Online reconstruction of structural information from datacenter logs Chothia et al., EuroSys’17
Today’s choice brings together a couple of themes that we’ve previously looked at on The Morning Paper: recovering system information from log files, and dataflows for stream processing.
On log files (and tracing), see for example Dapper, the MysteryMachine, lprof, and Pivot tracing. For the even shorter summary, see the “figuring out what’s going on” section of ‘The Morning Paper on Operability.’
I’ve covered too many papers relating to stream processing to list them all. Try seaching on stream processing or on dataflow – and don’t forget to keep clicking through the ‘older entries’ at the bottom if this topic interests you.
Reconstructing sessions from log files using batch processing is one thing, but the TS system in this paper does it in real time, while ingesting an entire datacenter’s worth of log output!
… online operation is a fundamental requirement for continuous monitoring of a datacenter and rapid, interactive diagnosis of problems as they happen.
The key to TS’s performance is building on top of Timely Dataflow, first described in the 2013 paper “Naiad: A Timely Dataflow System,” and more recently implemented in Rust by Frank McSherry.
… the problem TS solves is sufficiently complex that engineering a solution from scratch would be a prohibitive engineering task. Instead, TS is built on Timely Dataflow. A further contribution of this paper is to show how, by exploiting this general framework, TS admits a simple, concise implementation in 1770 lines of code, while at the same time seamlessly integrating with management applications that exploit the session and transaction information generated by TS online
Before we go deeper into how TS works, let’s take a step back and look at the (streaming) reconstruction problem.
Reconstruction and ‘sessionization’
You have lots of components in your datacenter producing logs (about 13,000 service instances in the datacenter logs studied for this paper). The authors assume a unique Id is assigned to every request entering the system, and that this is propagated on service requests, leading to log records with metadata such as:
Time: 2015/09/01 10:03:38.599859 Session ID: XKSHSKCBA53U088FXGE7LD8 Transaction ID: 26-3-11-5-1
A common task is then to relate all pieces of work done in individual components back to their originating request or tenant (resource attribution). By combining the correlators with other fields present in the logs, a detailed representation can be re-built which contains all activities in the workflow along with structure relating the individual facts.
The datacenter in question generates about 5Gb/s of log data, or about 50TB a day, spread across over 1300 distinct log servers.
Sessionization is the name given to the process of transforming a distributed set of these log records into a sequence of trees reflection the workflow of each request and session.
…broadly there are two key steps. First, log records are grouped into sessions using unique IDs, and session are marked as “closed” based, if necessary, on time-based windows of inactivity; and second, each closed session is converted to a trace tree which aggregates individual inter-application transactions or spans into a complete operation.
If you do this offline, it looks like a classic map-reduce. In the online setting though data arrives continuously, and the streaming computation must buffer log records, track inactivity windows for each session, and emit the reconstructed trace once the session is closed. To make things harder, the use of many distributed log servers coupled with local buffering and batch flushing at each often leads to log records being reordered in the stream. Log records can also go missing for a variety of reasons – including errors and omissions in the logging statements themselves! Clock skew across machines can also be an issue (causing e.g., parent transactions to appear to start after their children). “In our particular use case, such case seem to be rare, but nevertheless do occur and causes anomalies in the output.” For this study, the authors assume clocks are synchronized.
