DStress: Efficient differentially private computations on distributed data Papadimitriou et al., EuroSys’17
Regulators would like to assess and manage the systemic risk in the banking system – for example, the likelihood that a few initial bankruptcies could cause a failure cascade.
In theory, it would be possible to quantify the risk of such a cascading failure by looking at the graph of financial dependencies between the banks, and in fact economists have already developed a number of metrics that could be used to quantify this “systemic” risk…
But in practice current audits are way less sophisticated than this. The information required to build the graph is extremely sensitive, and the banks prefer not to share it even with the government, let alone with each other!
In a recent working paper, the Office of Financial Research (OFR) has started investigating ways to perform system-wide stress tests while protecting confidentiality.
We can cast this as an instance of a really interesting computer science problem. Let there be 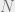
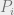
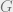
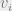

- Each participant learns nothing of the vertex properties of other participants (value privacy).
- The presence or absence of an edge
is not revealed to participants other than
and
(edge privacy).
- The final output
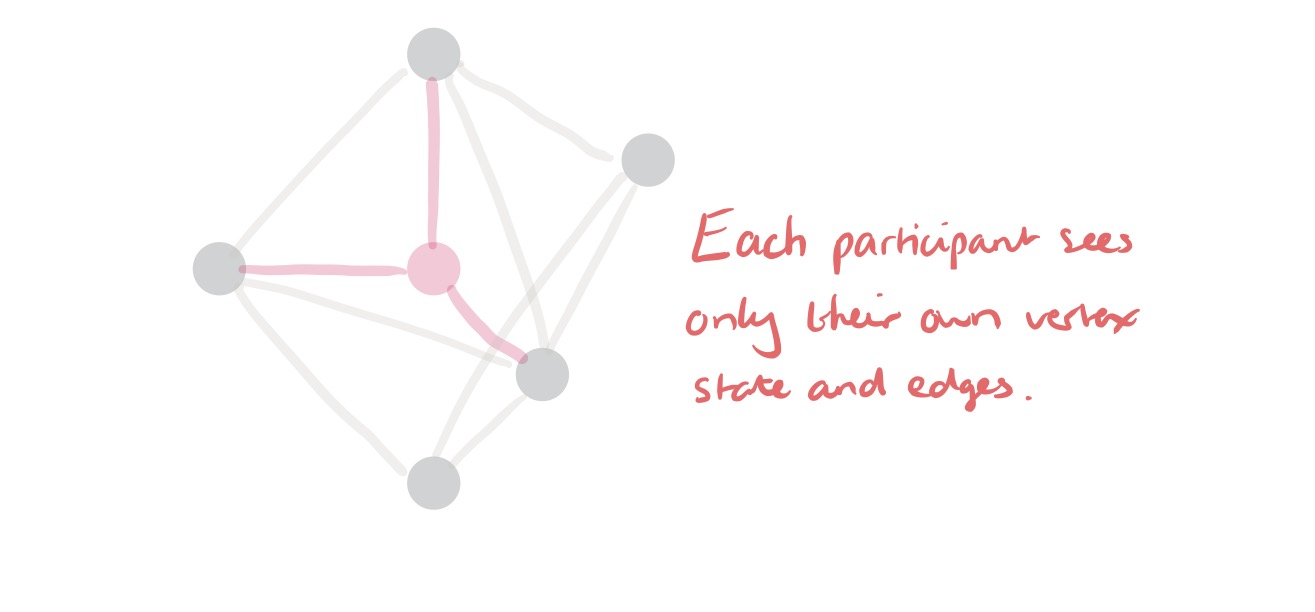
This fits the systemic risk calculation nicely – each financial institution is represented by a vertex, and the edges represent agreements between financial institutions. The function to be computed,
… Not all of these [graph] algorithms have privacy constraints, but there are many that do; for instance, cloud reliability, criminal intelligence, and social science all involve analyzing graphs that can span multiple administrative domains.
Building blocks
To meet all of its privacy obligations, DStress depends on three fundamental building blocks:
- Differential privacy is used to achieve output (
- Secure multiparty computation (MPC) enables a set of mutually distrustful parties to evaluate a function f over some confidential input data x, such that no party can learn anything about x other than what the output
reveals. DStress uses MPC to perform vertex calculations and aggregations without leaking any information from one vertex (bank) to others.
