How to build static checking systems using orders of magnitude less code Brown et al., ASPLOS ’16
You start with something simple. Then over time things get more and more complex and before you know it, it’s hard to know what’s going on. Today’s paper is a delightful reminder of the power of stripping back to the essence, and just how powerful the simple approach can sometimes be. The context is the creation of static checkers for finding bugs in code.
Research on bug finding has exploded in the past couple of decades. While researchers have explored many approaches, the dominant, near-universal trend has been towards increasing complexity…. the more complex a tool is; the worse it scales; the harder it is to debug and understand; and the more assumptions it makes, limiting the programs it can check.
The authors even had trouble understanding their own tools…
This paper is our reaction to these (and other) bitter experiences, and to the metastazing complexity throughout the field. We have taken the simplest bug finding approach – static analysis – and further reduced its complexity by about two orders of magnitude.
The dramatically simpler result turns out to also be very effective:
Our empirical result that checkers can ignore the bulk of a programming language and yet be effective is viewed as “surprising” (to pick the most diplomatic word) by nearly everyone in the programming language community we have discussed it with.
How is this combination of simplicity and effectiveness achieved? By ignoring most of the accidental complexity in language grammars (from the perspective of a bug checking tool), and focusing only on the essential complexity that needs to be addressed for the problem at hand. Micro-parsers are created based on micro-grammars: partial grammars designed to extract checker-specific features only, and that don’t need to understand the full programming language grammar. The parsers are often less than 200 lines of code, and the checkers built on top of them often less than 40 lines of code. The authors are able to find over 700 bugs in widely-used systems written in different languages, including finding bugs not found by commercial tools. In the spirit of COST we’re going to have to learn how to COMPare code checkers: the Checker that Outperforms a Micro-Parser.
The micro-parsing idea is really easy to understand (which is kind of the point). It works as follows:
- Whereas a traditional parser returns an error when it fails to parse a program, a micro-grammar based parser simply slides forward by one token on non-matching input and tries again. Thus is matches all constructs described by the micro-grammar, and skips past anything that doesn’t match.
- Within a grammar rule, developers can use wildcard non-terminals that lazily match any input up to a suffix.
For example, we can write a micro-grammar that matches if statements but does not care about the details of expressions: “S → if ( wildcard ).” When applied to a file with five if statements, the parser returns five parse trees. While a traditional parser creates a tree with (roughly) one node for every token, our parser returns a tree where lists of tokens match to each wildcard node. For example, parsing “if (x == y)” with the if statement micro-grammar would result in a normal if node and a wildcard node containing “[“x”, “==”, “y”]”.
The parsers and checkers are so simple that they can often be created in less than a day, or even a couple of hours. And often parts of languages overlap enough that they can share almost the same micro-grammar.
Developers then build parsers recursively by defining a parser for each non-terminal and composing these parsers together to accept a micro-grammar. Adding a new non-terminal to a grammar equates to combining its parser with an existing one. For example, to create a parser for C’s control flow, we first write parsers for if statements, while loops, for loops, etc. Each of these small parsers is around six lines of code, and we glue them together into a 156 line C control flow parser.
The overall framework is called μchex, and provides a set of built-in functions for common checking operations. It is tuned for ‘belief-style’ checkers, where beliefs are facts implied by code. For example, x/y implies a belief that y is non-zero. The micro-grammar approach is not limited to this style of checking though.
Comparison to traditional checkers
Despite ignoring most of the language, our checkers are not limited to checking simple syntactic properties. We reimplement two flow-sensitive checkers (§ 4) originally built using a traditional checking system, and show that despite being orders of magnitude simpler, they find a similar number of true bugs.