TS
TS ingests logs in real-time from a collection of servers emitting hierarchically labelled log records such as those produced by Google’s Dapper. All log records relevant to a given session are assumed to arrive with bounded delay, but can arrive reordered and from different logging servers. The big picture looks like this:
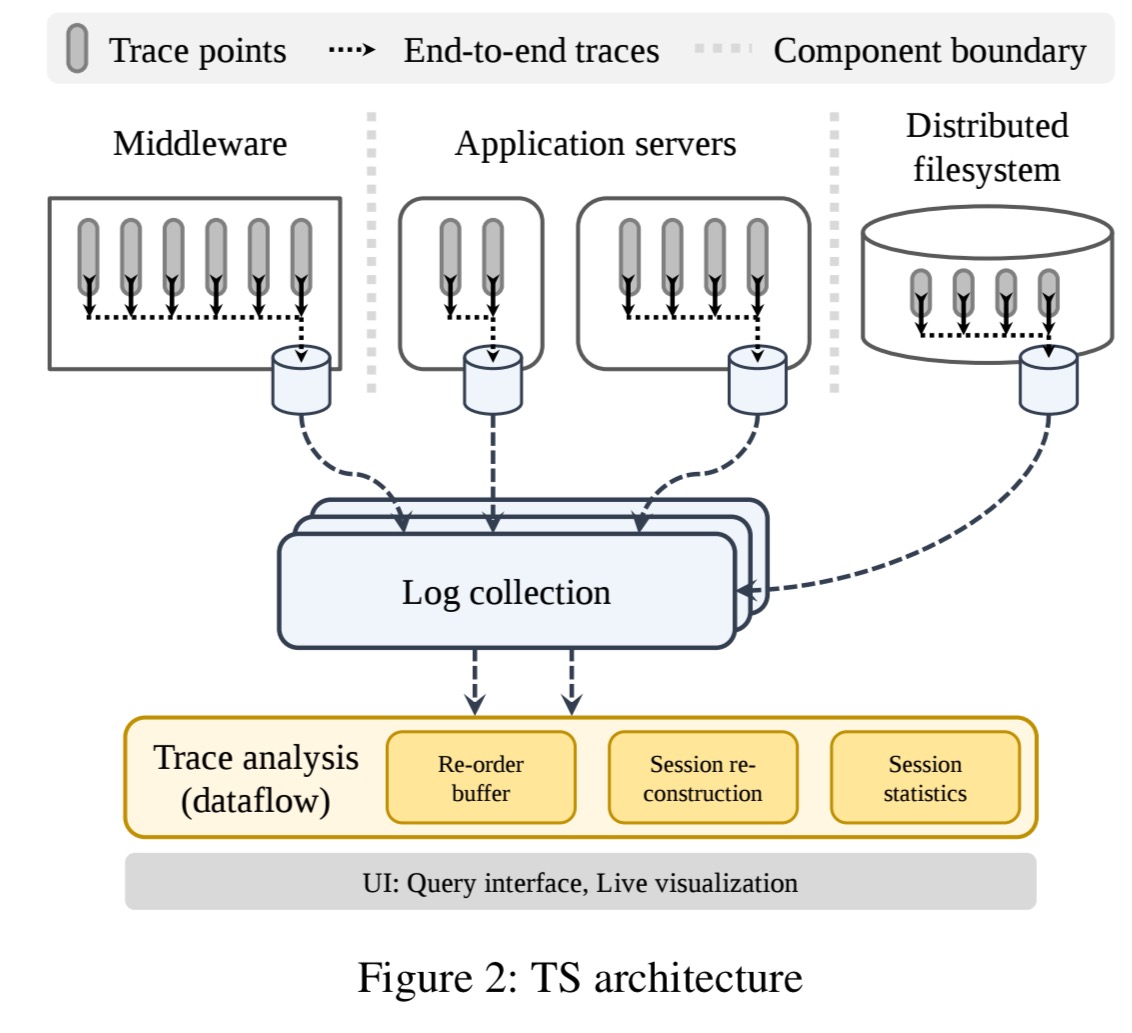
The trace analysis system has three main components built on top of a Timely Dataflow substrate:
- Re-order buffers are used to buffer and sort input logs based on the indicated event time. The size of the buffer determines the system tolerance to late arrivals. “Anecdotally, our experience so far has been that when related events in real logging infrastructure arrive out of order, their arrival times at TS are actually quite tightly bounded, and so sessions can be reconstructed accurately using relatively small re-order buffers.“
- The session reconstruction component performs sessionization. TS uses a ‘flush on inactivity’ approach to close sessions after a chosen interval has elapsed in which no messages have been received.
- The session statistics component builds higher level statistical summaries on top of the reconstructed sessions. Everything is built from a library of operators that can be used to reconstruct transaction trees, gather histograms and percentiles etc..
TS derives much of its flexibility, and performance, from using a common substrate for sessionization and subsequent statistical operators, namely Timely Dataflow.
TS is purely event-driven, ingesting and processing data on a record-at-a-time basis. Timely Dataflow epochs are based on the original event timestamps, at one second granularity leading to about 1.3M records per epoch. The ingestion interface is very simple: give sends a single record into the dataflow at the current epoch, and advance_to signals completion of the current epoch.
This issues a punctuation and allows the system to issue notifications which are used by the works to determine that their input can no longer produce data at earlier timestamps.
TS can easily be extended to accommodate new ad-hoc analytic tasks… “the dataflow-based model allows for reusing simpler tasks like sessionization to concisely compose more complex task and, hence, to better utilize the available resources. Examples shown in the pseudo-code [below] include computing trace tree durations (line 7), classifyig trees based on their structure (line 8), and identifying communication patterns (line 9).”