In the specific protocol we use (GMW), each party
initially holds a share
of the input
such that
(in other words the input can be obtained by XORing all the shares together), and after the protocol terminates, each party similarly hold a share
of the ouput
… GMW is collusion-resistant in the sense that, if
parties participate in the protocol, the confidentiality of
or the parties collude.
- ElGamal encryption is an encryption scheme that provides for both additive homomorphism and the ability to re-randomize public keys. DStress depends on both of these abilities.
ElGamal itself has multplicative homomorphism : if you encrypt two messages 









DStress: Putting it all together
DStress runs vertex programs. Each vertex has an initial state and an update function. In each iteration the update function is run for each vertex 


DStress runs in distributed fashion across a number of nodes:
We expect that, for privacy reasons, each participant would want to operate its own node, so that it does not have to reveal its initial state to another party.
No node can be allowed to see intermediate computation results – not even those of its own vertex. DStress uses shares from the GMW secure multiparty computation protocol to achieve this:
… DStress associates each node
of other nodes that we refer to as the block of i. The members of the block each hold a share of the vertex’s current state, and they use MPC to update the state based on incoming messages. To prevent colluding nodes from learning the state of a vertex, each block contains k + 1 nodes, where k is the collusion bound we have assumed.
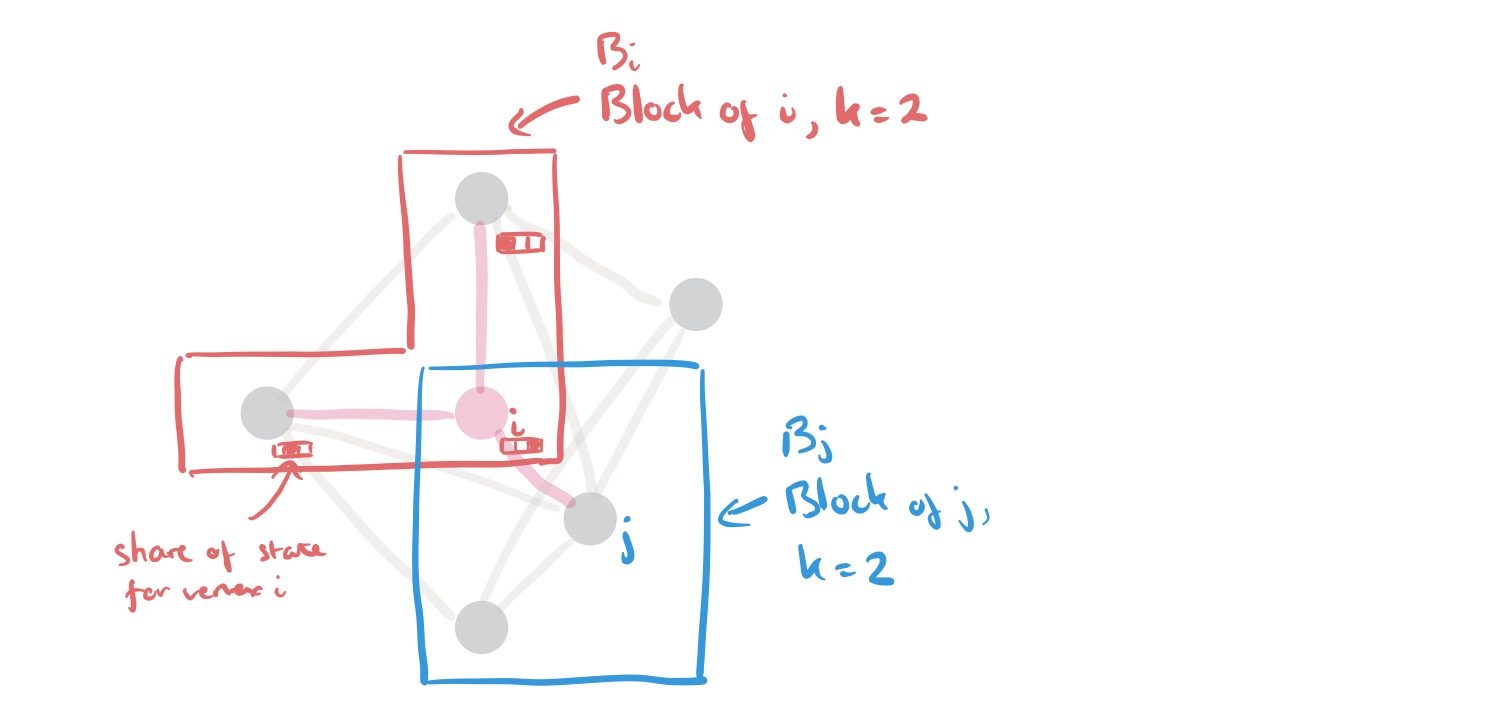
(In the sketch above, I happen to show the blocks for i and j overlapping, but there’s no reason this has to be the case).
