Redundancy does not imply fault tolerance: analysis of distributed storage reactions to single errors and corruptions Ganesan et al., FAST 2017
It’s a tough life being the developer of a distributed datastore. Thanks to the wonderful work of Kyle Kingsbury (aka, @aphyr) and his efforts on Jepsen.io, awareness of data loss and related issues in the face of network delays and partitions is way higher than it used to be. Under the Jepsen tests, every single system tested other than ZooKeeper exhibited problems of some kind. But many teams are stepping up, commissioning tests, and generally working hard to fix the issues even if they’re not all there yet.
So I’m sure they’ll all be delighted to know that there’s a new horror in town. Network partitions aren’t the only kind of nasty that distributed datastores can be subjected too. File system / storage devices can exhibit corruptions and errors. And just like network partitions, these aren’t as rare as the designers of datastores would like to have you believe. So what happens if you take eight popular distributed stores, and subject them not to a file-system related stress test, but just to one single itsy-bitsy local filesystem fault? Carnage!
The most important overarching lesson from our study is this: a single file-system fault can induce catastrophic outcomes in most modern distributed storage systems. Despite the presence of checksums, redundancy, and other resiliency methods prevalent in distributed storage, a single untimely file-system fault can lead to data loss, corruption, unavailability, and, in some cases, the spread of corruption to other intact replicas.
And this time around, not even ZooKeeper escaped unscathed.
File system faults
File systems can encounter faults for a variety of underlying causes including media errors, mechanical and electrical problems in the disk, bugs in firmware, and problems in the bus controller. Sometimes, corruptions can arise due to software bugs in other parts of the operating system, device drivers, and sometimes even due to bugs in file systems themselves. Due to these reasons, two problems arise for file systems: block errors, where certain blocks are inaccessible (also called latent sector errors) and block corruptions, where certain blocks do not contain the expected data.
A study of 1 million disk drives over a period of 32 months showed that 8.5% of near-line disks, and 1.9% of enterprise class disks developed one or more latent sector errors. Flash-based SSDs show similar error rates. Block corruptions (for example caused by bit-rot that goes undetected by the in-disk EEC) may corrupt blocks in ways not detectable by the disk itself. File systems in many cases silently return these corrupted blocks to applications. A study of 1.53 million drives over 41 months showed more than 400,000 blocks with checksum mismatches. Anecdotal evidence has also shown the prevalence of storage errors and corruptions (see e.g. ‘Data corruption is worse than you know‘).
Given the frequency of storage corruptions and errors, there is a non-negligible probability for file systems to encounter such faults.

In many cases file systems simply pass faults (errors or corrupted data) onto applications as-is, in a few other cases the file system may transform the fault into a different one. In either case, throughout the paper these are referred to as file-system faults.
Given that local file systems can return corrupted data or errors, the responsibility of data integrity and proper error handling falls to applications, as they care about safely storing and managing critical user data…. The behaviour of modern distributed storage systems in response to file-system faults is critical and strongly affects cloud-based services.
Errfs – the test harness that strikes fear in the heart of distributed storage systems
CORDS is a fault-injection system consisting of errfs, a FUSE file system, and errbench, a set of workloads and a behaviour inference script for each system under test.
Once a system has been initialized to a known state, the application (distributed datastore) is configure to run on top of errfs by specifying its mount point as the data-directory of the application. All reads and writes then flow through errfs, which can inject faults. Errfs can inject two different types of corruptions (zeros or junk) and three different types of errors (EIO on reads, EIO on writes, and ENOSPC/EDQUOT on writes that require additional space. These
The fault injection is about as kind as it’s possible to be:
… our model considers injecting example a single fault to a single file-system block in a single node at a time. While correlated file-system faults are interesting, we focus on the most basic case of injecting a single fault in a single node because our fault model intends to give maximum recovery leeway for applications.
Is errfs realistic?
All the bugs that we find can occur on XFS and all ext file systems including ext4, the default Linux file system. Given that these file systems are commonly used as local file systems in replicas of large distributed storage deployments and recommended by developers, our findings have important implications for such real-world deployments.
