Scalability! But at what COST? – McSherry et al. 2015
With thanks to Felix Cuadrado, @felixcuadrado, for pointing this paper out to me via twitter.
Scalability is highly prized, yet it can be a misleading metric when studied in isolation. McSherry et al. study the COST of distributed systems: the Configuration that Outperforms a Single Thread. The COST of a system is the hardware platform (number of cores) required before the platform outperforms a competent single threaded implementation.
COST weighs a system’s scalability against the over- heads introduced by the system, and indicates the actual performance gains of the system, without rewarding systems that bring substantial but parallelizable overheads.
It’s a relatively short paper, and it has many highly quotable and thought-provoking passages. I strongly encourage you to click the link at the top and read the full thing. Frank McSherry’s blog post on the paper is also great.
COST turns out to be a damning metric. Many published systems have unbounded COST (that is, they never outperform the best single threaded application), and others are orders of magnitude slower even when using hundreds of cores.
“You can have a second computer once you’ve shown you know how to use the first one.” – Paul Barham
Take a look at the graph comparing systems A and B below showing how they scale as we add cores. Which is the better system?
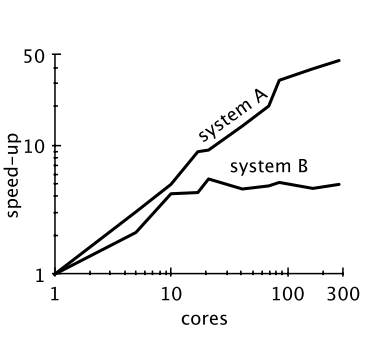
If you answered based purely on scalability, you probably said system A. A better answer, when presented with just that one graph is “I don’t know yet.” Consider this second graph of the same two systems:

System B outperforms A at every scale – I know which one I’d rather be deploying, the one that scales the worst!
In fact in these graphs, A and B are the same base system but B has a performance optimization applied which removes parallelizable overheads.
Contrary to the common wisdom that effective scaling is evidence of solid systems building, any system can scale arbitrarily well with a sufficient lack of care in its implementation… Our hope is to shed light on this issue so that future research is directed toward distributed systems whose scalability comes from advances in system design rather than poor baselines and low expectations.
Taking the exact same datasets and the same tasks as those used in the GraphX paper, McSherry et al. implement and evaluate single threaded versions and compare the results against those in the GraphX paper. “Conveniently, Gonzalez et al. evaluated the latest versions of several graph-processing systems in 2014.”
I’ve plotted the results from Table 1 in the paper for running 20 iterations of PageRank on the Twitter dataset – the number of cores used by each system is shown in parentheses after the name.
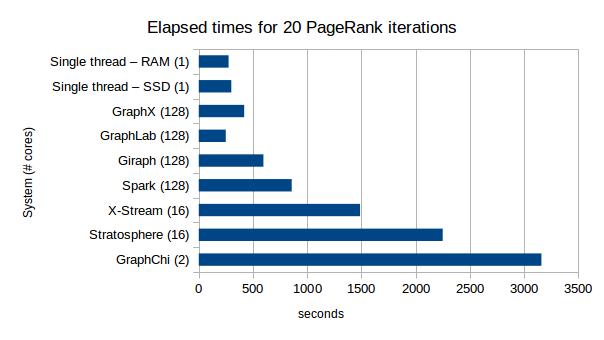
Only GraphLab manages to get close to the single-threaded system at all, and it is using 128 cores vs the one core used by the single-threaded system! Later in the paper McSherry et al. show that by using a Hilbert curve to order edges they can get their single-threaded implementation to perform even better, with the RAM-based PageRank completing in 110s, significantly better even that GraphLab’s 128 core 249s time.
Comparing published scaling information from PowerGraph (GraphLab), GraphX, and Naiad, against the single threaded systems yields the following COST conclusions:
From these curves we would say that Naiad has a COST of 16 cores for PageRanking the twitter rv graph. Although not presented as part of their scaling data, GraphLab reports a 3.6s measurement on 512 cores, and achieves a COST of 512 cores. GraphX does not intersect the corresponding single-threaded measurement, and we would say it has unbounded COST.
