All File Systems are Not Created Equal: On the Complexity of Crafting Crash Consistent Applications – Pillai et al. 2014
Last week we looked at Reducing Crash Recoverability to Reachability for file system-based applications. Today’s choice predates that work and investigates the semantics of real world file systems and how this affects applications that run on top of them. It’s a real eye-opener, and essential reading if you’re building (or operating!) anything that you expect to be able to recover from crashes and that interacts with a file system. The bottom line: there are lots of vulnerabilities out there, and an application that works correctly with one file system may not do so with another one.
Many important applications, including databases such as SQLite and key-value stores such as LevelDB, are currently implemented on top of (these) file systems instead of directly on raw disks. Such data management applications must also be crash consistent, but achieving this goal atop modern file systems is challenging for two fundamental reasons…
- The guarantees provided by file systems are unclear and underspecified. While the POSIX standard specifies the effect of a system call in memory, specifications of how disk state is mutated in the event of a crash are widely misunderstood and debated. Each file system does it slightly differently, and each has a plethora of options that can modify its behaviour.
- In a quest for performance, most applications implement complex update protocols.
BOB, the Block Order Breaker, is used to find out what behaviours are exhibited by a number of modern file systems that are relevant to building crash consistent applications. ALICE, the Application Level Intelligent Crash Explorer is then used to explore the crash recovery behaviour of a number of applications on top of these file systems.
We use ALICE to study and analyze the update protocols of eleven important applications: LevelDB, GDBM, LMDB, SQLite, PostgreSQL, HSQLDB, Git, Mercurial, HDFS, ZooKeeper, and VMWare Player… Overall, we find that application-level consistency in these applications is highly sensitive to the specific persistence properties of the underlying file system. In general, if application correctness depends on a specific file system persistence property, we say the application contains a crash vulnerability; running the application on a different file system could result in incorrect behavior. We find a total of 60 vulnerabilities across the applications we studied; several vulnerabilities have severe consequences such as data loss or application unavailability. Using ALICE, we also show that many of these vulnerabilities (roughly half) manifest on current file systems such as Linux ext3, ext4, and btrfs.
Exploring File System Behaviours with BOB
BOB explores the persistence properties of modern file systems. In particular it examines atomicity – does the update arising from a system call happen all at once – and ordering – can system calls be reordered? Consider this program fragment:
write(f1,"pp")
write(f2,"qq")
All sorts of fun things might happen in the event of a crash. If the write operation is not atomic for example the file size could be updated but the content might not be written (file contains garbage), or just one “p” might be written into f1. Or if the calls are persisted out of order, f2 might contain “qq”, but f1 might not contain “pp”. Any combination of these is possible.
Ext2, ext3, ext4, xfs, btrfs, and reiserfs are studied with a variety of configurations (16 in total).
BOB collects the block I/O generated by the workload, and then re-orders the collected blocks, selectively writing some of them to disk to generate a new legal disk state (disk barriers are obeyed). In this manner, BOB generates a number of unique disk images corresponding to possible on-disk states after a system crash. BOB then runs file-system recovery on each resulting disk image, and checks whether various persistence properties hold (e.g., if writes were atomic).
BOB can find failures but can’t prove their absence. Here’s what BOB finds for the configurations under test – an x indicates that the property does not hold for the file system in question.
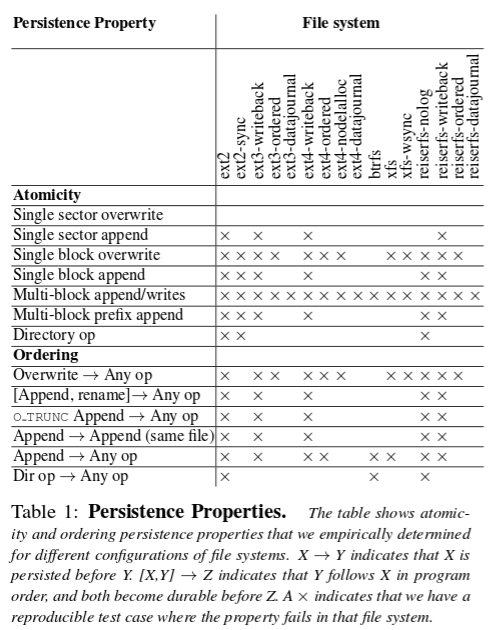
From Table 1, we observe that persistence properties vary widely among file systems, and even among different configurations of the same file system. The order of persistence of system calls depends upon small details like whether the calls are to the same file or whether the file was renamed. From the viewpoint of an application developer, it is risky to assume that any particular property will be supported by all file systems. (emphasis mine).
Exploring Application Level Behaviours with ALICE
ALICE finds the generic persistence properties required for an application to behave correctly . It does this by constructing file system states directly from the system call trace of an application workload.
The user first supplies ALICE with an initial snapshot of the files used by the application (typically an entire directory), and a workload script that exercises the application (such as performing a transaction). The user also supplies a checker script corresponding to the workload that verifies whether invariants of the workload are maintained (such as atomicity of the transaction). ALICE runs the checker atop different crash states, i.e., the state of files after rebooting from a system crash that can occur during the workload. ALICE produces a logical representation of the update protocol executed during the workload, vulnerabilities in the protocol and their associated source lines, and persistence properties required for correctness.
To capture intermediate crash states, ALICE breaks logical operations down into micro-operations – the smallest atomic operations that can be performed on each logical entity. These are: write block, change file size, create dir entry, delete dir entry, and adding messages to terminal output (stdout). An Application Persistence Model for a given run specifies atomicity constraints by defining how logical operations map into micro-operations.
ALICE selects different sets of the translated micro-ops that obey the ordering constraints. A new crash state is constructed by sequentially applying the micro-ops in a selected set to the initial state (represented as logical entities). For each crash state, ALICE then converts the logical entities back into actual files, and supplies them to the checker. The user-supplied checker thus verifies the crash state.
What ALICE revealed
34 different configuration options were tested across the 11 applications listed earlier.
ALICE finds 60 static vulnerabilities in total, corresponding to 156 dynamic vulnerabilities. Altogether, applications failed in more than 4000 crash states. Table 3(a)shows the vulnerabilities classified by the affected persistence property, and 3(b) shows the vulnerabilities classified by failure consequence. Table 3(b) also separates out those vulnerabilities related only to user expectations and not to documented guarantees, with an asterik (many of these correspond to applications for which we could not find any documentation of guarantees.

We find many vulnerabilities have severe consequences such as silent errors or data loss. Seven applications are affected by data loss, while two (both LevelDB versions and HSQLDB) are affected by silent errors. The cannot open failures include failure to start the server in HDFS and ZooKeeper, while the failed reads and writes include basic commands (e.g., git-log, git-commit) failing in Git and Mercurial. A few cannot open failures and failed reads and writes might be solvable by application experts, but we believe lay users would have difficulty recovering from such failures (our checkers invoke standard recovery techniques).
Four applications require atomicity across system calls, and three require appends to be content-atomic: the appended portion should contain actual data. LMDB, PostgreSQL and ZooKeeper require small writes ( Applications are extremely vulnerable to system calls being persisted out of order; we find 27 vulnerabilities.
A common heuristic to prevent data loss on file systems with delayed allocation is to persist all data of a file before subsequently renaming – the bad news is that this tactic only fixes a small minority (3) of vulnerabilities.
The vulnerabilities exposed vary based on the file system, and thus testing applications on only a few file systems does not work.

Well, poop. I wonder if jfs is any better.