Given the single fault, the authors test for the following expected behaviours:
- committed data should not be lost
- queries should not silently return corrupted data
- the cluster should be available for reads and writes
- queries should not fail after retries
Using CORDS, the authors tested Redis, ZooKeeper, Cassandra, Kafka, RethinkDB, MongoDB, LogCabin, and CockroachDB. All systems were configured with a cluster of three nodes, and a replication factor of 3.
OK, so this isn’t good….
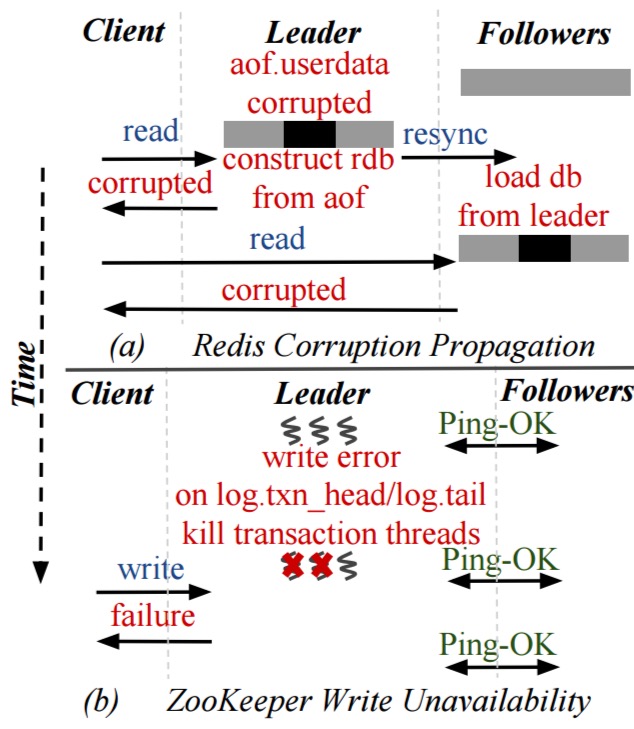
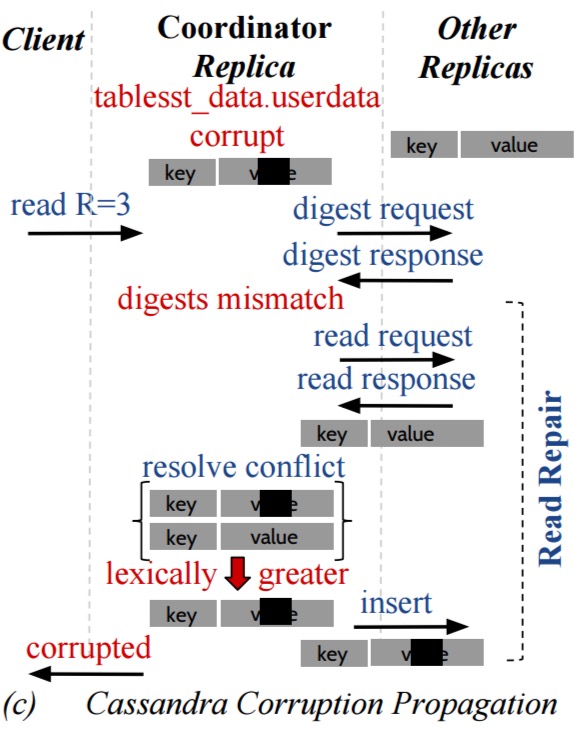
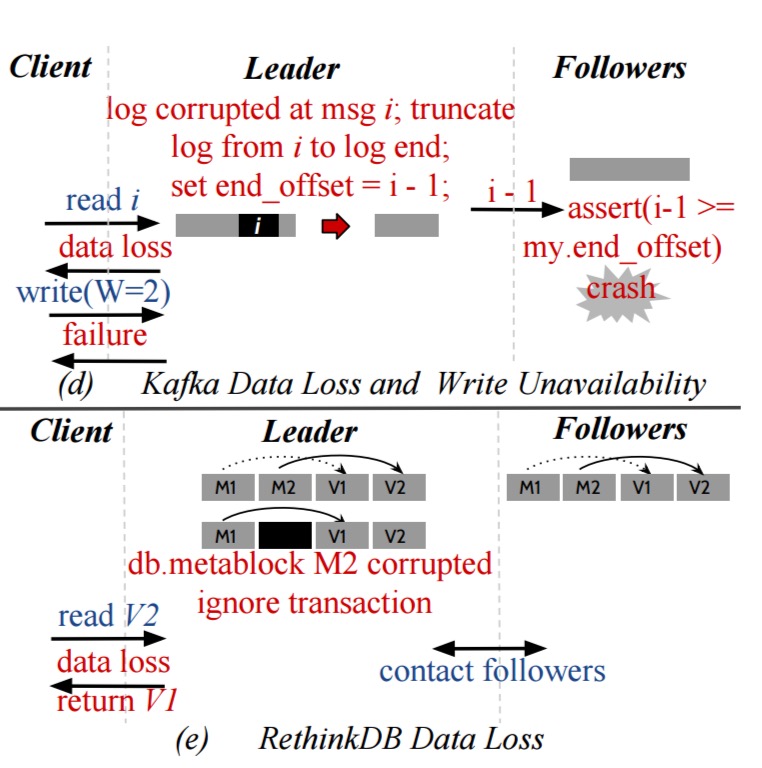
We find that these systems can silently return corrupted data to users, lose data, propagate corrupted data to intact replicas become unavailable, or return an unexpected error on queries. For example, a single write error during log initialization can cause write unavailability in ZooKeeper. Similarly, corrupted data in one node in Redis and Cassandra can be propagated to other intact replicas. In Kafka and RethinkDB, corruption in one node can cause a user-visible data loss.
