Using Crash Hoare Logic for Certifying the FSCQ File System – Chen et. al 2015
If you found yesterday’s look at POSIX file system semantics and the crash recovery of applications built on top a little sobering, then today’s paper offers a glimpse of a light at the end of the tunnel. Chen et al. define an extension to Hoare logic which they call Crash Hoare Logic. As the name suggests, this adds support for crash states and recovery to traditional Hoare logic. They integrate support for Crash Hoare Logic (CHL) into Coq to support proof automation. Using CHL they build a model for asynchronous disk writes, specify a write-ahead log, and on top of the write-ahead log build a fully verified specification of a crash recoverable file system: FSCQ. Using Coq, they extract a Haskell implementation of FSCQ and show that it works well with a range of applications. Oh, and they also throw in a specification of a subset of the POSIX file system API that captures its semantics under crashes. All in, this is a very impressive piece of work!
You can find the FSCQ implementation in GitHub at https://github.com/mit-pdos/fscq-impl.
Crash Hoare Logic
Our goal is to allow developers to certify the correctness of a storage system formally—that is, to prove that it functions correctly during normal operation and that it recovers properly from any possible crashes… To prove that an implementation meets its specification, we must have a way for the developer to state what correct behavior is under crashes. To do so, we extend Hoare logic, where specifications are of the form {P} procedure {Q}. Here, procedure could be a sequence of disk operations (e.g., read and write), interspersed with computation, that manipulates the persistent state on disk, such as the implementation of the rename system call or a lower-level operation such as allocating a disk block.
Given
{P}
procedure
{Q}
Then given that the precondition P holds before executing the procedure, we must prove that the post-condition Q holds after executing the procedure. Hoare logic is insufficient as is to deal with crashes and recovery, since it lacks any notion that ‘procedure’ may not be atomic and may fail part way through.
CHL extends Hoare logic with crash conditions, logical address spaces, and recovery execution semantics. These three extensions together allow developers to write concise specifications for storage systems, including specifying the correct behavior in the presence of crashes.
The simplest of the three extensions is the addition of crash conditions. Consider the specification for a disk_write of a value v at address a:
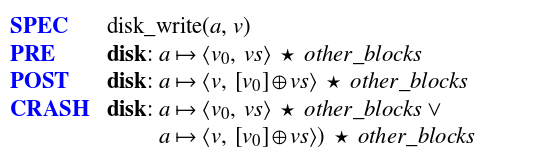
Note that in addition to the normal PRE and POST conditions, we also have a CRASH condition. The crash condition specifies the possible states the system could be in at the time of a crash. (The ∗ operator in the above example is using separation logic to enable us to say that the rest of the disk blocks remain unchanged).
One subtlety of CHL’s crash conditions is that they describe the state of the disk just before the crash occurs, rather than just after. Right after a crash, CHL’s disk model specifies that each block nondeterministically chooses one value from the set of possible values before the crash. For instance, the first line of (the) crash condition says that the disk still “contains” all previous writes, represented by ⟨v0, vs⟩, rather than a specific value that persisted across the crash, chosen out of [v0] ⊕ vs. This choice of representing the state before the crash rather than after the crash allows the crash condition to be similar to the pre- and postconditions.
In CHL, developers must write crash conditions for every procedure. “In practice, we have found that the crash conditions are often simpler to state than the pre- and postconditions. For example, in FSCQ, most crash conditions in layers above the log simply state that there is an active (uncommitted) transaction; only the top-level system call code begins and commits transactions.”
Given crash conditions, how can we reason about recovery (including crashes during recovery)?
In contrast to CHL’s regular execution semantics, which talks about a procedure producing either a failure (accessing an invalid disk block), a crash, or a finished state, the recovery semantics talks about procedures executing (a normal procedure and a recovery procedure) and producing either a failure, a completed state(after finishing the normal procedure), or a recovered state(after finishing the recovery procedure). This regime models the notion that the normal procedure tries to execute and reach a completed state, but if the system crashes, it starts running the recovery procedure (perhaps multiple times if there are crashes during recovery), which produces a recovered state.
