Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems – Mace et al. 2015
Problems in distributed systems are complex, varied, and unpredictable. By default, the information required to diagnose an issue may not be reported by the system or contained in system logs. Current approaches tie logging and statistics mechanisms into the development path of products, where there is mismatch between the expectations and incentives of the developer and the needs of operators and users. Panelists at SLAML discussed the important need to “close the loop of operations back to developers”.
The authors offer plenty of evidence from Apache issue trackers that log messages are not often systematically designed with the goal of supporting failure diagnosis in mind.
At the same time as not having the information you need, it’s also common to drown in a sea of information you don’t need!
The glut of recorded information presents a “needle-in-a -haystack” problem to users; while a system may expose information relevant to a problem, e.g. in a log, extracting this information requires system familiarity developed over a long period of time. For example, Mesos cluster state is exposed via a single JSON endpoint and can become massive, even if a client only wants information for a subset of the state.
In contrast, dynamic tracing (as embodied by Pivot Tracing) enables you to turn on and off instrumentation at runtime and hence avoid making the choice of what to record a priori. (In this respect, it works very similarly to load-time weaving in AspectJ).
This brings us to the second challenge Pivot Tracing addresses. In multi-tenant, multi-application stacks, the root cause and symptoms of an issue may appear in different processes, machines, and application tiers, and may be visible to different users. A user of one application may need to relate information from some other dependent application in order to diagnose problems that span multiple systems.
While several systems have looked at the problem of end-to-end request tracing (including Dapper, Zipkin), and Apache Htrace, “most of these systems record or reconstruct traces of execution for offline analysis, and thus share the problems above with the first challenge, concerning what to record.”
Pivot Tracing is a dynamic monitoring and tracing framework for distributed systems that supports:
- dynamically configuring and installing monitoring at runtime
- low system overhead for ‘always-on’ monitoring
- capture of causality between events from multiple processes and applications
Pivot Tracing will be familiar to anyone who has studied AspectJ – there are ‘TracePoints’ (pointcuts), advice, and a ‘happens-before’ relationship that is very like AspectJ’s cflow mechanism.
Queries in Pivot Tracing refer to variables exposed by one or more tracepoints – places in the system where Pivot Tracing can insert instrumentation. Tracepoint definitions are not part of the system code, but are rather instructions on where and how to change the system to obtain the exported identifers. Tracepoints in Pivot Tracing are similar to pointcuts from aspect-oriented programming, and can refer to arbitrary interface/method signature combinations.
All tracepoints export a few variables by default: host, timestamp, process id, process name, and the tracepoint definition (cf. ‘thisJoinPoint’). Additional variables to be exported are specified as part of the TracePoint definition (cf. AspectJ’s binding pointcut expressions).
Pivot Tracing models system events as tuples of a streaming, distributed data set. Users submit relational queries over this data set, which get compiled to an intermediate representation called advice. Advice uses a small instruction set to process queries, and maps directly to code that local Pivot Tracing agents install dynamically at relevant tracepoints. Later, requests executing in the system invoke the installed advice each time their execution reaches the tracepoint.
Here’s an example query that causes each machine to aggregate the delta argument each time incrBytesRead is invoked, grouping by the host name. Each machine reports its local aggregate every second:
From incr in DataNodeMetrics.incrBytesRead
GroupBy incr.host
Select incr.host, SUM(incr.delta)
This second example query is designed to show the global HDFS read throughput of each client application:
From incr in DataNodeMetrics.incrBytesRead
Join cl In First(ClientProtocols) On cl -> incr
GroupBy cl.procName
Select cl.procName, SUM(incr.delta)
The -> symbol indicates a happened-before join. Pivot Tracing’s implementation will record the process name the first time the request passes through any client protocol method and propagate it along the execution. Then, whenever the execution reaches incrBytesRead on a DataNode, Pivot Tracing will emit the bytes read or written, grouped by the recorded name.
Emitted tuples are aggregated locally and then streamed to the client over a message bus.
Supported query operations include projection, selection, grouping, and aggregation (count, sum, min, max and average). There are also temporal filters: MostRecent, MostRecentN, First, and FirstN.
