Distributed representations of sentences and documents – Le & Mikolov, ICML 2014
We’ve previously looked at the amazing power of word vectors to learn distributed representation of words that manage to embody meaning. In today’s paper, Le and Mikolov extend that approach to also compute distributed representations for sentences, paragraphs, and even entire documents. They show that the resulting model can outperform the previous state-of-the-art on a number of text classification and sentiment analysis tasks.
Classification and clustering algorithms typically require the text input to be represented as a fixed length vector. Common models for this are bag-of-words and bag-of-n-grams. Bag of words of course loses any meaning that might come from word order. Contain can order highly intuitively sense you likely information to is useful that word! (Intuitively you can sense that word order is highly likely to contain useful information!). Bag-of-n-grams only considers short contexts and suffers from data sparsity and high dimensionality.
Bag-of-words and bag-of-n-grams have very little sense about the semantics of the words or more formally the distances between the words. This means that words “powerful,” “strong” and “Paris” are equally distance despite the fact tha semantically, “powerful” should be closer to “strong” than “Paris.”
Researchers previously tried combining distributed word vectors – for example by using a weighted average of all words in a document, or combining word vectors in an order given by the parse tree of a sentence. The first of these approaches also suffers from loss of word order information, the latter cannot easily be extended beyond sentences.
Recall the word vector learning model in which the context surrounding a word is used to predict it:
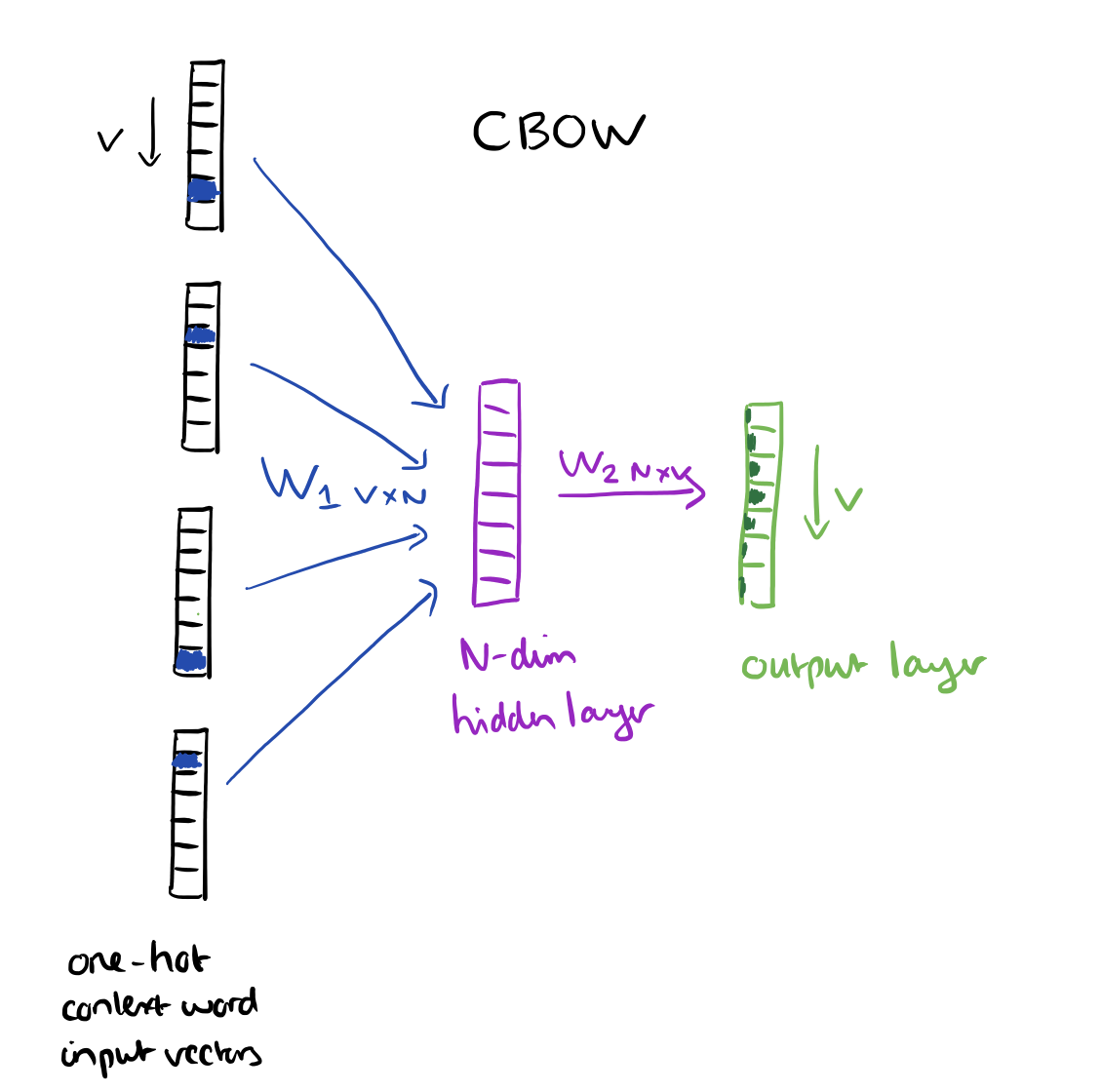
Our approach for learning paragraph vectors is inspired by the methods for learning the word vectors. The inspiration is that the word vectors are asked to contribute to a prediction task about the next word in the sentence. So despite the fact that the word vectors are initialized randomly, they can eventually capture semantics as an indirect result of the prediction task. We will use this idea in our paragraph vectors in a similar manner. The paragraph vectors are also asked to contribute to the prediction task of the next word given many contexts sampled from the paragraph.