Evaluation
We demonstrate that, where other general stream processing platforms lag behind, TS can comfortably keep up with high-volume distributed streams of events in real time. By real time we mean that, for each second of input data in event time (epoch), TS can perform the respective analytics in less than a second so that all processing tasks are completed before the next batch of input arrives.
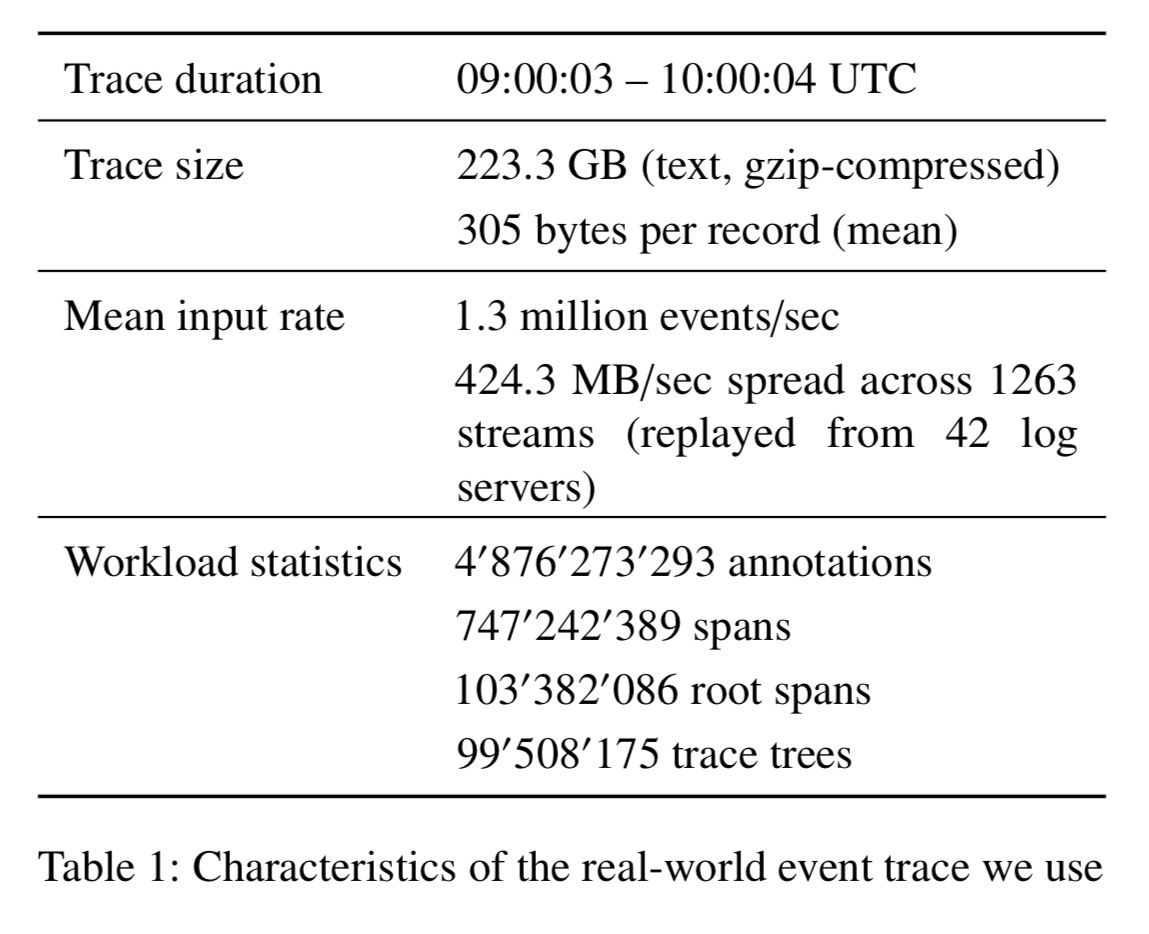