Section 4 of the paper contains a system-by-system breakdown of the problems that the testing uncovered. The results are summarised in this monster table, but you’ll be better off reading the detailed description for any particular system of interest.

Here are some examples of problems found.
- Corruption propagation in Redis, and write unavailability in ZooKeeper:
- Corruption propagation in Cassandra:
- Data loss in Kafka and RethinkDB
Five key observations
Taking a step back from the individual system problems the authors present a series of five observations with respect to data integrity and error handling across all eight systems.
- Even though the systems employ diverse data integrity strategies, all of them exhibit undesired behaviours.
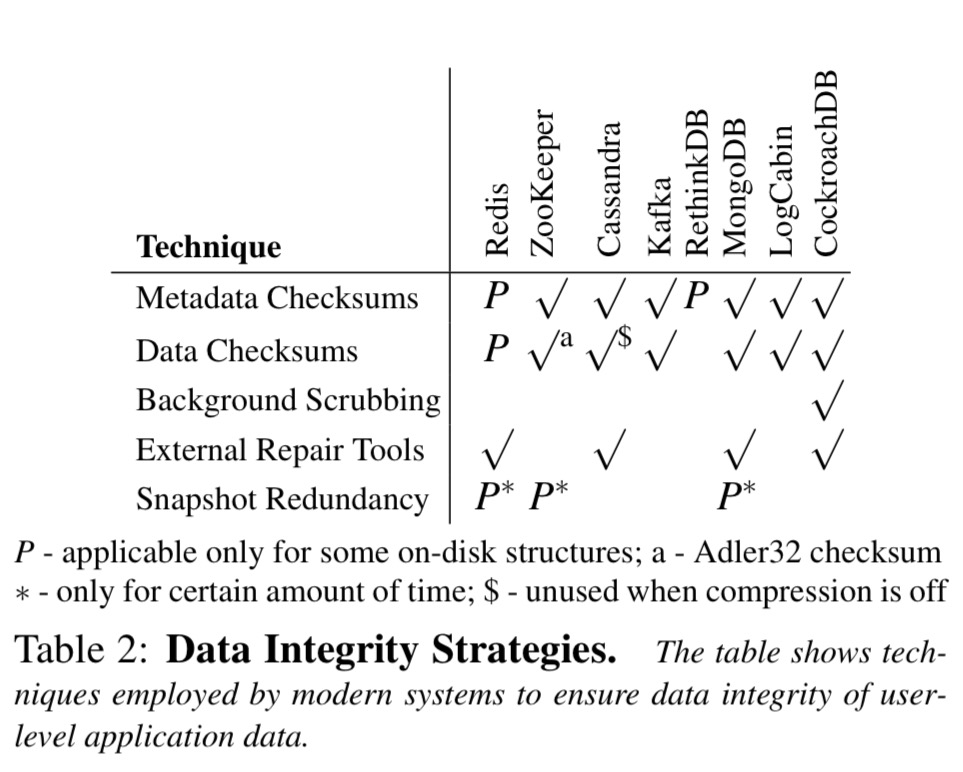
Sometimes, seemingly unrelated configuration settings affect data integrity. For example, in Cassandra, checksums are verified only as a side effect of enabling compression. Due to this behavior, corruptions are not detected or fixed when compression is turned off, leading to user-visible silent corruption. We also find that a few systems use inappropriate checksum algorithms. For example, ZooKeeper uses Adler32 which is suited only for error detection after decompression and can have collisions for very short strings.
