Mosaic: Processing a trillion-edge graph on a single machine Maass et al., EuroSys’17
Unless your graph is bigger than Facebook’s, you can process it on a single machine.
With the inception of the internet, large-scale graphs comprising web graphs or social networks have become common. For example, Facebook recently reported their largest social graph comprises 1.4 billion vertices and 1 trillion edges. To process such graphs, they ran a distributed graph processing engine, Giraph, on 200 machines. But, with Mosaic, we are able to process large graphs, even proportional to Facebook’s graph, on a single machine.
In this case it’s quite a special machine – with Intel Xeon Phi coprocessors and NVMe storage. But it’s really not that expensive – the Xeon Phi used in the paper costs around $549, and a 1.2TB Intel SSD 750 costs around $750. How much do large distributed clusters cost in comparison? Especially when using expensive interconnects and large amounts of RAM.
So Mosaic costs less, but it also consistently outperforms other state-of-the-art out of core (secondary storage) engines by 3.2x-58.6x, and shows comparable performance to distributed graph engines. At one trillion edge scale, Mosaic can run an iteration of PageRank in 21 minutes (after paying a fairly hefty one-off set-up cost).
(And remember, if you have a less-than-a-trillion edges scale problem, say just a few billion edges, you can do an awful lot with just a single thread too!).
Another advantage of the single machine design, is a much simpler approach to fault tolerance:
… handling fault tolerance is as simple as checkpointing the intermediate stale data (i.e., vertex array). Further, the read-only vertex array for the current iteration can be written to disk parallel to the graph processing; it only requires a barrier on each superstep. Recovery is also trivial; processing can resume with the last checkpoint of the vertex array.
There’s a lot to this paper. Perhaps the two most central aspects are design sympathy for modern hardware, and the Hilbert-ordered tiling scheme used to divide up the work. So I’m going to concentrate mostly on those in the space available.
Exploiting modern hardware
Mosaic combines fast host processors for concentrated memory-intensive operations, with coprocessors for compute and I/O intensive components. The chosen coprocessors for edge processing are Intel Xeon Phis. In the first generation (Knights Corner), a Xeon Phi has up to 61 cores with 4 hardware threads each and a 512-bit single instruction, multiple data (SIMD) unit per core. To handle the amount of data needed, Mosaic exploits NVMe devices that allow terabytes of storage with up to 10x the throughput of SSDs. PCIe-attached NVMe devices can deliver nearly a million IOPS per device with high bandwidth (e.g. Intel SSD 750) – the challenge is to exhaust this available bandwidth.
As we’ve looked at before in the context of datastores, taking advantage of this kind of hardware requires different design trade-offs:
We would like to emphasize that existing out-of-core engines cannot directly improve their performance without a serious redesign. For example, GraphChi improves the performance only by 2-3% when switched from SSDs to NVMe devices or even RAM disks.
Scaling to 1 trillion edges
That’s a lot of edges. And we also know that real-world graphs can be highly skewed, following a power-law distribution. A vertex-centric approach makes for a nice programming model (“think like a vertex”), but locality becomes an issue when locating outgoing edges. Mosaic takes some inspiration from COST here:
To overcome the issue of non-local vertex accesses, the edges can be traversed in an order than preserves vertex locality using, for example, the Hilbert order in COST using delta encoding.
Instead of a global Hilbert ordering of edges (one trillion edges remember), Mosaic divides the graph into tiles (batches of local graphs) and uses Hilbert ordering for tiles.
A Hilbert curve is a continuous fractal space-filling curve. Imagine a big square table (adjacency matrix) where the rows and columns represent source vertices and target vertices respectively. An edge from vertex 2 to vertex 4 will therefore appear in row 2, column 4. If we traverse this table in Hilbert-order (following the path of the curve), we get a nice property that points close to each other along the curve also have nearby (x,y) values – i.e., include similar vertices.
The following illustration shows a sample adjacency matrix, the Hilbert curve path through the table, and the first two tiles that have been extracted.
