Smart Reply: Automated response suggestion for email Kannan, Kaufman, Karach, et al. KDD 2016
I’m sure you’ve come across (or at least heard of) Google Inbox’s smart reply feature for mobile email by now. It’s currently used for 10% of all mobile replies, which must equate to a very large number of messages per day. In today’s paper choice, the team that built the Smart Reply system tell us how it works. It’s a very approachable paper, and illustrative of the difference between pure research and what it takes to put a machine learning system into production at scale. I hope we see many more ‘applied AI’ papers of this ilk over time.
At its core, generating a smart reply is a straightforward (?) sequence-to-sequence learning problem. You feed in a sequence of tokens from the input email, and generate a sequence of tokens for the output. Train the model over a corpus of messages with associated replies, and voila! (Google’s training set comprised 238 million messages, 153 million of which had no response). That much will get you a great demonstration system, and perhaps if you find something novel along the way, a research paper.
If you want to deploy that model into a product used globally by millions of people though, there are a few other considerations:
- How do you ensure that the individual response options are always high quality in language and content (would you want Tay to be suggesting replies for you???)
- How do you present response options that capture diverse intents to maximise utility of the feature? (As opposed to just three syntactic variants of replies with the same meaning).
- How do make it work within the latency constraints of a high-volume email delivery system?
- How do you build and test the system without ever inspecting raw email data beyond aggregate statistics?
On that last challenge, we don’t really get any information, beyond the disclosure that:
… all email data (raw data, preprocessed data and training data) was encrypted. Engineers could only inspect aggregated statistics on anonymized sentences that occurred across many users and did not identify any user. Also, only frequent words are retained. As a result, verifying [the] model’s quality and debugging is more complex.
Let’s walk through the email delivery flow and see how the team solved these challenges.
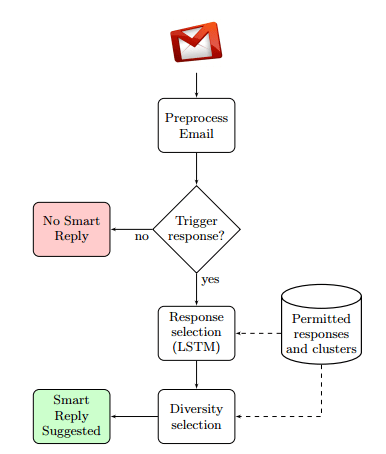
Pre-processing
An incoming email message is pre-processed before being fed into the Smart Reply pipeline. Pre-processing includes:
- Language detection (non-English messages are discarded at this point, sorry).
- Tokenization of subject and message body
- Sentence segmentation
- Normalization of infrequent words and entities – these are replaced by special tokens
- Removal of quoted and forward email portions
- Removal of greeting and closing phrases (“Hi John”,… “Regards, Mary”)
Filtering (smart triggering)
Computing smart replies is computationally expensive (in the context of mass email delivery), so we only want to do it when we have a chance of generating meaningful replies that are likely to be used. Applying the fail-fast principle, the next step on an email’s journey is the triggering module, whose job it is to decide whether or not to attempt to create smart replies at all. This decision can be made faster and cheaper than full reply generation. Bad candidates for reply generation include emails unsuitable for short replies (open-ended questions, sensitive topics…), and those for which no reply is necessary (promotional emails etc.).
Currently, the system decides to produce a Smart Reply for roughly 11% of messages, so this process vastly reduces the number of useless suggestions seen by the users.
The triggering component is implemented as a feed-forward neural network (multilayer perceptron with an embedding layer that can handle a vocabulary of roughly one million words, and three fully connected hidden layers). Input features include those extracted in the preprocessing step together with various social signals such as whether the sender is in the recipient’s address book or social network, and whether the recipient has previously sent replies to the sender. The training corpus of emails is also labelled to indicate those which had a response and those which did not.
If the probability score output by the triggering component is greater than a pre-determined threshold, then the email is sent to the core smart reply system for response generation.
Initial response selection
At the core of the smart reply system is an sequence-to-sequence LSTM. The input is the tokens from the original message, and the output is a conditional probability distribution over response tokens.
First, the sequence of original message tokens, including a special end-of-message token on, are read in, such that the LSTM’s hidden state encodes a vector representation of the whole message. Then, given this hidden state, a softmax output is computed and interpreted as P(r1|o1, …, on), or the probability distribution for the first response token. As response tokens are fed in, the softmax at each timestep t is interpreted as P(rt|o1, …, on, r1, …, rt−1). Given the factorization above, these softmaxes can be used to compute P(r1, …, rm|o1, …, on).
The output is not used to generate a response, but to select a specific response candidate from among a (large) set of pre-vetted responses. Since the model is trained on real messages, unexpected or inappropriate responses could be generated if the model is given a free-hand.
