Naiad: A Timely Dataflow System – Murray et al. 2013
Many data processing tasks require low-latency interactive access to results, iterative sub-computations, and consistent intermediate outputs so that sub-computations can be nested and composed. (For example, an) application that performs iterative processing on a real-time data stream, and supports interactive queries on a fresh, consistent view of the results.
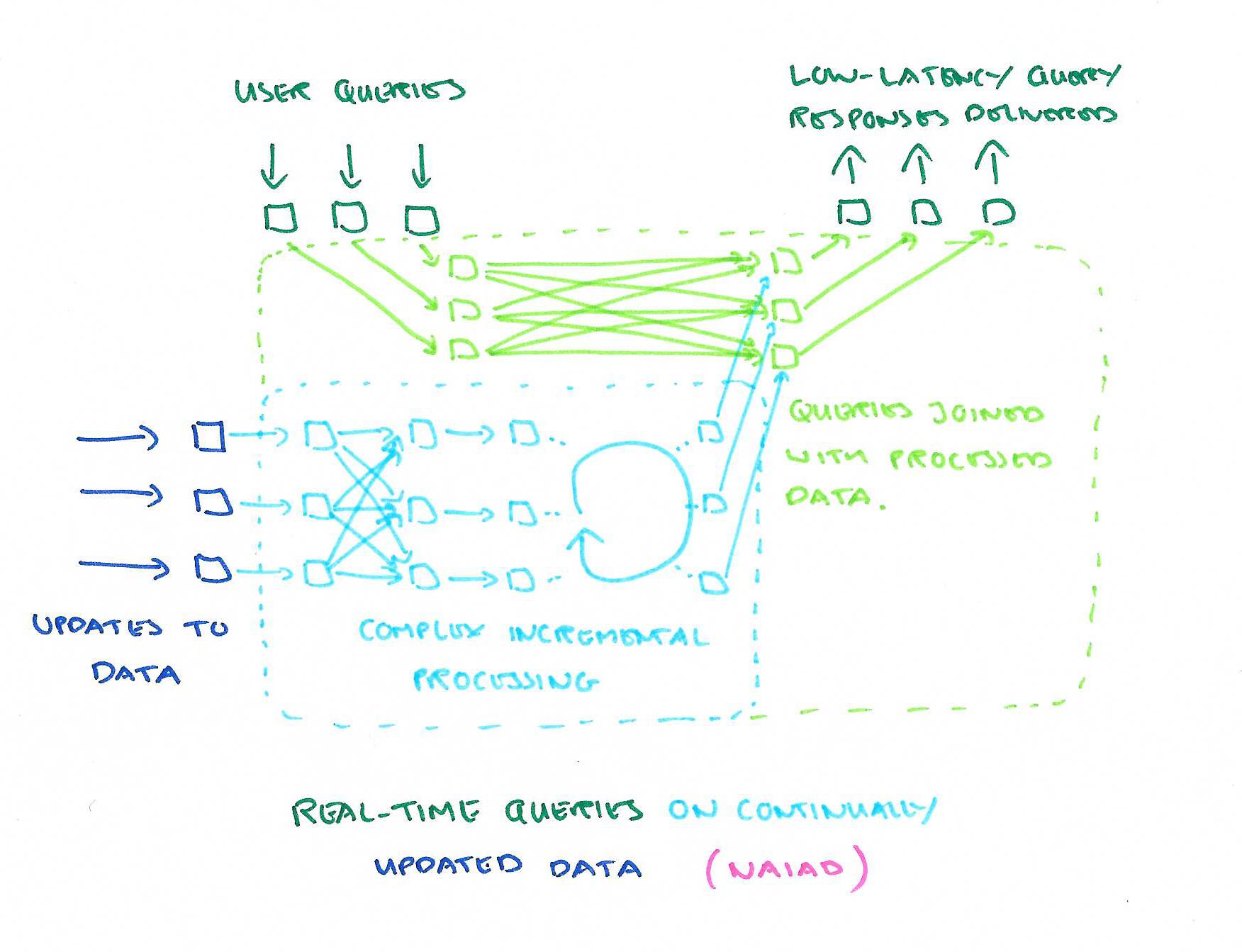
You can build this by bolting together stream processors, batch systems, and triggers, but “applications built on a single platform are typically more efficient, succinct, and maintainable.”
Our goal is to develop a general-purpose system that fulfils all of these requirements and supports a wide variety of high-level programming models, while achieving the same performance as a specialized system.
That system is Naiad, and at its core is a new computational model called timely dataflow. Something I really like in this work is the way that the timely dataflow abstraction supports the building of higher-level programming models on top – all the while retaining the ability to drop-down to the lower level for finer-grained control when you need it.
We designed Naiad so that common timely dataflow patterns can be collected into libraries, allowing users to draw from these libraries when they meet their needs and to construct new timely dataflow vertices when they do not, all within the same program…. This separation of library code from system code makes it easy for users to draw from existing patterns, create their own patterns, and adapt other patterns, all without requiring access to private APIs. Public reusable low-level programming abstractions distinguish Naiad from a number of other data parallel systems that enforce a single high-level programming model, and conceal the boundary between this model and lower-level primitives within private system code.
Higher level libraries include incremental LINQ-like operators, a subset of the Bloom framework (which composes with other LINQ operators), and a version of the Pregel Bulk Synchronous Parallel model. Implementations of PageRank, Strongly Connected Components, Weakly Connected Components, and Approximate Shortest Path algorithms in Naiad require 30, 161, 49, and 70 lines of non-library code respectively. A version of PageRank is also built on top of the PowerGraph Gather, Apply, Scatter model with vertex-cutting – this required 547 lines of code “many of which could be reused for other programs in the GAS model.”