In the prototype implementation Pivot Tracer’s load-time weaver is implemented using Javassist and a Java debug agent that can rewrite bytecode using the java.lang.instrument package. The weaver is instructed by local agents…
A Pivot Tracing agent thread runs in every Pivot Tracing-enabled process and waits instruction via a central pub/sub server to weave advice to tracepoints. Tuples emitted by advice are accumulated by the local Pivot Tracing agent, which performs partial aggregation of tuples according to their source query. Agents publish partial query results at a configurable interval – by default, one second.
Pivot Tracing is evaluated in the context of the Hadoop stack, where HDFS, HBase, Hadoop MapReduce, and YARN were instrumented.
In order to support Pivot Tracing in these systems, we made one-time modifications to propagate baggage along the execution path of requests…. Our prototype uses a thread-local variable to store baggage during execution, so the only required system modifications are to set and unset baggage at execution boundaries. To propagate baggage across remote procedure calls, we manually extended the protocol definitions of the systems. To propagate baggage across execution boundaries within individual processes we implemented AspectJ instrumentation to automatically modify common interfaces (Thread, Runnable, Callable, and Queue). Each system only required between 50 and 200 lines of manual code modification. Once modified, these systems could support arbitrary Pivot Tracing queries without further modification.
(‘baggage’ is the mechanism by which per-request tuples are propagated along an execution path).
To estimate the impact on throughput and latency a series of benchmarks were run which indicated no significant performance change with tracing enabled. (Though many of these benchmarks bottlenecked on network or disk i/o). With CPU-bound requests the application level overhead with Pivot Tracing enabled is at most 0.3%.
JVM HotSwap requires Java’s debugging mode to be enabled, which causes some compiler optimizations to be disabled. For practical purposes, however, HotSpot JVM’s full-speed debugging is sufficiently optimized that it is possible to run with debugging support always enabled. Our HDFS throughput experiments above measured only small overhead between debugging enabled and
disabled. Reloading a class with woven advice has a one-time cost of approximately 100ms, depending on the size of the class being reloaded.
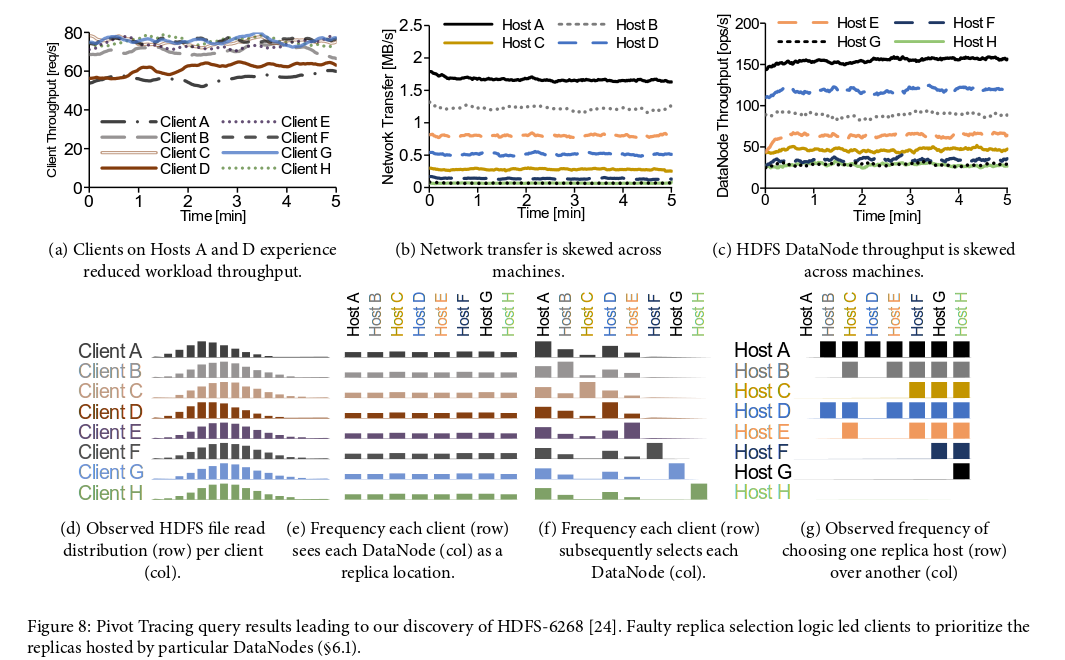
See the full paper for some excellent worked examples of Pivot Tracing being used to diagnose bugs in Hadoop.

4 thoughts on “Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems”
Comments are closed.