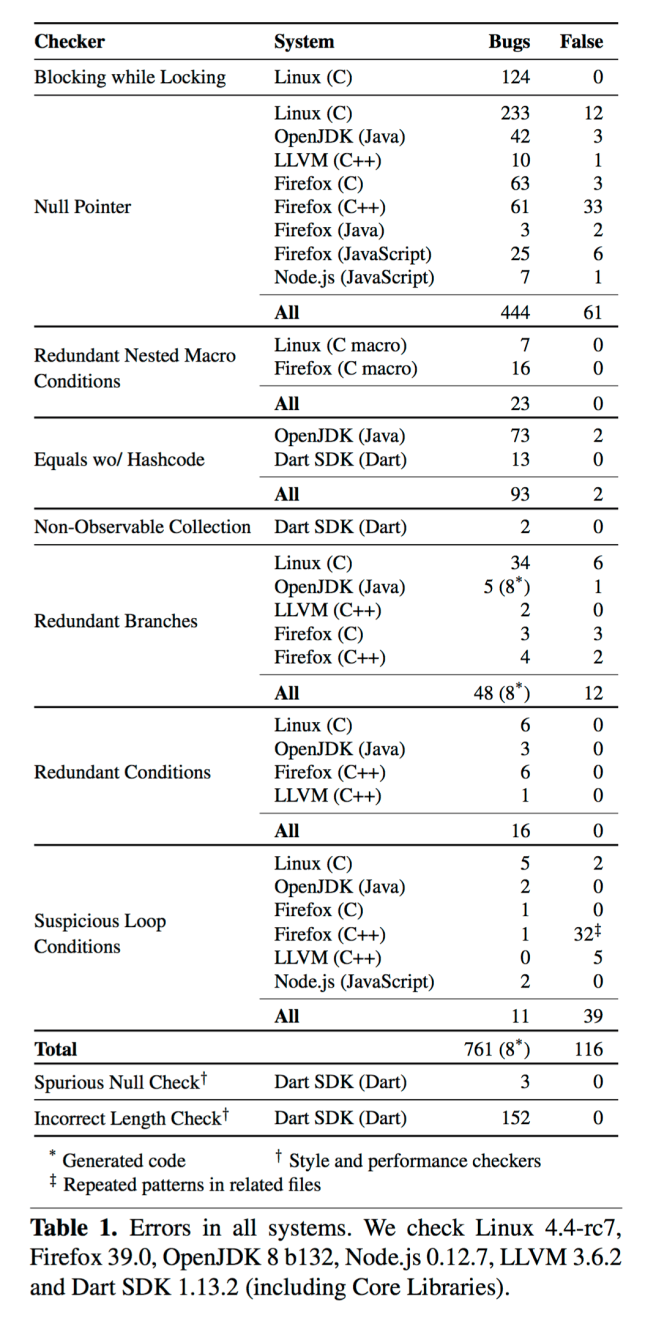
The authors recreate two flow-sensitive checkers from their previous work: a null pointer checker and a deadlock checker. The null pointer checker uses two parsers, one for control flow and one for expressions. The (reusable) control flow parser is 156 lines of code. The expression parser is 29 lines of code. The null pointer checker operates on the resulting tree. It finds 233 true bugs and 12 false positives in Linux (5% false positive). The original checker found 102 bugs and 4 false positives. The checker also finds 63 bugs and 3 false positives in Firefox.
The deadlock checker computes a set of beliefs about whether a program can block. It finds 124 bugs in the Linux and no false positives. The original version found 123 bugs.
Comparison to state of the art commercial tools
Micro-grammar checkers are not weak, and can help debug more sophisticated tools. When we check the same property as a state-of-the-art commercial tool and compare our results on the same code base, we find a roughly comparable number of bugs; we also find 190 bugs that the commercial tool misses. As a result, we think that our approach may be used as a safety net for more complex tools.
The commercial tool is simply identified as ‘SystemX’. “The company behind the tool has been developing static checkers for more than a decade, with a team that currently numbers in the low hundreds.” Testing against Linux 4.4-rc7 the micro-grammar based checker finds 44 out of 122 of SystemX’s reports. But it also finds those 190 bugs that SystemX does not. Of the bugs that SystemX finds but the micro-checker does not (72 in total), 66 are because SystemX uses inter-procedural analysis and alias tracking which the micro-checker does not….
