An empirical study on the correctness of formally verified distributed systems Fonseca et al., EuroSys’17
“Is your distributed system bug free?”
“I formally verified it!”
“Yes, but is your distributed system bug free?”
There’s a really important discussion running through this paper – what does it take to write bug-free systems software? I have a real soft-spot for serious attempts to build software that actually works. Formally verified systems, and figuring out how to make formal verification accessible and composable are very important building blocks at the most rigorous end of the spectrum.
Fonseca et al. examine three state-of-the-art formally verified implementations of distributed sytems: Iron Fleet, Chapar: Certified causally consistent distributed key-value stores, and Verdi. Does all that hard work on formal verification verify that they actually work in practice? No.
Through code review and testing, we found a total of 16 bugs, many of which produce serious consequences, including crashing servers, returning incorrect results to clients, and invalidating verification guarantees.
The interesting part here is the kinds of bugs they found, and why those bugs were able to exist despite the verification. Before you go all “see I told you formal verification wasn’t worth it” on me, the authors also look at distributed systems that were not formally verified, and the situation there is even worse. We have to be a little careful with our comparisons here though.
To find bugs in unverified (i.e., almost all) distributed systems, the authors sample bugs over a one year period, from the issue trackers of a number of systems:
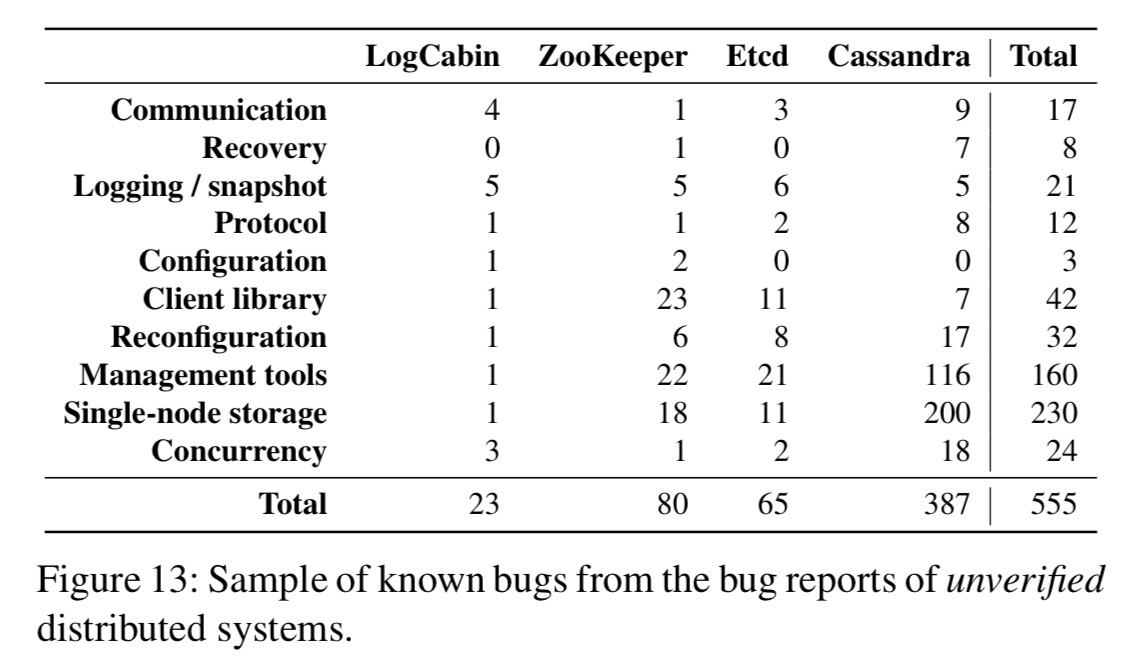
These unverified systems are not research prototypes; they implement numerous and complex features, have been tested by innumerable users, and were built by large teams.
The unverified systems all contained protocol bugs, whereas none of the formally verified systems did. (Still, I’ve never met a user whom, upon having a system crash on them and generating incorrect results, said “Oh well, at least it wasn’t a protocol bug” ;) ).
Now, why do I say we have to be a little careful with our comparisons? The clue is in the previous quote – the unverified systems chosen “have been tested by innumerable users.” I.e., they’ve been used in the wild by lots of different people in lots of different environments, giving plenty of occasion for all sorts of weird conditions to occur and trip the software up. The formally verified ones have not been battle tested in the same way. And that’s interesting, because when you look at the bugs found in the formally verified systems, they relate to assumptions about the way the environment the system interacts with behaves. Assumptions that turn out not to hold all the time.
Bugs in formally verified systems! How can that be?
The bugs found by the team fall into three categories. By far the biggest group of bugs relate to assumptions about the behaviour of components that the formally verified system interacts with. These bugs manifest in the interface (or shim layer) between the verified and non-verified components.