A one-time setup step coordinated by a trusted party (e.g., a regulator) associates each node with a block containing k + 1 different nodes, and gives the block D different sets of public keys, where D is a publicly known upper bound on the degree of any node in the graph. This can all be done without the trusted party ever learning the topology of the graph.
At the start of the algorithm, each node loads the initial state of its local vertex together with D copies of the no-op message (there are no real messages yet), and splits each of those messages into 
We now perform n iterations (fixed in advance with an n chosen to give convergence with high likelihood) of the computation and communication steps.
- In the computation step the members of block
use MPC to evaluate the update function of the vertex
- In the communication step messages are sent along the corresponding edges of the graph, using a protocol we’ll look at next
After the n iterations, a special aggregation block 
Each block sends its state shares and some random shares to
; the members of
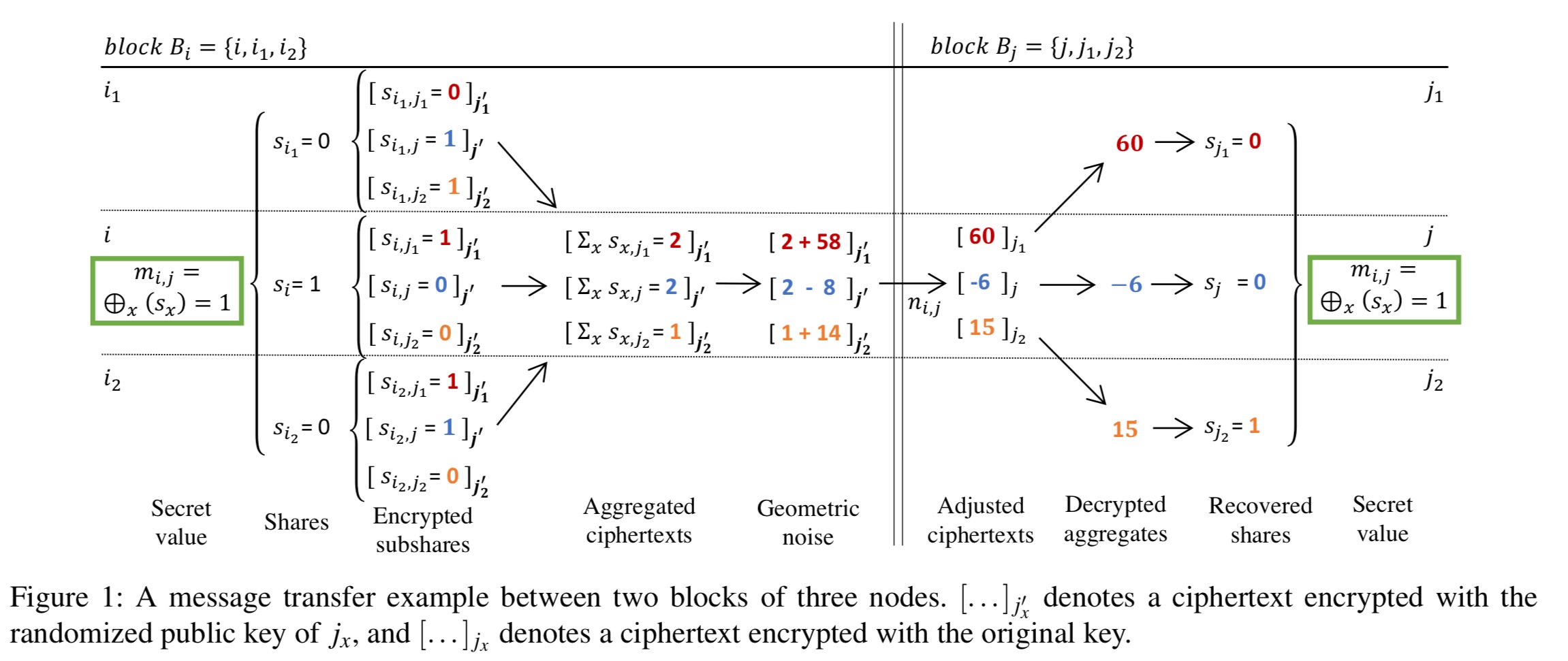
How DStress sends messages between vertices
Each member of a block 

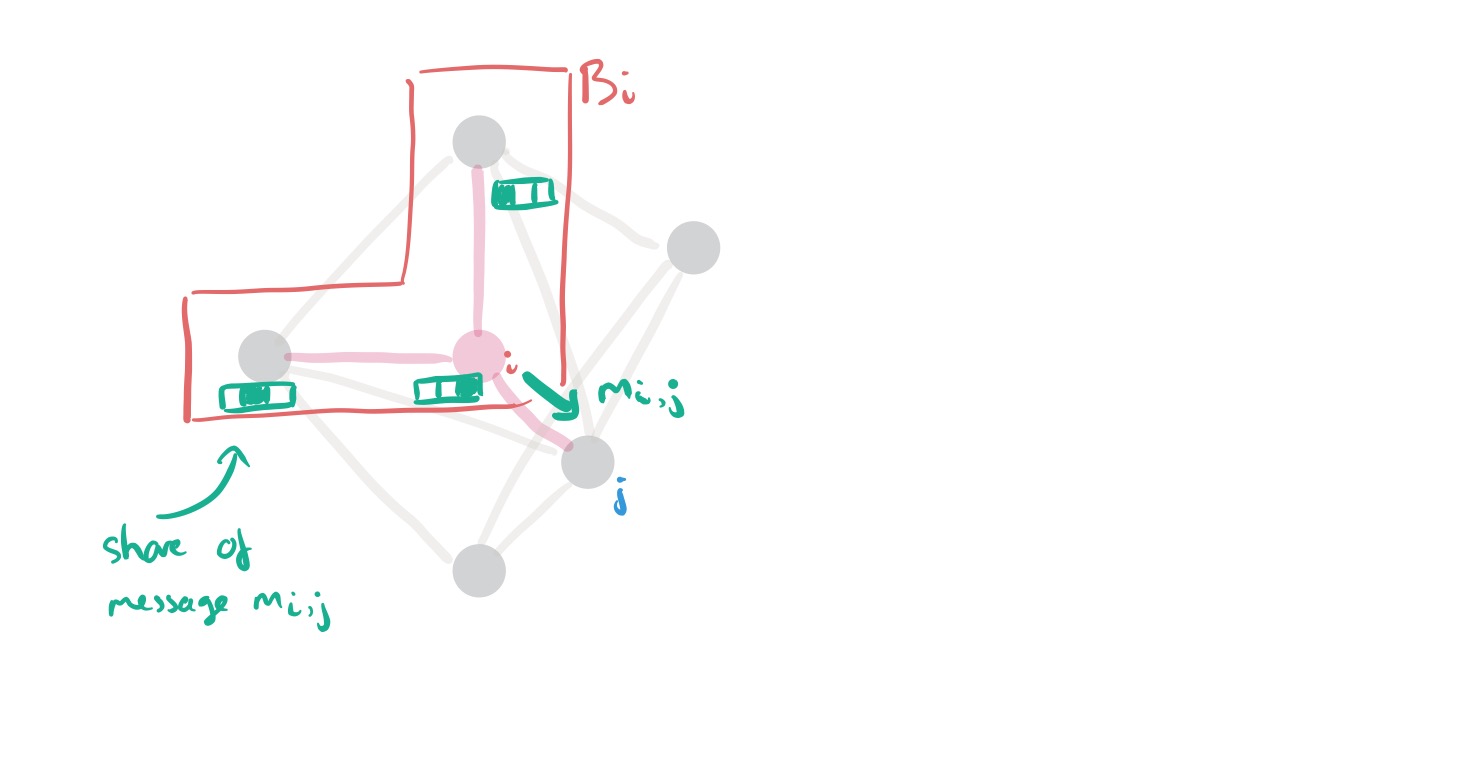
The basic idea is for each member of 
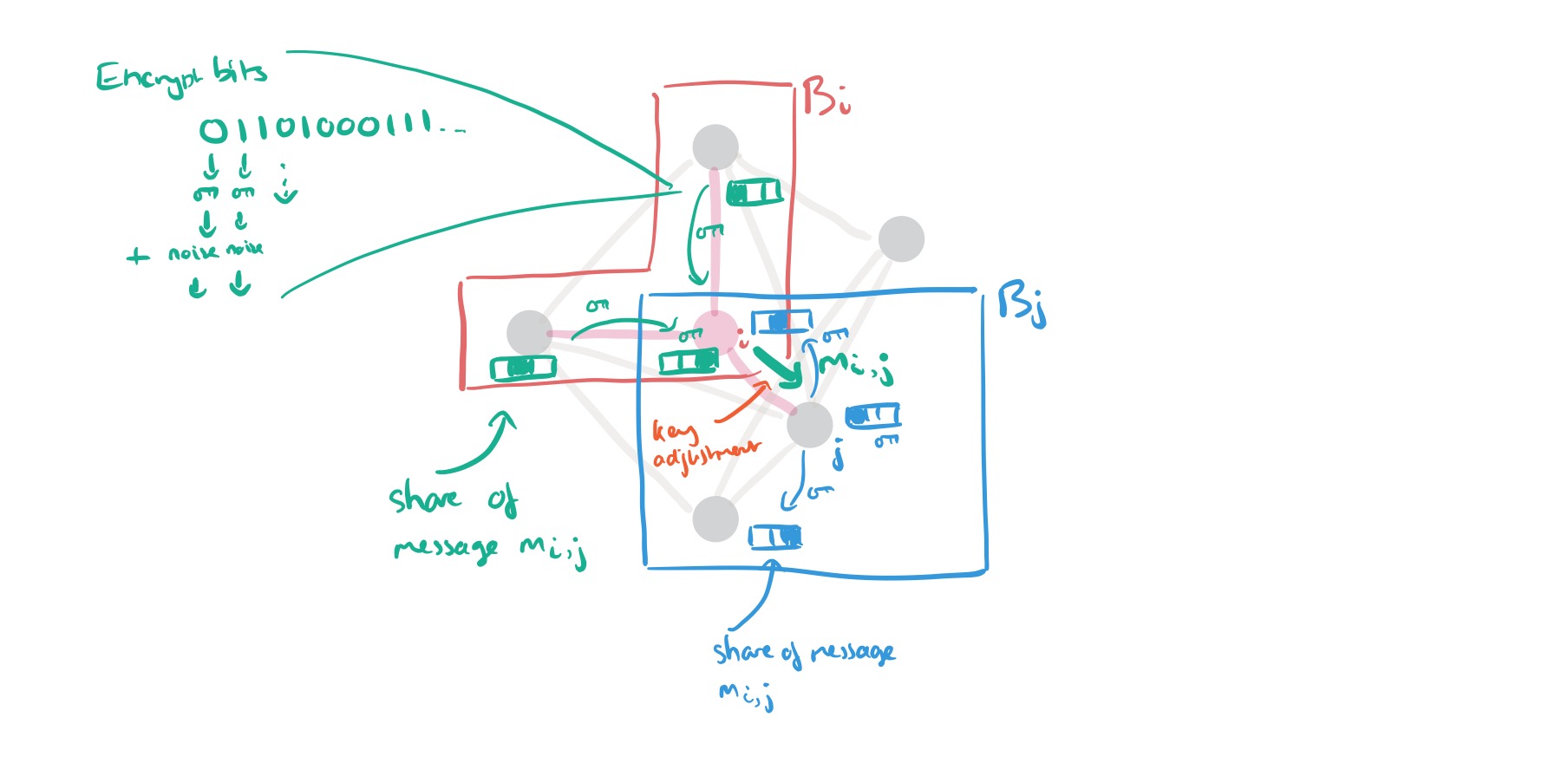
If a node happens to be a member of both blocks though (as in my sketch above), it can potentially learn two shares this way. To prevent this we make a tweak whereby each share is itself split into k+1 subshares, and these subshares are then split into individual bits, each encrypted separately. Before forwarding to
Demonstrating feasibility.
The authors show how to map two existing systemic risk algorithms from the literature onto DStress’ programming model. Here’s one of them as an example (see section 4.2 for a brief description of the original algorithm).

The output of the computation is a measure called the total dollar shortfall (TDS) – the amount of extra money the government would need to make available to prevent failures. Adding noise to TDS results in dollar-differential privacy.