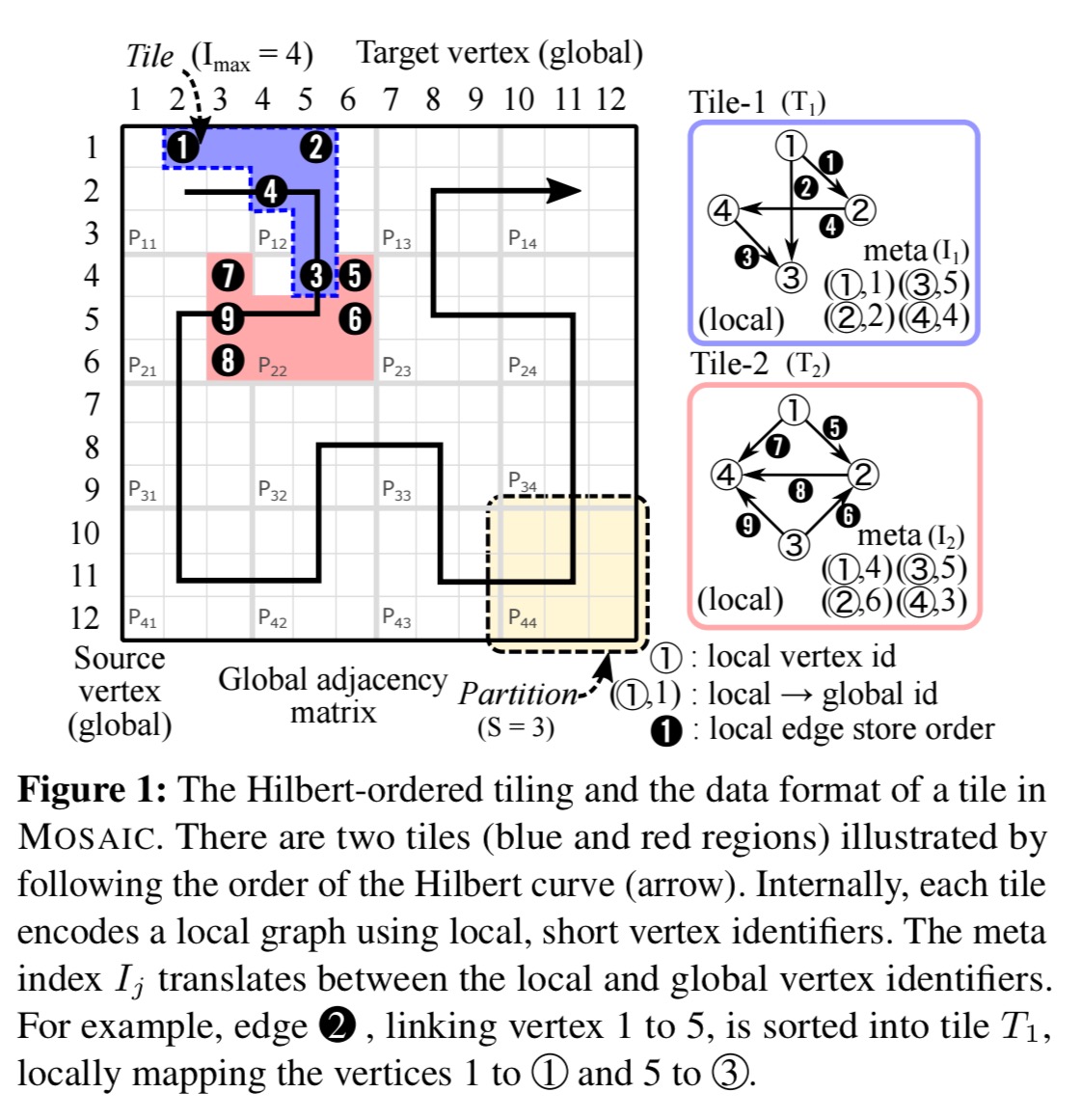
Also note that the edge-space is divided into partitions (labelled 


We consume partitions following the Hilbert order, and add as many edges as possible into a tile until its index structure reaches the maximum capacity to fully utilize the vertex identifier in a local graph… This conversion scheme is an embarrassingly parallel task.