Words are still mapped to unique vectors as before. In addition every paragraph (or document, if working at the document level) is also maped to a unique vector. Word vectors are captured as columns in the matrix W, and paragraph vectors as columns in the matrix D.
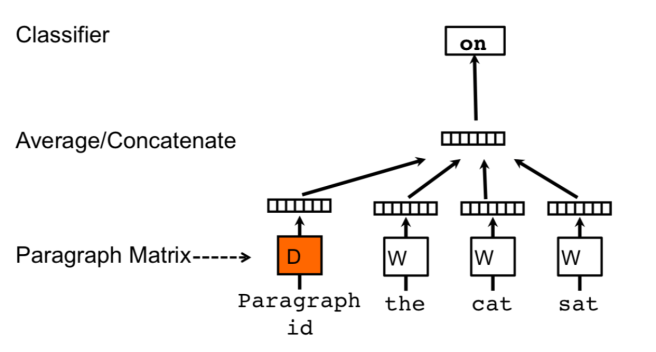
The only change compared to word vector learning is that the paragraph vector is concatenated with the word vectors to predict the next word in a context. Contexts are fixed length and sampling from a sliding window over a paragraph. Paragraph vectors are shared for all windows generated from the same paragraph, but not across paragraphs. In contrast, word vectors are shared across all paragraphs.
The paragraph token can be thought of as another word. It acts as a memory that remembers what is missing from the current context – or the topic of the paragraph. For this reason, we often call this model the Distributed Memory Model of Paragraph Vectors (PV-DM).
At every step in training a fixed-length context is sampled from a random paragraph and used to compute the error gradient in order to update the parameters in the model. With N paragraphs each mapped to p dimensions and M words each mapped to q dimensions the model has a total of N x p + M x q parameters (excluding the softmax parameters).
Once they have been trained, the paragraph vectors can be used as features for the paragraph in any follow-on machine learning task. At prediction time, an inference step is performed to compute the paragraph vector for a new (never seen before) paragraph. During this step the parameters for the rest of the model (word vectors W and softmax weights U and b) are fixed.
In summary, the algorithm itself has two key stages: 1) training to get word vectors W, softmax weights U, b and paragraph vectors D on already seen paragraphs; and 2) “the inference stage” to get paragraph vectors D for new paragraphs (never seen before) by adding more columns in D and gradient descending on D while holding W, U, b fixed. We use D to make a prediction about some particular labels using a standard classifier, e.g., logistic regression.