Based on our past experiences, we believe simple inter-procedural analysis can be readily added to μchex. μchex could also implement trival alias tracking, but non-trivial alias tracking is challenging without a full understanding of the checked language.
Adaptability
We repeatedly show (§ 5.1) that adopting an existing checker in our system to a new, previously unchecked language is a matter of writing a few lines of code (even when going from C++ to JavaScript!). Furthermore, writing a new checker from scratch is often in the tens of lines (§ 5.2). This ease is in contrast to traditional static checking systems, which, because of their detailed dependency on exact language semantics, might take months or years to retarget to a new language.
The authors took the null pointer checker originally implemented in C, and adapted it to also look for null pointer errors in C++, Java, and JavaScript. In a traditional checker, creating or adapting a front-end for a new language can take months or years… “as one data point, it took us years to add Java checking to our C static tool, both in an academic and later in an industry setting.”
Adapting the null pointer checker to C++ requires 27 lines of code, and finds 71 bugs. Even without any adaptation, the original tool finds 50 of the same bugs – a great demonstration of the power of being liberal in what you accept when the details don’t matter. Adapting the checker to Java is a mere two lines fo code, “the only real change is representing the dereference operator as ‘.’ instead of ‘->’. Here’s an example of an issue found by the checker in OpenJDK :
// implies output != null
int outputCapacity =
output.length - outputOffset;
int minOutSize = (decrypting?
(estOutSize - blockSize):estOutSize);
// implies output can be null...
if ((output == null) ... ) ...
Adapting the checker to JavaScript required 17 lines of code. It finds 25 bugs in Firefox and 7 in Node.js.
The authors then create new checkers from scratch for Dart and CPP (the C preprocessor). For CPP, a 40-line checker and parser finds 16 bugs in Firefox and 7 bugs in Linux. For Dart the authors implement four checkers based on common errors identified by active Dart developers: equals without hashcode; non-observable @Observable collections; spurious null checks; and incorrect length checks. Three of these checkers share the same 207 line Dart control flow parser, the other one uses an independent 7-line parser.
The equals-without-hashcode checker is 28 lines and finds 13 bugs. The non-observable checker is 26 lines and finds 2 bugs. The null checker is 9 lines, and the incorrect length checker is 7 lines and finds 152 bugs.
Clearly, even though these checkers are small and easy to build, they still find real-world errors that matter to developers.
Portability
One of our most unexpected results is that the same checker and parser combination can find bugs in many different languages. The intuition behind this fact is that if languages share a common heritage, some portion of their grammars may be similar, even though they may otherwise differ significantly. Micro-grammars can capture the overlapping portion while ignoring the rest of the grammar.
The same checker, unaltered, is run on C, C++, Java, and JavaScript code, looking for programming logic errors in the form of tautological branching decisions (if statements with redundant branches, or repeated conditions, and loop headers where the condition contradicts the increment: for (i=0; i < len; i--).
The redundant branches checker finds 48 true bugs and 12 false positives, plus 8 additional instances in generated code in OpenJDK. The other checkers are also able to detect genuine bugs across all languages.
Summary of errors found using micro-grammars

typo at “Thus is matches all constructs”
typo “mere two lines fo code,”
Thank you for catching these typos, I will fix them when I get back to my desktop….
I am a bit surprised this paper got accepted at ASPLOS. Writing simple static checkers using Island grammars is not hard (well at least if you know what you are doing and have had lots of practice; I see plenty of raised eyebrows when I throw a lexer/parser together in an afternoon).
Engler’s group is where Coverity started life, so I suspect this is System X.
They have chosen their checks to be ones known to frequently fail and for which they have existing code/techniques to detect. A good way to impress people once, but what about everything else?
Checkers were implemented for lots of different languages. Is this because it was easier to support a new language than implements new checks that found real problems?
I am a bit surprised at the number of claimed faults; 124 non-false positive bugs in Linux. Is this because they are using the latest release of the kernel and it has not yet been run through its own checker? I would expect a much higher false positive rate for such a simple checker.