The evaluation is performed by replaying one hour of logs from a datacenter serving the travel industry:
The experimental system uses the open source Time Dataflow release compiled with Rust 1.14 and deployed in a four-node cluster. The following chart shows how well TS can keep up with the data ingestion rate using varying numbers of hosts and worker threads:
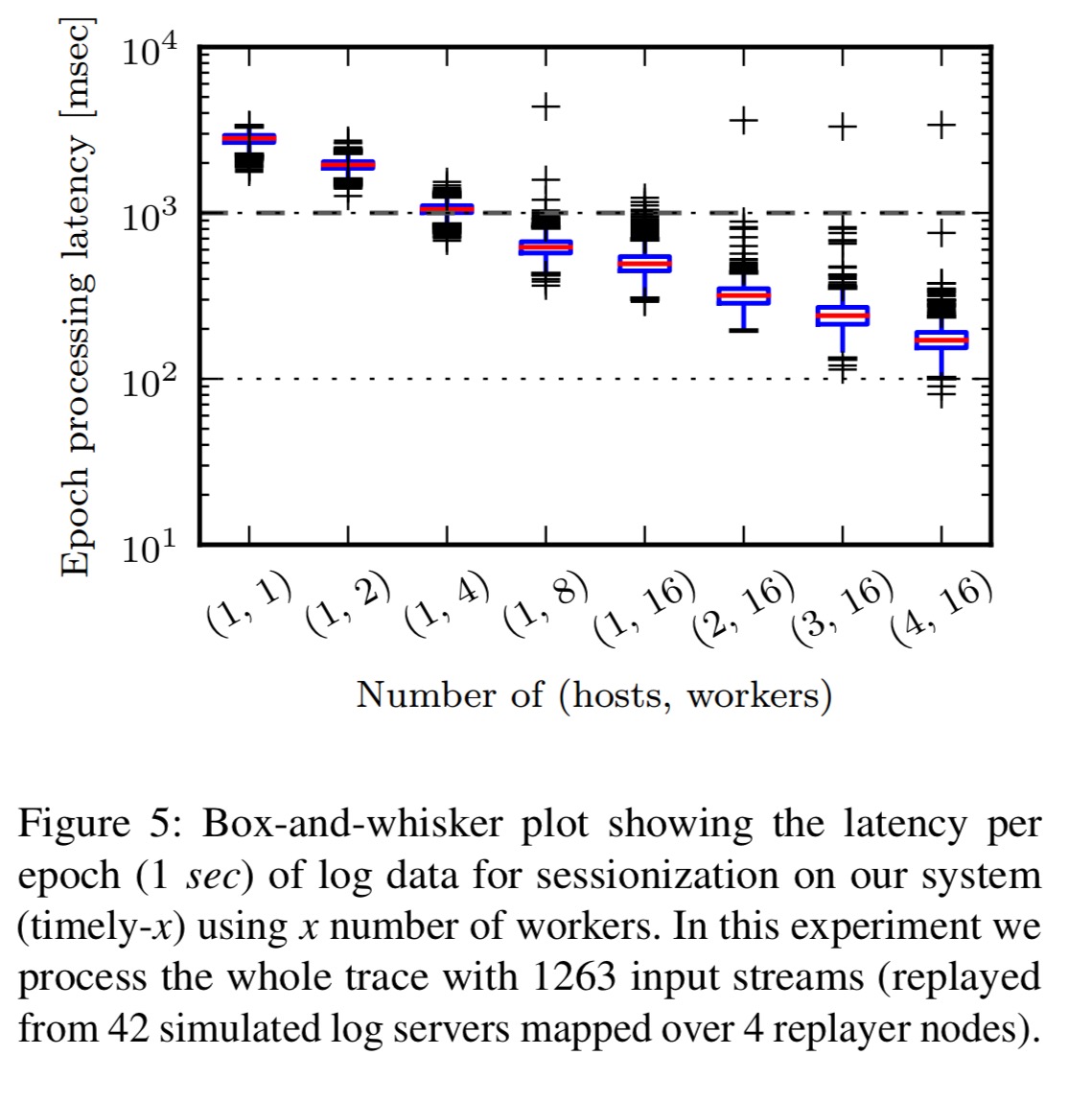
Our system is able to perform sessionization in real time (i.e., in less than a second) when using 8 or more workers.