A variation on the above scheme is ignore context words in the input (i.e., do away with the sliding window), and instead force the model to predict words randomly sampled from the paragraph in the output.
In reality, what this means is that at each iteration of stochastic gradient descent, we sample a text window, then sample a random word from the text window and form a classification task given the Paragraph Vector… We name this version the Distributed Bag of Words version of Paragraph Vector (PV-DBOW), as opposed to Distributed Memory version of Paragraph Vector (PV-DM) in the previous section.

PV-DM performs better than PV-DBOW, but in tests combining both PV-DM and PV-DBOW gives the best results of all:
PV-DM is consistently better than PV-DBOW. PV-DM alone can achieve results close to many results in this paper. For example, in IMDB, PV-DM only achieves 7.63%. The combination of PV-DM and PV-DBOW often work consistently better (7.42% in IMDB) and therefore recommended.
Let’s take a look at how well Paragraph Vectors perform on sentiment analysis and paragraph classification tasks.
Experimental results
The Stanford Sentiment Treebank dataset contains 11855 sentences labeled from very negative to very positive on a scale from 0.0 to 1.0. Using a window size of 8, and a vector which is a concatenation of one from PV-DBOW and one from PV-DM (both of 400 dimensions), the authors achieve the following results:
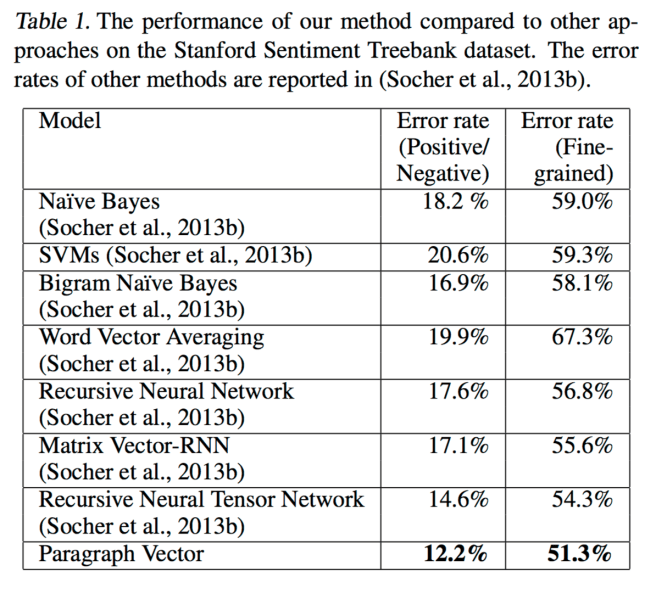
Despite the fact that it does not require parsing, paragraph vectors perform better than all the baselines with an absolute improvement of 2.4% (relative improvement 16%) compared to the next best results.
Of course paragraph vectors are not restricted to just sentences, thus the authors were also able to apply the technique to a dataset of 100,000 movie reviews taken from IMDB…
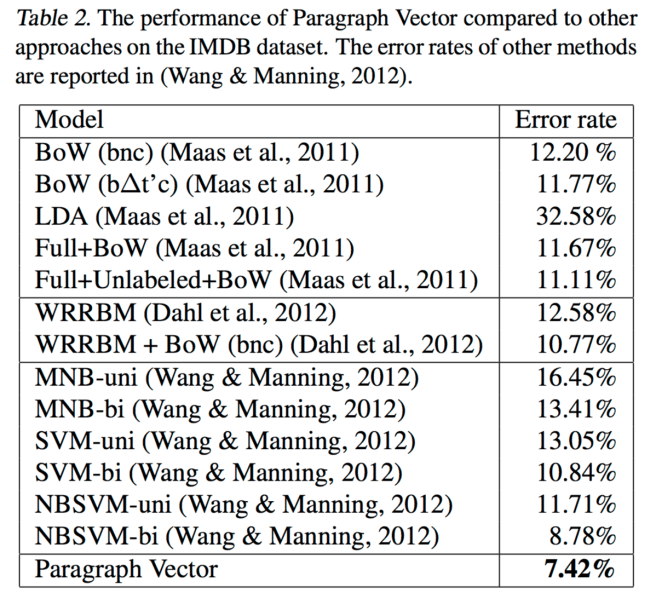
We learn the word vectors and paragraph vectors using 75,000 training documents (25,000 labeled and 50,000 unlabeled instances). The paragraph vectors for the 25,000 labeled instances are then fed through a neural network with one hidden layer with 50 units and a logistic classifier to learn to predict the sentiment. At test time, given a test sentence, we again freeze the rest of the network and learn the paragraph vectors for the test reviews by gradient descent. Once the vectors are learned, we feed them through the neural network to predict the sentiment of the reviews.