At runtime, Mosaic processes multiple tiles in parallel on four Xeon Phis. Each has 61 cores, giving 244 processing instances running in parallel.
Due to this scale of concurrent access to tiles, the host processors are able to exploit the locality of the shared vertex states associated with the tiles currently being processed, keeping large parts of these states in the cache.
When processing a tile, neighbouring tiles are prefetched from NVMe devices to memory in the background, following the Hilbert-order.
System components
The full Mosaic system looks like this:
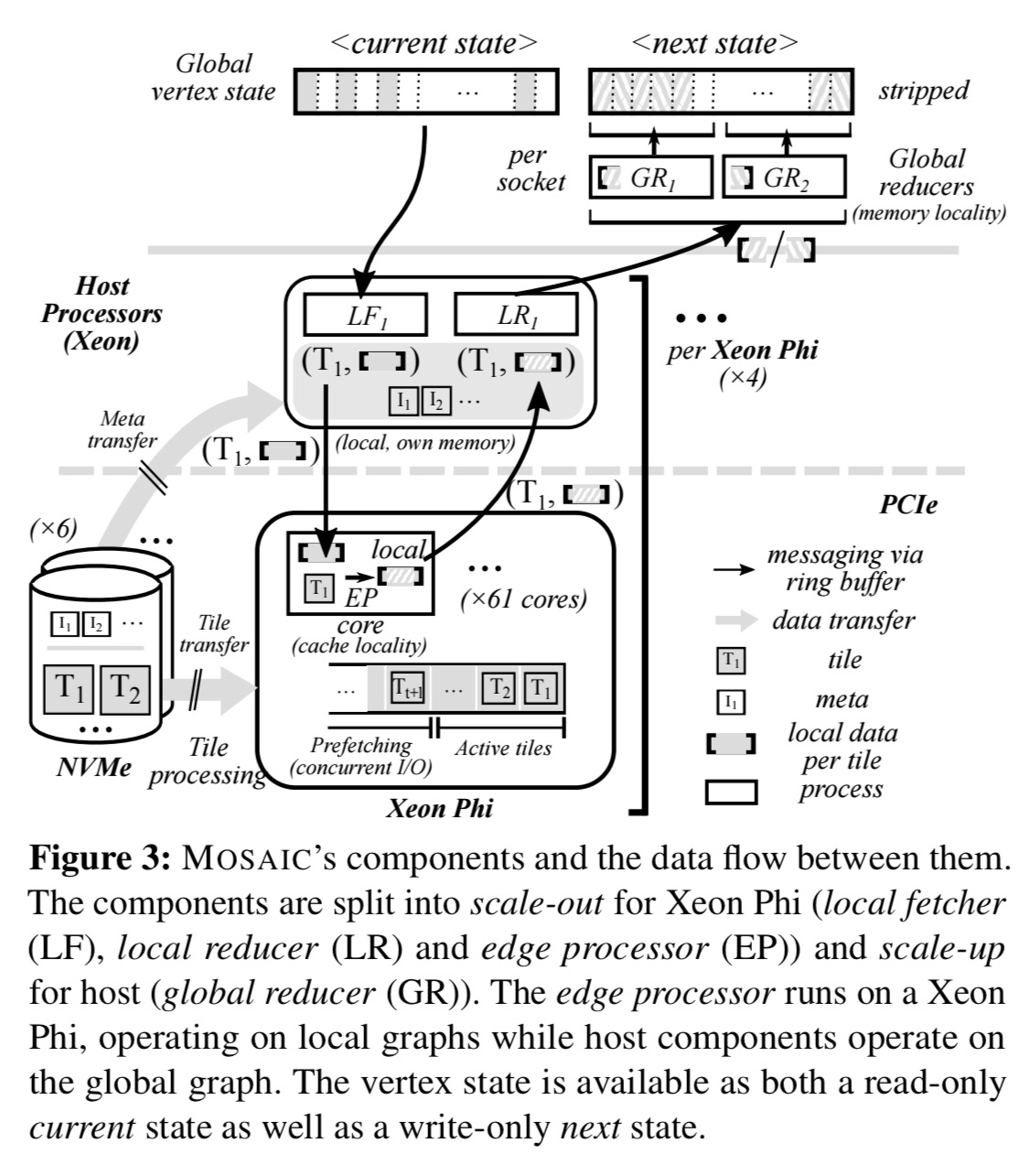
The Xeon Phi coprocessors run local fetchers, edge processors, and reducers. Each Phi has one fetcher and one reducer, and an edge processor per core. The local reducer retrieves the computed responses from the coprocessors and aggregates them before sending them back for global processing.