These interface components typically consist of only a few hundred lines of source code, which represent a tiny fraction of the entire TCB (e.g., the OS and verifier). However, they capture important assumptions made by developers about the system; their correctness is vital to the assurances provided by verification and to the correct functioning of the system.
Two of the sixteen found bugs were in the specification of the systems analyzed: “incomplete or incorrect specification can prevent correct verification.” The team also found bugs in the verification tools themselves – causing the verifier to falsely report that a program passes verification checks for example! All of these verifier bugs were caused by functions that were not part of the core components of the verifier.
Let’s come back to those misplaced assumptions though. What’s most interesting about them, is that many of these assumptions (with the benefit of hindsight!) feel like things the designers should obviously have known about and thought about. For example:
- The Verdi server wrongly assumed that the
recvsystem call would always return an entire request in a single invocation, and failed when given a partial request. - Chapar used UDP, but did not handle packet drops because it assumed the network layer was reliable.
- Verdi used newlines and spaces to distinguish commands and arguments, but did not escape these characters leading to a variety of issues
- Developers assumed that a single or set of disk operation(s) are atomic during crashes (whereas readers of The Morning Paper know better! See for example All File Systems are not created equal: on the complexity of crafting crash consistent applications, and Redundancy does not imply fault tolerance: analysis of distributed storage reactions to single errors and corruptions)
- Buffers too small to handle all possible inputs
- Not respecting input size limits in library calls made by the system
And these are developers trying their very best to produce a formally verified and correct system. Which I think just goes to show how hard it is to keep on top of the mass of detail involved in doing so.
There were also a few bugs found which would always be tough to discover, such as subtle gotchas lurking in the libraries used by the system.
In total, 5 of 11 shim layer bugs related to communication:
Surprisingly, we concluded that extending verification efforts to provide strong formal guarantees on communication logic would prevent half of the bugs found in the shim layer, thereby significantly increasing the reliability of these systems. In particular, this result calls for composable, verified RPC libraries.
How can we build real-world “bug-free” distributed systems?
After discovering these gaps left by formal verification, the authors developer a toolchain called “PK,” which is able to catch 13 of the 16 bugs found. This includes:
- Building in integrity checks for messages, and abstract state machines
- Testing for liveness using timeout mechanisms
- A file system and network fuzzer
- Using negative testing by actively introducing bugs into the implementation and confirming that the specification can detect them during verification.
- Proving additional specification properties (to help find specification bugs). “Proving properties about the specification or reusing specifications are two important ways to increase the confidence that they are correct.”
- Implementing chaos-monkey style test cases for the verifier itself. “We believe the routine application to verifiers of general testing techniques (e.g., sanity checks, test-suites, and static analyzers) and the adoption of fail-safe designs should become establish practices.”
Also of interest in this category are Jepsen,
Lineage-driven fault injection, Redundancy does not imply fault tolerance: analysis of distributed storage reactions to single errors and corruptions, and Uncovering bugs in distributed storage systems during testing (not in production!).
The answer is not to throw away attempts at formal verification (“we did not find any protocol-level bugs in any of the verified prototypes analyzed, despite such bugs being common even in mature unverified distributed systems“). Formal verification can bring real benefits to real systems (see e.g., Use of formal methods at Amazon Web Services). I was also delighted to see that Microsoft’s Cosmos DB team also made strong use of formal reasoning with TLA+:
“When we started out in 2010, we wanted to build a system – a lasting system. This was the database of the future for Microsoft… we try to apply as much rigor to our engineer team as we possible can. TLA+ has been wonderful in getting that level of rigor in a team of engineers to set the bar high for quality.” – CosmosDB interview with Dharma Shukla on TechCrunch
Instead we must recognise that even formal verification can leave gaps and hidden assumptions that need to be teased out and tested, using the full battery of testing techniques at our disposal. Building distributed systems is hard. But knowing that shouldn’t make us shy away from trying to do the right thing, instead it should make us redouble our efforts in our quest for correctness.
We conclude that verification, while beneficial, posits assumptions that must be tested, possibly with testing toolchains similar to the PK toolchain we developed.
Here are a few other related papers we’ve covered previous in The Morning Paper that I haven’t already worked into the prose above:

> I’ve never met a user whom, upon having a system crash on them and generating incorrect results, said “Oh well, at least it wasn’t a protocol bug”
That may be so, but protocol bugs may be particularly costly to fix once discovered, as they may be a result of serious design flaws.
That’s a very fair point – design bugs are usually much more costly to fix than implementation bugs!
This paper is a little misleading in that Zookeeper’s underlying protocol, ZAB, has been formally proved. See https://fpjdotme.files.wordpress.com/2016/07/yl-2010-007.pdf
I believe that this hand proof was subsequently automated with TLA+, but don’t have a reference or any substantiation.
If anything, this supports the use of proofs since Cassandra didn’t have a proven protocol.