A comparison implementation was done in Apache Flink, “a state of the art streaming engine which has a flexible design for windowing over data streams and which already accommodates the inactivity windows needed for sessionization as a built-in primitive.” The authors did their best to make a fair comparison (see details in §5.1), but Flink was unable to process the complete input stream. It was however possible to make a side-by-side comparison using a subset of the input stream:
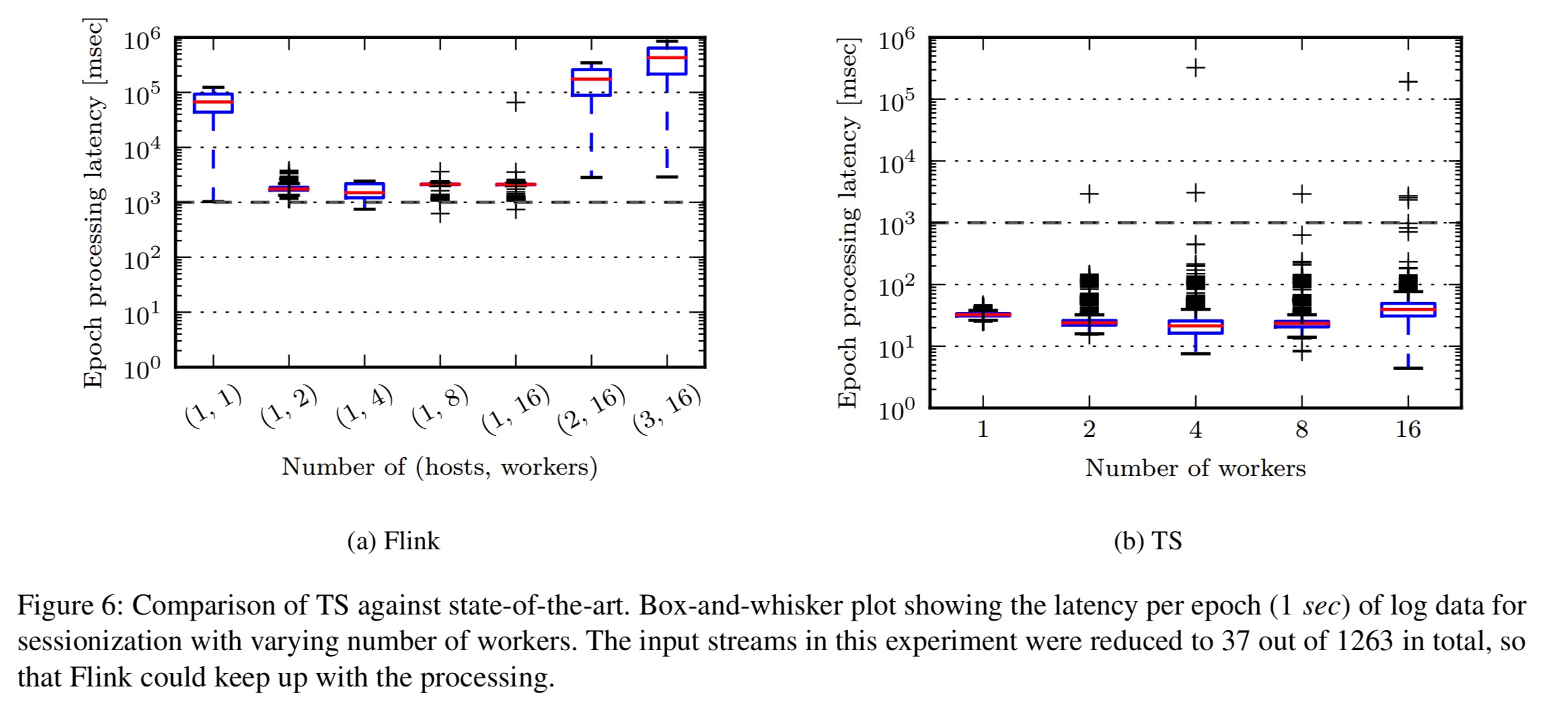
We observe a significant difference in the processing delay when comparing both systems on an identical workload… Flink spent on average 2.1 seconds (+/- 1.1s) for processing a single epoch of streaming logs whereas our system (with 16 workers) took only 26 milliseconds (+/- 53 ms).
(It would be interesting to see what e.g., the folks at dataArtisans could do when tuning Flink for this use case).
The memory footprint of the Rust-based TS is 203MB, whereas Flink’s Java heap rose above 7.5GB.
Overall these experiments demonstrate that our system can process logs in real-time with only the modest resources of a single modern multi-core machine.
(That’s an entire datacenter’s worth of logs!).