- On the local node, faults are often undetected, and even if detected crashing is the most common local reaction. Sometimes this leads to an immediate harmful global effect. After crashing, simple restarting may not help if the fault is sticky – nodes repeatedly crash until manual intervention fixes the underlying problem.
For instance, in Redis, corruptions in the appendonly file of the leader are undetected, leading to global silent corruption… Likewise, RethinkDB does not detect corruptions in the transaction head on the leader which leads to a global user-visible data loss.
- Redundancy is under-utilised, and a single fault can have disastrous cluster-wide effects… Even if only a small amount of data becomes lost or corrupted, an inordinate amount of data can be affected.
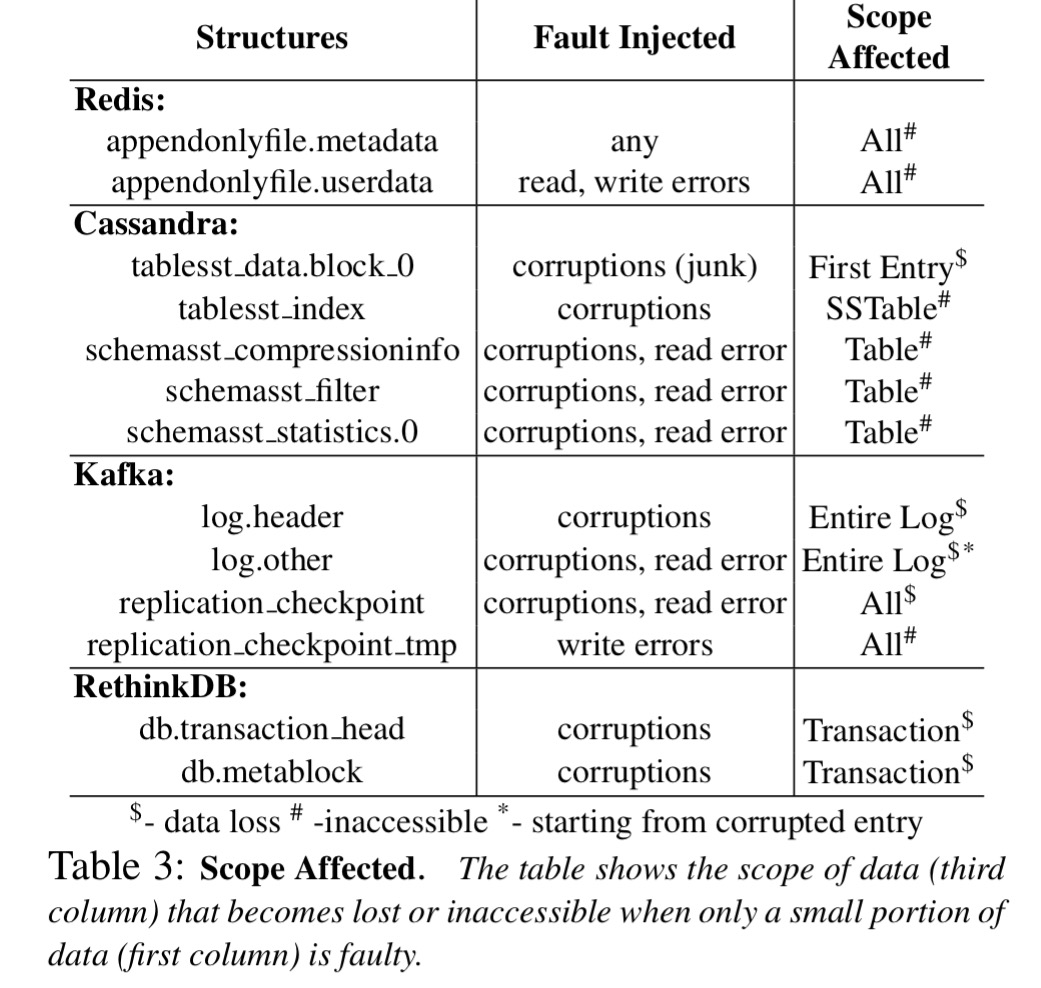
Contrary to the widespread expectation that redundancy in distributed systems can help recover from single faults, we observe that even a single error or corruption can cause adverse cluster-wide problems such as total unavailability, silent corruption, and loss or inaccessibility of inordinate amount of data. Almost all systems in many cases do not use redundancy as a source of recovery and miss opportunities of using other intact replicas for recovering. Notice that all the bugs and undesirable behaviors that we discover in our study are due to injecting only a single fault in a single node at a time. Given that the data and functionality are replicated, ideally, none of the undesirable behaviors should manifest.
- Crash and corruption handling are entangled – the detection and recovery code of many systems does not distinguish between crashes and corruptions. (They should!)
- Nuances in commonly used distributed protocols can spread corruption or data loss… “we find that subtleties in the implementation of commonly used distributed protocol such as leader-election, read repair and resynchronization can propagate corruption or data loss.“
How can we improve the situation?
- “As more deployments move to the cloud where reliable storage hardware, firmware, and software might not be the reality, storage systems need to start employing end-to-end integrity strategies.“