The host processor runs global reducers that are assigned partitions of the global vertex state and received and process input from local reducers.
As modern systems have multiple NUMA domains, Mosaic assigns disjoint regions of the global vertex state array to dedicated cores running on each NUMA socket, allowing for large, concurrent NUMA transfers in accessing the global memory.
Programming model
Mosaic uses the numerous yet slower co-processors cores to perform edge processing on local graphs, and the faster host processors to reduce the computation results to global vertex states.
To exploit such parallelism, two key properties are required in Mosaic’s programming abstraction, namely commutativity and associativity. This allows Mosaic to schedule computation and reduce operations in any order.
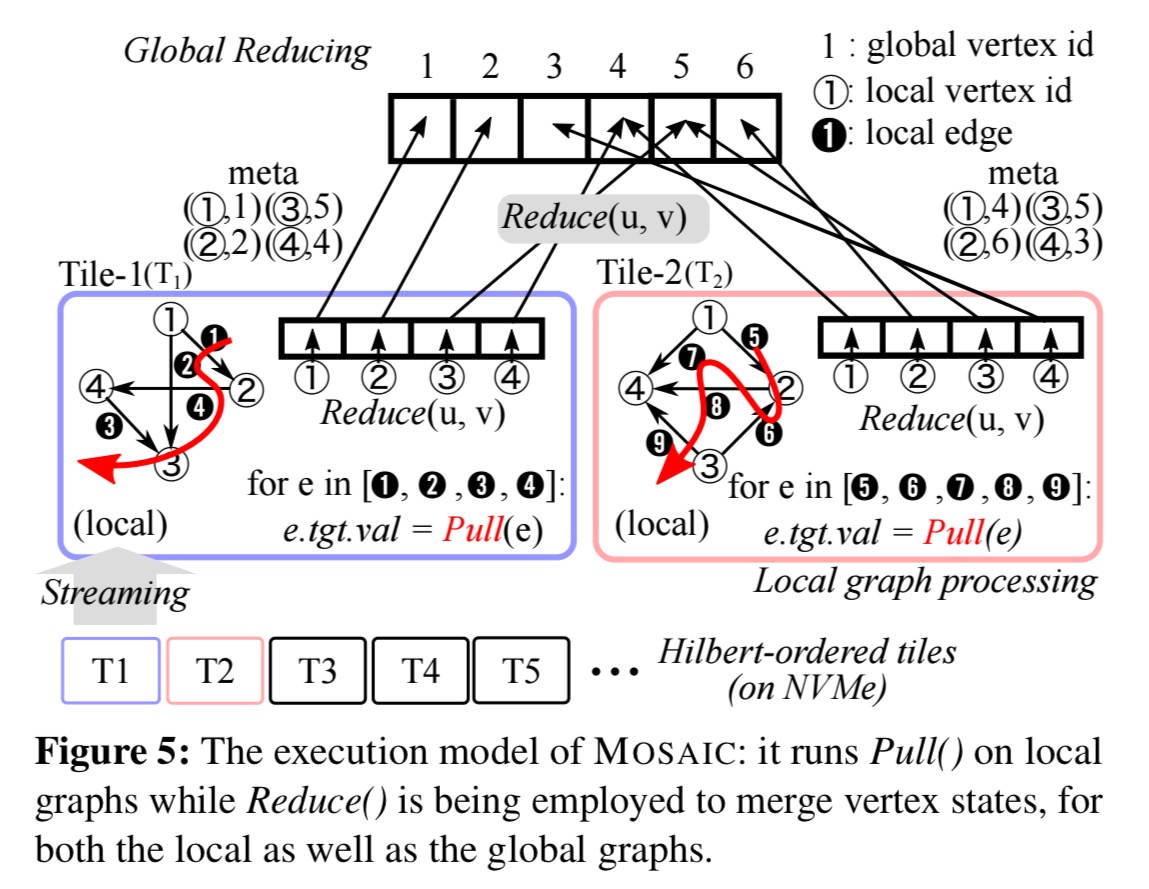
The API is similar to the Gather-Apply-Scatter model, but extended to a Pull-Reduce-Apply (PRA) model.
