Achieving Human Parity in Conversational Speech Recognition Xiong et al. Microsoft Technical Report, 2016
The headline story here is that for the first time a system has been developed that exceeds human performance in one of the most difficult of all human speech recognition tasks: natural conversations held over the telephone. This is known as conversational telephone speech, or CTS.
[CTS] is especially difficult due to the spontaneous (neither read nor planned) nature of the speech, its informality, and the self-corrections, hesitations, and other disfluencies that are pervasive.
The reference datasets for this task are the Switchboard and Fisher data collections from the 1990s and early 2000s. The apocryphal story here is that human performance on the task is about 4% error rate. But no-one can quite pin down where that 4% number comes from. So the Microsoft team took advantage of an existing professional transcription service used by Microsoft:
To measure human performance, we leveraged an existing pipeline in which Microsoft data is transcribed on a weekly basis. This pipeline uses a large commercial vendor to perform a two-pass transcription. In the first pass, a transcriber works from scratch to transcribe the data. In the second pass, a second listener monitors the data to do error correction. Dozens of hours of test data are processed in each batch. One week, we added the NIST 2000 CTS evaluation data to the work-list, without further comment…
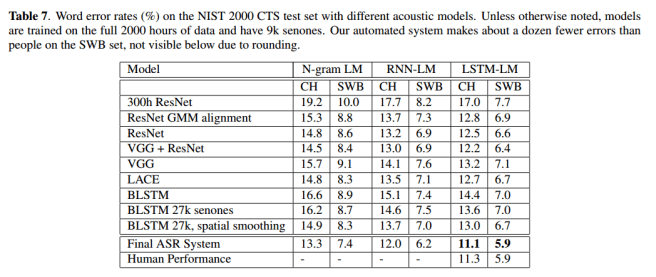
For the switchboard portion of the dataset, the professional human transcribers achieved a 5.9% error rate, and for the ‘call-home’ portion of the test set 11.3%. “The same informality, multiple speakers per channel, and recording conditions that make CallHome hard for computers make it difficult for people as well.”
Notably, the performance of our artificial system aligns almost exactly with the performance of people on both sets.
And so one can’t help but wonder how much longer those professional transcribers will continue to be needed! Did they know they were gathering the evidence that one day might help lead to the elimination of their jobs???
Here’s a table full of cryptic acronyms that show the performance of the system that Microsoft put together, using various acoustic models. The bottom-line (strictly, bottom two lines) is what matters here: parity on the switchboard dataset, and a slight advantage for the ASR (Automatic Speech Recognition) system of the CallHome dataset.
How did the Microsoft team manage to pull this off?
Our system’s performance can be attributed to the systematic use of LTSMs for both acoustic and language modeling, as well as CNNs in the acoustic model, and extensive combination of complementary models.
Training was made feasible (reducing times from month to 1-3 weeks) by using Microsoft’s CNTK Cognitive Toolkit to parallelize SGD training, coupled with the use of the 1-bit SGD parallelization techique from prior work:
In [65], we showed that gradient values can be quantized to just a single bit, if one carries over the quantization error from one minibatch to the next. Each time a sub-gradient is quantized, the quantization error is computed and remembered, and then added to the next minibatch’s sub-gradient. This reduces the required bandwidth 32-fold with minimal loss in accuracy.
How it works under the covers
The model details are concisely explained, targeting an audience of speech recognition experts (i.e. not me!). It is still possible for a lay-reader to gain some appreciation of what’s involved though. It’s also another reminder that we’re rapidly assembling a powerful collection of building blocks that through good systems engineering can be combined into very effective systems. Expect to see an explosion of applied AI/ML/whatever-your-preferred-phrase-is applications as this trend continues.
Our progress is a result of the careful engineering and optimization of convolutional and recurrent neural networks. While the basic structures have been well known for a long period, it is only recently that they have emerged as the best models for speech recognition. Surprisingly, this is the case for both acoustic modeling and language modeling.
The CNN and RNN based acoustic models can model a large amount of acoustic context with temporal invariance, and in the case of CNNs, with frequency invariance as well. In language modeling, RNNs improve on classical N-gram models through the use of an unbounded word history and the generalization ability of continuous word representations.
The paper describes a whole family of systems that were explored in order to find the best performing combination. The best acoustic model was formed by combining independently trained ResNet and VGG models using a score fusion weight.
‘VGG’ stands for the University of Oxford Visual Geometry Group and the architecture they developed in “Very deep convolutional networks for large-scale visual recognition”. Their networks use 16-19 layers with small 3×3 filters in all convolutional layers. The ResNet architecture is also borrowed from the field of image recognition.
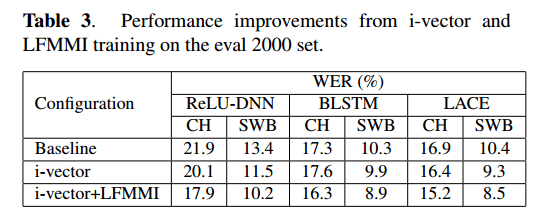
Speaker adaptive modeling is then applied by conditioning the network on an i-vector characterization of each speaker using 100-dimensional i-vectors. The i-vectors are added to the activation of each CNN layer via a learnable weight matrix.
After initial training, model parameters are optimized using a maximum mutual information (MMI) objective function:
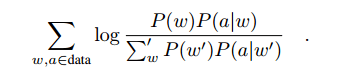
where w is a word sequence, and a is an acoustic realization of a word sequence. The performance improvements obtained from this lattice-free MMI (LFMMI) training phase, as well as i-vectors, can be seen in the following table:
An initial decoding of acoustic model outputs is done with a WFST (Weighted Finite State Transducer) decoder.
We use an N-gram language model trained and pruned with the SRILM toolkit. The first-pass LM has approximately 15.9 million bigrams, trigrams, and 4-grams, and a vocabulary of 30500 words, and give a perplexity of 54 on RT-03 speech transcripts.
The N-best performing hypotheses from the WFST decoding are then rescored using a combination of a large N-gram language model and neural net language models. The best performing language model used LTSMs with three hidden layers, and 1000 hidden units in each layer. “For the final system, we interpolated two LSTM-LMs with an N-gram LM for the forward direction LM, and similarly for the backward direction LM.”

“achieved 5.9% accuracy and … 11.3% accuracy”? I think you meant “achieved 5.9% error rate and … 11.3% error rate”.
I certainly did, thank you! Post updated …