- “…we believe that recovery code in distributed systems is not rigorously tested, contributing to undesirable behaviors. Although many systems employ checksums and other techniques, recovery code that exercises such machinery is not carefully tested. We advocate future distributed systems need to rigorously test failure recovery code using fault injection frameworks such as ours.“
- The body of research work on enterprise storage systems provides guidance on how to tackle partial faults, “such wisdom has not filtered down to commodity distributed storage systems.” (and it needs to!)
- We’re going to need a fairly fundamental redesign in some cases:
…although redundancy is effectively used to provide improved availability, it remains underutilized as a source of recovery from file-system and other partial faults. To effectively use redundancy, first, the on-disk data structures have to be carefully designed so that corrupted or inaccessible parts of data can be identified. Next, corruption recovery has to be decoupled from crash recovery to fix only the corrupted or inaccessible portions of data. Sometimes, recovering the corrupted data might be impossible if the intact replicas are not reachable. In such cases, the outcome should be defined by design rather than left as an implementation detail.
Developers of all the systems under test were contacted regarding the problems uncovered by this testing. RethinkDB are changing their design to include application level checksums. The ZooKeeper write unavailability bug was also discovered in the wild and has recently been fixed.
Related to this paper, anyone building systems that interact with a file system API should also read “All file systems are not created equal.”

hi, sir
i just wonder if i can translate your blog into chinese and put it into my blog . also will mark the resouce came from you website. my email address: tomzhagmingfeng@gmail.com
You would be more than welcome to! Thanks, Adrian.
Thanks for the excellent write-up. wrt reading zeros/garbage – aren’t there filesystems that have blocks checksums, error correction codes, or something like that? Can running applications on top of safer file systems solve some of the problems? (I am aware it will not solve a problem with an application that doesn’t handle EIO in a sensible manner.)
You would be better go again through the paper. They still have checksum algorithms but the choices were not suitable. Bugs are still fired under some conditions where they most likely to happen in datacenters etc…