An evaluation is run on Amazon EC2 using 100 m3.xlarge instances. From that data gathered there, it is possible to estimate the costs for running a systemic risk calculation for the roughly 1,750 commercial banks in the United States. A degree bound of D = 100 is used, and k is set to 20 (the largest known colluding network to date had 16 member banks). The projected costs for the computation are shown in the following figure:
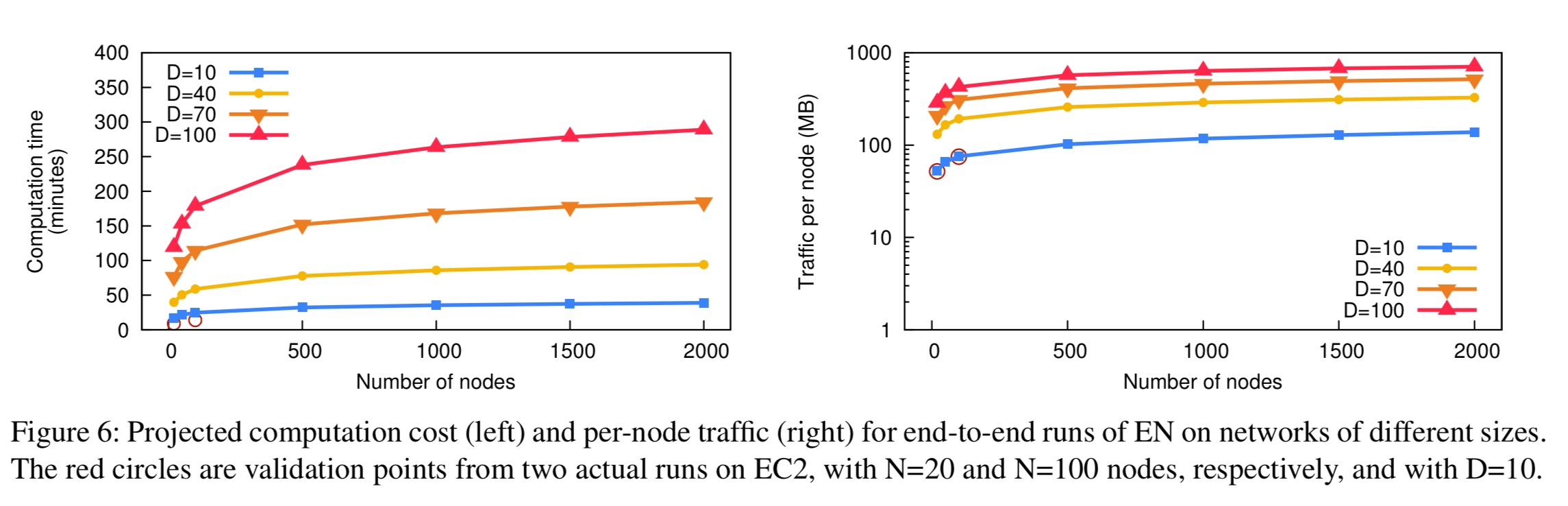
Based on these results, we estimate that an end-to-end run of Eisenberg-Noe for the entire U.S. banking system (N=1,750, D=100) would take 4.8 hours and consume about 750MB of traffic. These costs seem low enough to be practical.
(Without using DStress, and just treating the whole calculation as a large MPC problem, the authors calculate the computation time as about 287 years!).
Section 4.5 of the paper contains an analysis of how frequently this computation can be done such that no adversary can increase their confidence in any fact about the input data by more than a factor of two. The bottom line is that it can be done three times a year:
Since banks must retrospectively disclose their aggregate positions every year anyway, it seems reasonable to replenish the privacy budget once per year. Thus, it seems safe to execute Elliot-Golub-Jackson up to (ln 2) / 0.23, or approximately 3 times per year, which is more frequent than today’s annual stress tests.

Great diagrams*. May I know what software you used to make them? :)
* https://adriancolyer.files.wordpress.com/2017/05/dstress-sketch-2.jpeg?w=640
I eventually came to the conclusion that the quickest way to make the diagrams is to hand-draw them! I used to do this with pen and paper and scan them, but now I use a stylus on an iPad Pro, and an app called Notability. So my process is generally just to do a quick sketch and then take a screenshot, trim it in the Photos app, and upload it to WordPress using a Workflow automation.
cool! thanks.
by the way, great blog :D