deep Recurrent Q-Network). A regular Deep-Q network, such as that used to play Atari games, receives a full (or very close to full) observation of the environment at each step. But in a game like DOOM where agent’s field of view is limited to 90 degrees centred around its position it only receives a partial observation.
In 2015 Hausknecht and Stone introduced Deep Recurrent Q-Networks which include an extra parameter at each step representing the hidden state of the agent. This can be accomplished by layering a recurrent neural network such as an LSTM on top of a normal DNQ network.
Two models
In a deathmatch, you need to explore the map to collect items and find enemies, and then you need to fight enemies when you find them. Lample and Chaplot use two networks, one for navigation, and one for action. The current phase of the game (and hence which model to use at any given time) is determined by predicting whether or not an enemy is visible in the current frame (action model if so, navigation model otherwise).
There are various advantages of splitting the task into two phases and training a different network for each phase. First, this makes the architecture modular and allows different models to be trained and tested independently… Furthermore, the navigation phase only requires three actions (move forward, turn left, and turn right), which dramatically reduces the number of state-action pairs required to learn the Q-function and makes training much faster. More importantly, using two networks also mitigates ‘camper’ behaviour, i.e. the tendency to stay in one area of the map and wait for enemies, which was exhibited by the agent when we tried to train a single DQN or DRQN for the deathmatch task.
Training
When trained using a vanilla DRQN approach, agents tended either to fire at will, hoping for enemies to wander into their crossfire, or not fire at all when given a penalty for using ammunition. This is because the agent could not effectively learn to detect enemies. To address this, the team gave the agent additional information that it could use during training (but not during actual gameplay or testing). At each training step, in addition to receiving a video frame, the agent received a boolean value for each entity (enemy, health pack, weapon, ammo and so on) indicating whether or not it appeared in the frame.
We modified the DRQN architecture to incorporate this information and to make it sensitive to game features. In the initial model, the output of the CNN is given to a LSTM that predicts a score for each action based on the current frame and its hidden state. We added two fully-connected layers of size 512, and k-connected to the output of the CNN, where k is the number of game features we want to detect… Although a lot of game information was available, we only used an indicator about the presence of enemies on the current frame.
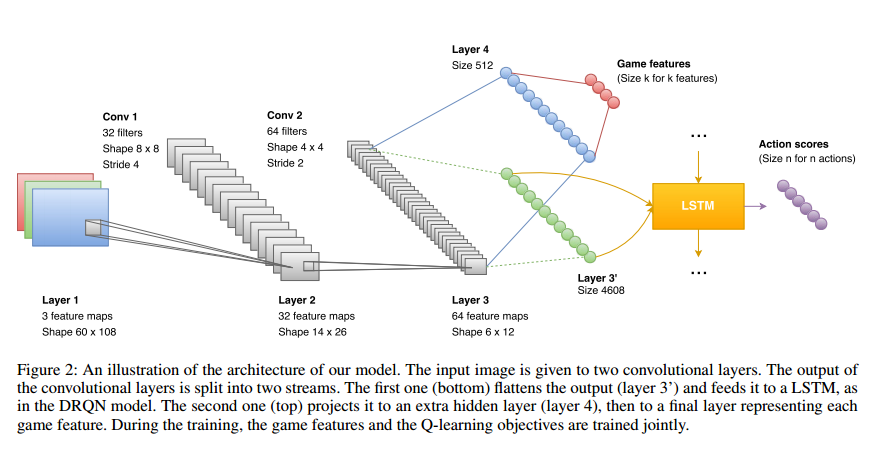
Jointly training the DRQN model and the game feature detection allows the kernels of the convolutional layers to capture relevant information about the game with only a few hours of training needed to reach an optimal enemy detection accuracy of 90%.
The reward function for the action network includes:
- positive rewards for kills
- negative rewards for suicides
- positive rewards for picking up objects
- negative rewards for losing health
- negative rewards for shooting or losing ammo
The navigation network was simply given a positive reward for picking up an item, and a negative reward for walking on lava.
A frame-skip of 4 turned out to be best overall balance between training speed and performance (the agent receives a screen input every 4+1 frames, and the action decided by the network is repeated over all the skipped frames). During back-propagation, only action states with enough history to give a reasonable estimation are updated.
Fighting! (evaluation)
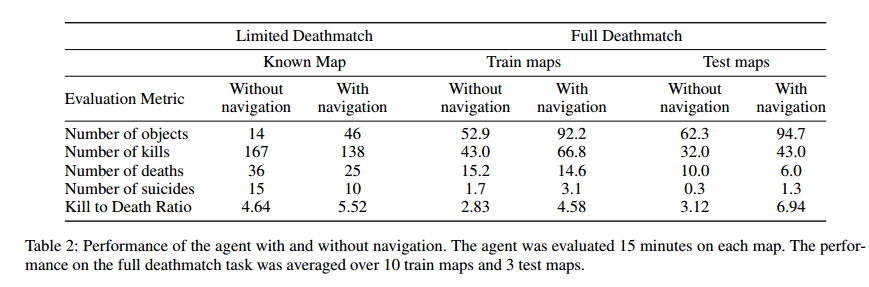
Evaluation is done using the delightful kill to death ratio (K/D) as the scoring metric. Table 2 below shows how well the agent performed both on known maps (limited deathmatch) and on unknown maps (full deathmatch).
You can watch the agent play in these videos.
Here’s how it stacks up against human opposition:

The authors conclude:
In this paper, we have presented a complete architecture for playing deathmatch scenarios in FPS games. We introduced a method to augment a DRQN model with high-level game information, and modularized our architecture to incorporate independent networks responsible for different phases of the game. These methods lead to dramatic improvements over the standard DRQN model when applied to complicated tasks like a deathmatch. We showed that the proposed model is able to outperform built-in bots as well as human players and demonstrated the generalizability of our model to unknown maps. Moreover, our methods are complementary to recent improvements in DQN, and could easily be combined with dueling architectures (Wang, de Freitas, and Lanctot 2015), and priorized replay (Schaul et al. 2015).

I’m a little bit confusing about how the navigation network and the action network are separated. Is it like they used two separated LSTMs for navigation and action control?