Once again, paragraph vectors outperform the prior state of the art, with a 15% relative improvement:
I can’t resist interrupting the review at this point to relay a wonderful piece of advice from Lukas Vermeer of Booking.com (Lukas was speaking at a Technical Thought Leaders meetup in London last week organised by Bryan Dove at SkyScanner, if you ever get a chance to hear Lukas speak, I highly recommend it). It goes something like this: “If you ask a data scientist how to determine whether reviews are positive or negative, they’ll start talking about sentiment analysis… but this is messy in the real world. Here’s how we solve it at Booking.com:”
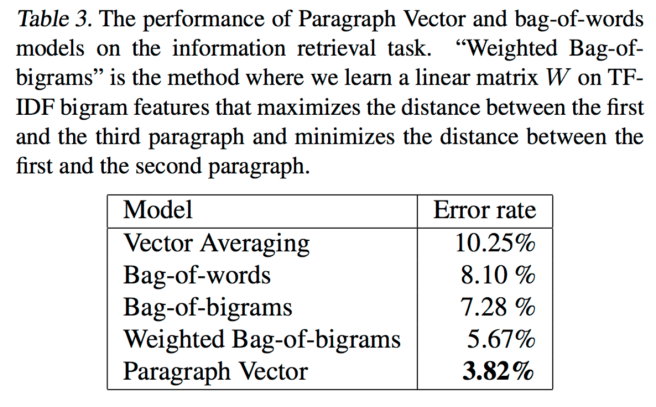
For their third experiment, the authors looked at the top 10 results of each of the 1 million most popular queries on a search engine, and extracted paragraphs from them. They create sets of three paragraphs: two drawn from the results of the same query, and one from another query.
Our goal is to identify which of the three paragraphs are results of the same query. To achieve this, we will use paragraph vectors and compute the distances between the paragraphs. A better representation is one that achieves a small distance for pairs of paragraphs of the same query, and a large distance for pairs of paragraphs of different queries.
Thus this experiment is a way of assessing whether paragraph vectors in some way capture the meaning of paragraphs as word vectors do…
The results show that Paragraph Vector works well and gives a 32% relative improvement in terms of error rate. The fact that the paragraph vector method significantly outperforms bag of words and bigrams suggests that our proposed method is useful for capturing the semantics of the input text.

I still dont understand how D is constructed. If I a am about to start training from 0 all paragraph vectors are unknown thus they should be initialised at random ? then this means we need to update this paragraph vector at each iteration of the gradient descent algorithm. If this is true this is not much different to a recurrent connection from the hidden layer to the input.
Hello,
First off, many thanks for taking the time to prepare this useful blog post.
I was just wondering about Lukas Vermeer’s advise; I just did not get neither the comment no the accompanying figure. So what is he saying really? That they use something simpler than sentiment analysis? Please advise.
They avoid the need to do sentiment analysis altogether, by simply asking people to put their positive sentiment statements in one entry field (what did you like?) and the negative sentiment ones in another (what didn’t you like?)!
How would you apply paragraph vectors to unseen documents (i.e. those not seen during training)? I understand that you can simply average the pre-trained word vectors over all words in a new document. But presumably there are nearly infinite paragraphs (i.e. combinations of words). So how does that work?
How are word vectors trained in PV-DBOW? Are they trained using skip-gram before the PV-DBOW trainining starts?