- Pull(e) : For every edge (u,v), Pull(e) computes the result of the edge e by applying an algorithm specific function on the value of the source vertex u, and the related data such an in- or out-degrees.
- Reduce(v1,v2): Takes two values for the same vertex and combines them into a single output. Invoke by edge processors on coprocessors, and global reducers on the host.
- Apply(v): After reducing all local updates to the global array, apply runs on each vertex state in the array, allowing the graph algorithm to perform non-associative operations. Global reducers run this at the end of each iteration.
It all fits together something like this:
And here’s what PageRank looks like using the Mosaic programming model:

Experiments
The team implemented seven popular graph algorithms and tested them on two different classes of machines – a gaming PC (vortex) and a workstation (ramjet), using six different real-world and synthetic datasets, including a synthetic trillion-edge graph following the distribution of Facebook’s social graph. The vortex machine has one Xeon Phi, whereas Ramjet has four.
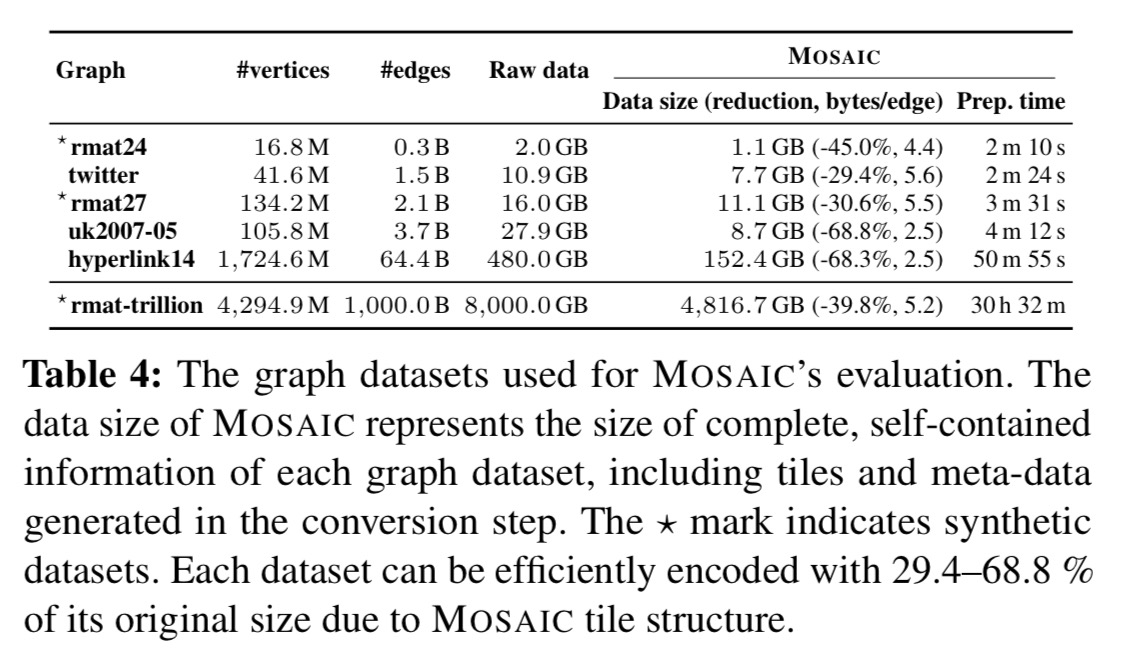
The execution times are shown in the following table:
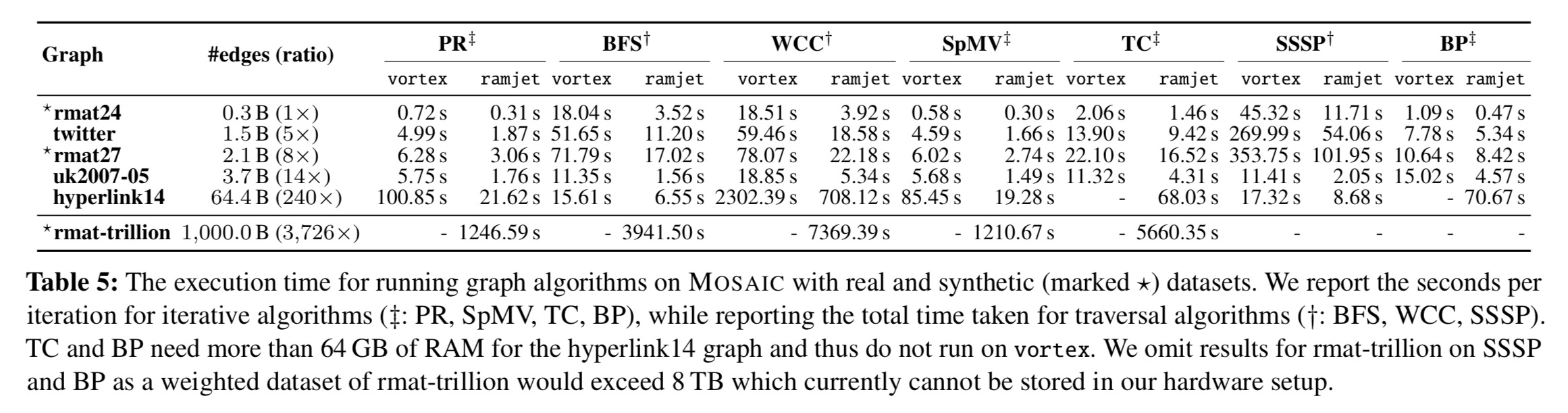
Mosaic shows 686-2,978 M edges/sec processing capability depending on datasets, which is even comparable to other in-memory engines (e.g. 695-1,390M edges/sec in Polymer) and distributed engines (e.g. 2,770-6,335 M edges/sec for McSherry et al.’s Pagerank-only in-memory cluster system.
On ramjet, Mosaic performs one iteration of Pagerank in 21 minutes.