To demonstrate batch iterative processing prowess, the team rebuilt part of Vowpal Wabbit’s logistic regression pipeline in Naiad. This took around 300 lines of code, and…
The experiment shows that Naiad is competitive with a state-of-the-art custom implementation for distributed machine learning, and that it is straightforward to build communication libraries for existing applications using Naiad’s API.
For streaming acyclic computation the k-exposure metric from Kineograph was implemented.
> We implement k-exposure in 26 lines of code using standard data parallel operators of Distinct, Join, and Count. When run on the same Twitter stream as Kineograph, using 32 computers and ingesting 1,000 tweets per epoch on each machine, the average throughput over five runs is 482,988 t/s with no fault-tolerance, 322,439 t/s with checkpoints every 100 epochs, and 273,741 t/s with continual logging.
(Kineograph itself does 185,000 t/s on the same hardware).
As an example of bringing all of this together, the team wrote an application that ingests a continually arriving stream of tweets, extracts hashtags and mentions of other users, computes the most popular hashtag in each connected component of the graph of users mentioning other users, and provides interactive access to the top hashtag in a user’s connected component. “The logic of the program, not including standard operators and an implementation of connected components, requires 27 lines of code.”
Naiad’s performance and expressiveness demonstrate that timely dataflow is a powerful general-purpose low-level programming abstraction for iterative and streaming computation. Our approach contrasts with that of many recent data processing projects, which tie new high-level programming patterns to specialized system designs. We have shown that Naiad can implement the features of many of these specialized systems, with equivalent performance, and can serve as a platform for sophisticated applications that no existing system supports.
It’s time to take a look at this unifying, general purpose, efficient abstraction called timely dataflow…
The Timely Dataflow abstraction
Timely dataflow supports the following features:
- structured loops allowing feedback in the dataflow
- stateful dataflow vertices capable of producing and consuming records without global coordination
- notifications for vertices once they have received all records for a given round of input or loop iteration.
Together, the first two features are needed to execute iterative and incremental computations with low latency. The third feature makes it possible to produce consistent results, at both outputs and intermediate stages of computations, in the presence of streaming or iteration.
Timely dataflow is based on a directed graph with vertices at the nodes and logically timestamped messages flowing along edges. The graph may contain cycles. Input vertices receive sequences of messages from external producers, and output vertices send a sequence of messages out to external consumers. Producers label each message with an integer epoch, and notify the input vertex when they will send no more messages within the given epoch. A producer can also close an input vertex which means that it will send no more messages at all (in any epoch). Output messages are likewise labelled with the epoch, and output vertex signals to a consumer when it will not send any more messages in an epoch.
Timely dataflow graphs are directed graphs with the constraint that the vertices are organized into possibly nested loop contexts, with three associated system-provided vertices. Edges entering a loop context must pass through an ingress vertex and edges leaving a loop context must pass through an egress vertex. Additionally, every cycle in the graph must be contained entirely within some loop context, and include at least one feedback vertex that is not nested within any inner loop contexts.
The structure supports logical timestamps that include the epoch number and a loop iteration counter for each encountered loop. An ordering is defined for these timestamps, which corresponds to the constraint that a ‘later’ timestamped message cannot possibly be the cause of an earlier timestamped one. That is, if t1 < t2; then t1 ‘happens-before’ t2. The model supports concurrent execution of different epochs and iterations.
A vertex simply implements two callbacks:
ONRECV(e : Edge, m : Message, t: Timestamp)
ONNOTIFY(t : Timestamp)
ONRECV is used to deliver a message, and ONNOTIFY informs a vertex that it has received all messages for the timestamp.
A vertex may call SENDBY(e : Edge, m : Message, t: Timestamp) to send a message along an edge to another vertex, and NOTIFYAT(t : Timestamp) to request notification (via ONNOTIFY) once all messages bearing that timestamp or earlier have been delivered. (I found the prose in the paper a little hard to follow here, but looking at the online documentation for the Vertex type helped to clear things up).
The ONRECV and ONNOTIFY methods may contain arbitrary code and modify arbitrary per-vertex state, but do have an important constraint on their execution: when invoked with a timestamp t, the methods may only call SENDBY or NOTIFYAT with times t′ ≥ t. This rule guarantees that messages are not sent “backwards in time” and is crucial to support notification.
Invocations of ONRECV and ONNOTIFY are queued, and the model is flexible as to the order of delivery with the following constraint:
a timely dataflow system must guarantee that v.ONNOTIFY(t) is invoked only after no further invocations of v.ONRECV(e,m, t′), for t′ ≤ t, will occur. v.ONNOTIFY(t) is an indication that all v.ONRECV(e,m, t) invocations have been delivered to the vertex, and is an opportunity for the vertex to finish any work associated with time t.
The scheduler uses timestamps to figure out which events can be safely delivered:
Messages in a timely dataflow system flow only along edges, and their timestamps are modified by ingress, egress, and feedback vertices. Since events cannot send messages backwards in time, we can use this (graph) structure to compute lower bounds on the timestamps of messages an event can cause. By applying this computation to the set of unprocessed events, we can identify the vertex notifications that may be correctly delivered.
Naiad is a high-performance distributed implementation of the timely dataflow model, a group of processes host workers that each manage a partition of the timely dataflow vertices.
Workers exchange messages locally using shared memory, and remotely using TCP connections between each pair of processes. Each process participates in a distributed progress tracking protocol, in order to coordinate the delivery of notifications.
See the full paper for details of the implementation and optimisations, as well as a detailed evaluation.

Very helpful. Thank you.