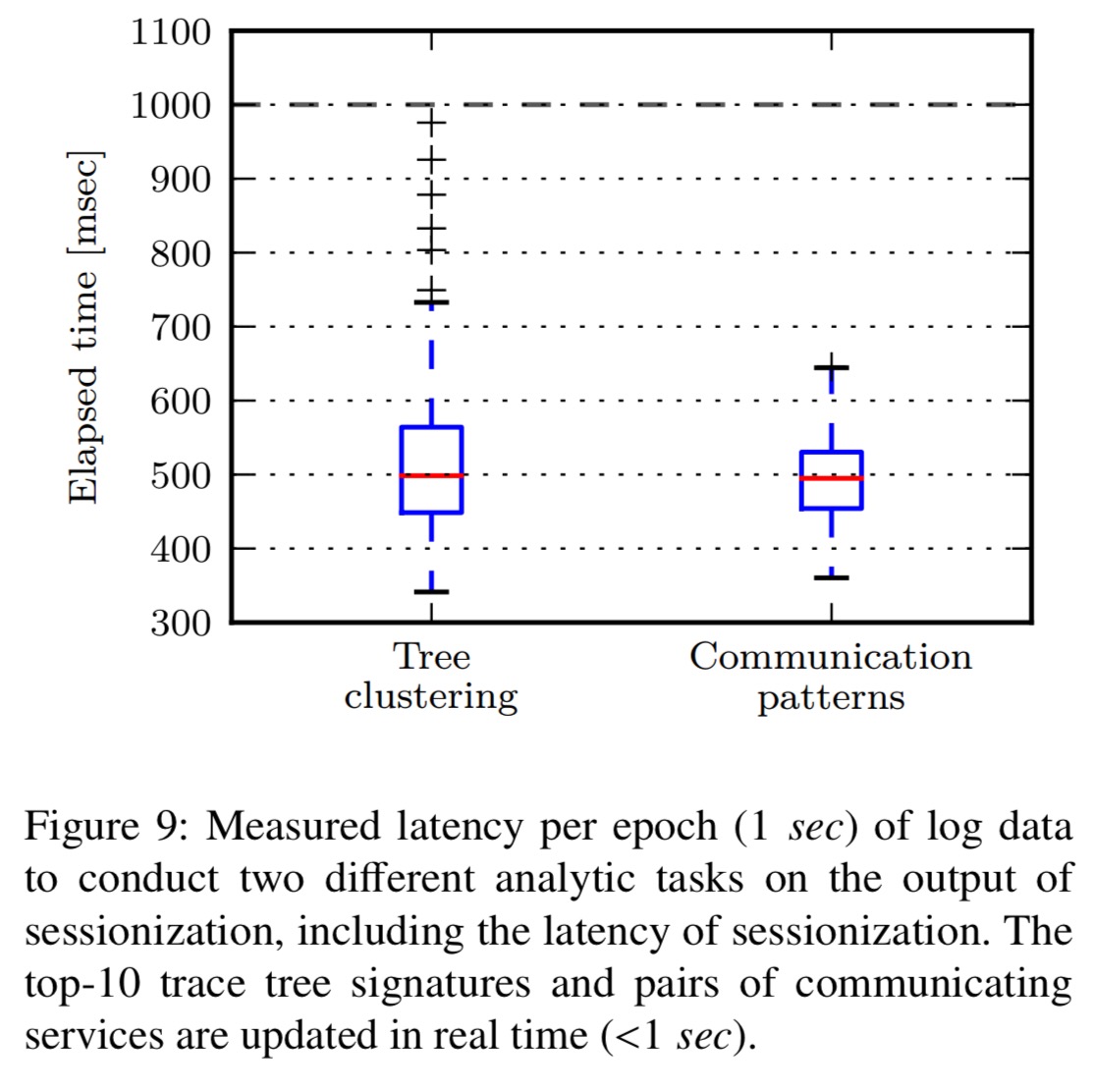
Beyond sessionization, the authors also analysed the latency of two analytic tasks built in TS: online trace tree clustering, and extracting the top-k most frequent pairs of communicating services per epoch of log data. Both are accomplished comfortable under the 1 second barrier:
TS (Timely Dataflow) currently lacks support for dynamic scaling and fault tolerance – for which existing work on recovery could be adopted.
While we expect this additional functionality to impact the performance of TS somewhat, we argue that TS still represents a far more efficient point in the design space for datacenter diagnostic foundations than existing general-purpose stream-processing systems.

Would it be possible to get access to the paper? Looks like it’s behind a paywall again. :-/
Hi Daniel, there’s a version here: http://people.inf.ethz.ch/ioannisl/eurosys2017.pdf sorry for the paywall issues. Regards, A.
Thank you, very much appreciated!
Just putting this here: I’ve been reading your posts every single morning for the last ~12 months. Very awesome work!