Sequence to sequence learning with neural networks Sutskever et al. NIPS, 2014
Yesterday we looked at paragraph vectors which extend the distributed word vectors approach to learn a distributed representation of a sentence, paragraph, or document. Today’s paper tackles what must be one of the sternest tests of all when it comes to assessing how well the meaning of a sentence has been understood: machine translation. Working with an input vocabulary of 160,000 English words, Sutskever et al. use an LSTM model to turn a sentence into 8000 real numbers. Those 8000 real numbers embody the meaning of the sentence well enough that a second LSTM can produce a French sentence from them. By this means English sentences can be translated into French. The overall process therefore takes a sequence of (English word) tokens as input, and produces another sequence of (French word) tokens as output. Thus the technique is called sequence-to-sequence learning.
Despite their flexibility and power, DNNs can only be applied to problems whose inputs and targets can be sensibly encoded with vectors of fixed dimensionality. It is a significant limitation, since many important problems are best expressed with sequences whose lengths are not known a-priori. For example, speech recognition and machine translation are sequential problems. Likewise, question answering can also be seen as mapping a sequence of words representing the question to a sequence of words representing the answer. It is therefore clear that a domain-independent method that learns to map sequences to sequences would be useful.
The Long Short-Term Memory architecture proves to be up to the task.
The idea is to use one LSTM to read the input sequence, one timestep at a time, to obtain large fixed-dimensional vector representation, and then to use another LSTM to extract the output sequence from that vector (fig. 1). The second LSTM is essentially a recurrent neural network language model except that it is conditioned on the input sequence. The LSTM’s ability to successfully learn on data with long range temporal dependencies makes it a natural choice for this application due to the considerable time lag between the inputs and their corresponding outputs.
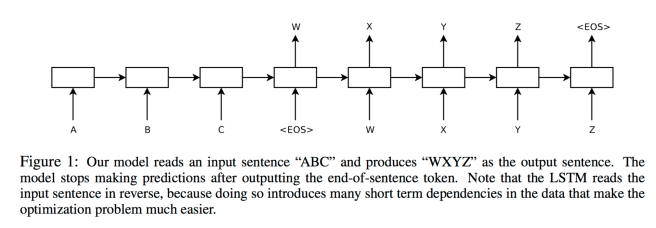
One of the key technical contributions of the work, as stated by the authors themselves, is something that anyone can easily understand. When feeding the input sentence into the encoding LSTM, they discovered that the end-to-end process works much better if the sentence is input in reverse word order.
While we do not have a complete explanation to this phenomenon, we believe that it is caused by the introduction of many short term dependencies to the dataset. Normally, when we concatenate a source sentence with a target sentence, each word in the source sentence is far from its corresponding word in the target sentence. As a result, the problem has a large “minimal time lag”. By reversing the words in the source sentence, the average distance between corresponding words in the source and target language is unchanged. However, the first few words in the source language are now very close to the first few words in the target language, so the problem’s minimal time lag is greatly reduced. Thus, backpropagation has an easier time “establishing communication” between the source sentence and the target sentence, which in turn results in substantially improved overall performance.
The beneficial effects apply not just to the early parts of the target sentence, but also to long sentences.
The authors built deep LSTMs with 4 layers of 1000 cells, and 1000-dimensional word embeddings, an input vocabulary of 160,000 words, and an output vocabularly of 80,000 words. “Thus the deep LSTM uses 8000 real numbers to represent a sentence.” Deep LSTMs outperformed shallow ones, reducing ‘perplexity’ by nearly 10% with each additional layer. A naive softmax over the 80,000 words is used at each output. “The resulting LSTM has 384M parameters, of which 64M are pure recurrent connections.”
For training, each layer resides on a separate GPU, with another 4 GPUs used to parallelize the softmax. This configuration achieved a speed of 6,300 words per second and training took about 10 days. The model was trained on the WMT ’14 English to French translation task and evaluated using the BLEU algorithm to produce a BLEU score. BLEU achieves high correlation with human judgements of quality.
The main result of this work is the following. On the WMT’14 English to French translation task, we obtained a BLEU score of 34.81 by directly extracting translations from an ensemble of 5 deep LSTMs (with 384M parameters and 8,000 dimensional state each) using a simple left-to-right beam-search decoder. This is by far the best result achieved by direct translation with large neural networks. For comparison, the BLEU score of an SMT (Statistical Machine Translation) baseline on this dataset is 33.30. The 34.81 BLEU score was achieved by an LSTM with a vocabulary of 80k words, so the score was penalized whenever the reference translation contained a word not covered by these 80k. This result shows that a relatively unoptimized small-vocabulary neural network architecture which has much room for improvement outperforms a phrase-based SMT system.
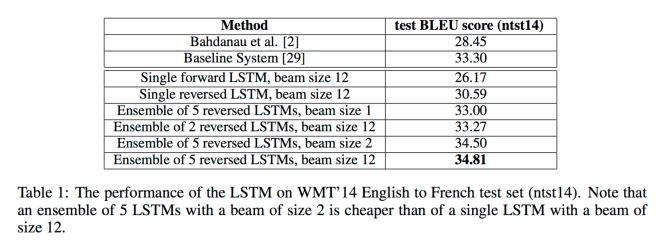
The best results are obtained with an ensemble of LSTMs each differing in their random initializations and order of mini-batches.
(The best overall WMT’14 result was 37.0, using a method that combines neural networks and an SMT system.)
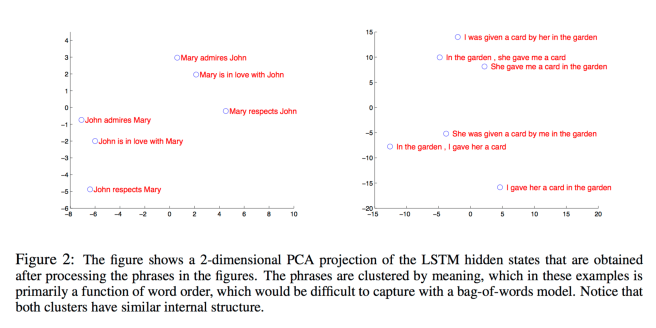
A PCA projection of the LSTM hidden states shows that phrases are indeed clustered by meaning:
At the start of this review, I said that translation must be one of the toughest tests of whether or not a representation has captured the meaning of a sentence. So how does sequence-to-sequence learning do?
A useful property of the LSTM is that it learns to map an input sentence of variable length into a fixed-dimensional vector representation. Given that translations tend to be paraphrases of the source sentences, the translation objective encourages the LSTM to find sentence representations that capture their meaning, as sentences with similar meanings are close to each other while different sentence meanings will be far. A qualitative evaluation supports this claim, showing that our model is aware of word order and is fairly invariant to the active and passive voice.


The article says, regarding comparing source sentences with _reversed_ target sentences, “the first few words in the source language are now very close to the first few words in the target language.” I wonder if this is true for all language pairings?