Overall, here’s how Mosaic stacks up against some of the other options out there:
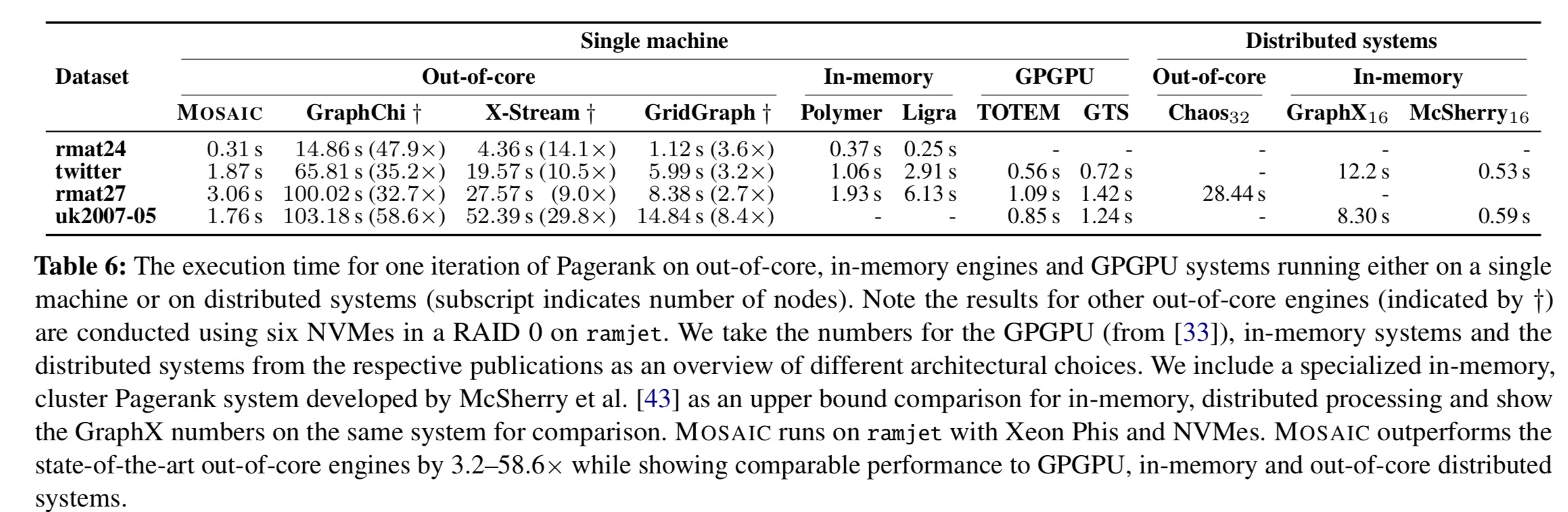
- Compared to GPGPU systems, Mosaic is slower by a factor of up to 3.3x, but can scale to much larger graphs.
- Compared to distributed out-of-core systems Mosaic is approximately one order of magnitude faster.
- Mosaic is performance competitive with distributed in-memory systems (beats GraphX by 4.7x-6.5x). These systems pay heavily for distribution.
Converting datasets to the tile structure takes 2-4 minutes for datasets up to about 30 GB. For hyperlink14, with 21 M edges and 480 GB of data it takes 51 minutes. For the trillion edge graph (8,000 GB) it takes about 30 hours. However, after only a small number of iterations of Pagerank, Mosaic is beating systems that don’t have a preprocessing step, showing a quick return on investment.
Finally, let’s talk about the COST. It’s very nice to see the authors addressing this explicitly. On uk2007-05, ramjet matches a single-threaded host-only in-memory implementation with 31 Xeon Phi cores (and ultimately can go up to 4.6x faster than the single-threaded solution). For the twitter graph, Mosaic needs 18 Xeon Phi cores to match single-thread performance, and ultimately can go up to 3.86x faster.

Does the Graph500 benchmark have any relevance here?
I saw a mention of it in the ARM SVE paper, as something that SIMD wouldn’t accelerate. That’s another question I’m curious about.
I’ve not come across that benchmark before (despite it existing since 2010 it seems!). I don’t know the answer to your question, but hopefully one of the readers might! Regards, Adrian.
I’m Steffen, the lead author of this paper.
Thanks for the interest in Mosaic, we’re very happy to see such a good summary of our system in this blog!
The Graph500 benchmark focuses on the performance of a system for a breadth first search (BFS), and while we have not entered Mosaic into the Graph500 list, we achieve about 1 giga traversed edges per second (GTEPS), the main metric for performance in Graph500, in a scale 27 instance, which is roughly spot 180 in the Graph500 list.
However, one thing to note is that we achieve this performance while reading from a set of NVMe devices rather than processing the data in-memory, which is what most other systems in that list seem to focus on..
I hope this answers the question, let me know if you have any more questions I can help with!
Steffen
MOSAIC open source code available on github, ostensibly in CPU only mode due to hardware quirks.
https://github.com/sslab-gatech/mosaic