This is what happens when the same comparison is done for the connected components task on the twitter graph (based on table 3 in the paper).
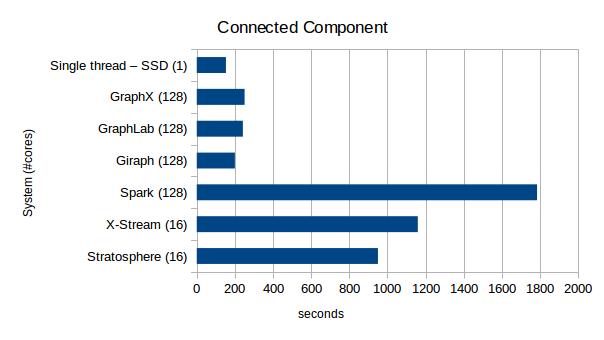
The published works do not have scaling information for graph connectivity, but given the absolute performance of label propagation on the scalable systems relative to single-threaded union-find we are not optimistic that such scaling data would have lead to a bounded COST.
The ‘scalable’ connected component implementations are based on label propagation. Why? Because it fits well within the programming model presented:
The problem of properly choosing a good algorithm lies at the heart of computer science. The label propagation algorithm is used for graph connectivity not because it is a good algorithm, but because it fits within the “think like a vertex” computational model, whose implementations scale well. Unfortunately, in this case (and many others) the appealing scaling properties are largely due to the algorithm’s sub-optimality; label propagation simply does more work than better algorithms.
Are scalable programming models leading us down a sub-optimal path?
To achieve scalable parallelism, big data systems restrict programs to models in which the parallelism is evident. These models may not align with the intent of the programmer, or the most efficient parallel implementations for the problem at hand. Map-Reduce intention- ally precludes memory-resident state in the interest of scalability, leading to substantial overhead for algorithms that would benefit from it. Pregel’s “think like a vertex” model requires a graph computation to be cast as an iterated local computation at each graph vertex as a function of the state of its neighbors, which captures only a limited subset of efficient graph algorithms. Neither of these designs are the “wrong choice”, but it is important to distinguish “scalability” from “efficient use of resources”.
McSherry et al. leave us with three recommendations relating to evaluation, system design, and algorithm choice:
- When evaluating a system, it is important to consider the COST “both to explain whether a high COST is intrinsic to the proposed system, and because it can highlight avoidable inefficiencies and thereby lead to performance improvements for the system.”
-
Learn from the systems that have achieved both performance and scale:
There are several examples of performant scalable systems. Both Galois and Ligra are shared-memory systems that significantly out-perform their distributed peers when run on single machines. Naiad introduces a new general purpose dataflow model, and outperforms even specialized systems. Understanding what these systems did right and how to improve on them is more important than re-hashing existing ideas in new domains compared against only the poorest of prior work.
- Make sure we are using appropriate algorithms:
… there are numerous examples of scalable algorithms and computational models; one only needs to look back to the parallel computing research of decades past. Boruvka’s algorithm is nearly ninety years old, parallelizes cleanly, and solves a more general problem than label propagation. The Bulk Synchronous Parallel model is surprisingly more general than related work sections would have you believe. These algorithms and models are richly detailed, analyzed, and in many cases already implemented.
In his blog post Frank McSherry offers some additional takeaways including:
- If you are going to use a big data system for yourself, see if it is faster than your laptop, and
- If you are going to build a big data system for others, see that it is faster than my laptop.

I’d love to see an analysis the included development and setup time in the time taken to get to the first result. It’d also be interesting to see the effect of data gravity: how long does it take to provision the system in an arbitrary location, including the time taken to move the data into the correct place and format. I guess those aspects are much more on the softer side of software engineering rather than computer science tho’.
There’s some detail relating to the setup time etc. in Frank McSherry’s blog posts on the subject (single thread still wins ;) ).
I was assuming that you’d have to do your own “competently implemented single threaded version”, otherwise there would be a product on the market that you could download and use and it would already be the default option by virtue of it being so much faster than the competition.
Given that you have to write your own or at least find and integrate a library, that would put the technology out of reach of the vast majority of businesses.