Given that the model is trained on a corpus of real messages, we have to account for the possibility that the most probable response is not necessarily a high quality response. Even a response that occurs frequently in our corpus may not be appropriate to surface back to users. For example, it could contain poor grammar, spelling, or mechanics (your the best!); it could convey a familiarity that is likely to be jarring or offensive in many situations (thanks hon!); it could be too informal to be consistent with other Inbox intelligence features (yup, got it thx); it could convey a sentiment that is politically incorrect, offensive, or otherwise inappropriate (Leave me alone).
We’ll come onto how the response set is generated (up-front) in a moment. For now, let’s just assume we have a set of candidate responses (10 million or so) that we want to score. This requires a searching and scoring mechanism that is not a function of the size of the response set! The solution is to organise the elements of the response into a trie, and then use a beam search to explore hypotheses that appear in the trie.
This search process has complexity O(bl) for beam size b and maximum response length l. Both b and l are typically in the range of 10-30, so this method dramatically reduces the time to find the top responses and is a critical element of making this system deployable. In terms of quality, we find that, although this search only approximates the best responses in R, its results are very similar to what we would get by scoring and ranking all r ∈ R, even for small b. At b = 128, for example, the top scoring response found by this process matches the true top scoring response 99% of the time.
Ensuring diversity in responses

At this point we have an ordered list of possible responses, but it doesn’t make sense to just take the top three (Smart Reply only shows the user three options). It’s quite likely there is redundancy in the possible replies, e.g. three variations of “I’ll be there.”
The job of the diversity component is to select a more varied set of suggestions using two strategies: omitting redundant responses and enforcing negative or positive responses.
Candidate replies in the response set are clustered by intents (as described next). Responses are added to the list of suggestions with the highest scoring responses added first, but a response is not added to the list if it already contains another response from the same intent cluster. In this way, we get the highest scoring response from each intent.
We have observed that the LSTM has a strong tendency towards producing positive responses, whereas negative responses such as I can’t make it or I don’t think so typically receive low scores. We believe that this tendency reflects the style of email conversations: positive replies may be more common, and where negative responses are appropriate, users may prefer a less direct wording. Nevertheless, we think that it is important to offer negative suggestions in order to give the user a real choice.
The way this is done is very straightforward: responses are classified as positive, neutral, or negative. If the top two responses contain at least one positive response, and no negative response, then the third response is replaced with a negative one. (The same logic is also applied in reverse in the rarer case of exclusively negative responses).
Generating the response set in the first place
Response set generation begin swith anonymised short response sentences from the pre-processed training data, yielding a few million unique sentences. These are parsed used a dependency parser and the resulting syntatic structure is used to generate a canonicalised representation. For example, “Thanks for your kind update”, “Thank you for updating!”, and “Thanks for the status update” may all get mapped to “Thanks for the update.”
At the next step response are clustered into semantic clusters where each represents an intent. The process is seeded with a few manually defined clusters sampled from the top frequent messages.
We then construct a base graph with frequent response messages as nodes (VR). For each response message, we further extract a set of lexical features (ngrams and skip-grams of length up to 3) and add these as “feature” nodes (VF) to the same graph. Edges are created between a pair of nodes (u, v) where u ∈ VR and v ∈ VF if v belongs to the feature set for response u.
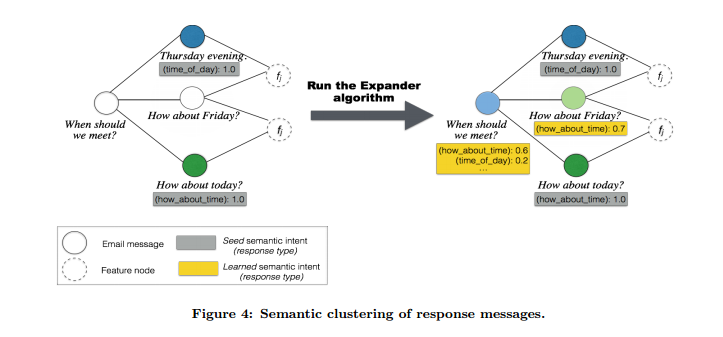
From this graph a semantic labelling is learned using the EXPANDER framework. The top scoring output label for a given node is assigned as the node’s semantic intent. The algorithm is run over a number of iterations, each time introducing another batch of randomly sampled new responses from the remaining unlabeled nodes in the graph. Finally, the top k members for each semantic cluster are extracted, sorted by their label scores.
The set of (response, cluster label) pairs are then validated by human raters… The result is an automatically generated and validated set of high quality response messages labeled with semantic intent.
In production
The most important end-to-end metric for our system is the fraction of messages for which it was used. This is currently 10% of all mobile replies.
The Smart Reply system generates around 12.9k unique suggestions each day, that collectively belong to about 380 semantic clusters. 31.9% of the suggestions actually get used, from 83.2% of the clusters. “These statistics demonstrate the need to go well beyond a simple system with 5 or 10 canned responses.” Furthermore, out of all used suggestions, 45% were from the 1st position, 35% from the 2nd position, and 20% from the third position.
Since usually the third position is used for diverse responses, we conclude that the diversity component is crucial for the system quality.

If you need some kind of research paper help or if you got any questions you can just ask me , i’m very good in this field like in any other