The >> operator is used to combine a regular procedure with a recovery procedure. Distinguishing normal completion and recovered states enables us to specify stronger post-conditions for normal completion.

There’s one important feature to note in the specification of the log recover procedure below: the crash condition implies the pre-condition, this is what enables log recover to crash and restart multiple times.

Proving the correctness of the top-level procedure p entails proving that, if p is executed and the precondition held before p started running, either 1) its postcondition holds; or 2) the recovery condition holds after recovery finishes. For the first case, we must show that the precondition of the top-level procedure implies the precondition of the first procedure invoked, that the postcondition of the first procedure called implies the precondition of the next procedure invoked in the control flow, and so on. Similarly for the second case, we must prove that the crash condition of each procedure implies the precondition of the recovery procedure, and so on.
This chaining of proofs is easy to automate. In the CHL implementation in Coq, if the pre-condition of a procedure is trivially implied by a preceding post-condition then the developer does not have to prove anything. In more complex cases, CHL relies on separation logic to prove obligations and carry information from pre-condition to post-condition.
Some implication obligations cannot be proven by CHL automatically and require developer input. This usually occurs when the developer is working with multiple levels of abstraction, where one predicate mentions a higher-level representation invariant (e.g., a directory represented by a function from file names to inode numbers) but the other predicate talks about lower-level state (e.g., a directory represented by a set of directory entries in a file).
FSCQ
FSCQ provides a POSIX-like interface at the top level; the main differences from POSIX are (i) that FSCQ does not support hard links, and (ii) that FSCQ does not implement file descriptors and instead requires naming open files by inode number… We decided to specify all-or-nothing atomicity with respect to crashes and immediate durability (i.e., when a system call returns, its effects are on disk). In future work, we would like to allow applications to defer durability by specifying and supporting system calls such a fsync.
At the core of FSCQ is FSCQLog, a write-ahead log specified in CHL.
By using FscqLog, FSCQ can factor out crash recovery. FSCQ updates the disk only through those writes into transactions at the system-call granularity to achieve crash safety. For example, FSCQ wraps each system call like open, unlink, etc, in an FscqLog transaction… This allows us to prove that the entire system call is atomic. That is, we can prove that the modifications a system call makes to the disk (e.g., allocating a block to grow a file, then writing that block, and so on) all happen or none happen, even if the system call fails due to a crash after issuing some log_writes.
FSCQLog must deal with the complexity of asynchronous writes, but it presents a simpler synchronous interface to higher levels.
Since transactions take care of crashes, the remaining challenge lies in specifying the behavior of a file system and proving that the implementation meets its specification on a reliable disk…
The authors built and proved correct a common allocator for disk blocks and inodes, and a library for packing and unpacking data structures into bit-level representations.
FSCQ and CHL are implemented using Coq, which provides a single programming language for implementation, stating specifications, and proving them… The development effort took several researchers about a year and a half; most of it was spent on proofs and specifications. Checking the proofs takes 11 hours on an Intel i7-3667U 2.00 GHz CPU with 8 GB DRAM. The proofs are complete; we used Coq’s Print Assumptions command to verify that FSCQ did not introduce any unproven axioms or assumptions.
Running code was produced by using Coq’s extraction mechanism to generate equivalent Haskell code.
FSCQ is complete enough that we can use FSCQ for software development, running a mail server, etc. For example, we have used FSCQ with the GNU coreutils (ls, grep, etc.), editors(vim and emacs), software development tools (git, gcc, make, and so on), and running a qmail-like mail server. Applications that, for instance, use extended attributes or create very large files do not work on FSCQ, but there is no fundamental reason why they could not be made to work.
Reflections on a formal approach to building systems software
To understand whether FSCQ eliminates real problems thatarise in current file systems, we consider broad categories of bugs that have been found in real-world file systems and discuss whether FSCQ’s theorems eliminate similar bugs…
These categories are (1) violating file or directory invariants, (2) improper handling of unexpected corner cases, (3) mistakes in logging and recovery logic, (4) misusing the logging API, (5) low-level programming errors, (6) resource allocation bugs, (7) returning incorrect error codes, and (8) bugs due to concurrent execution of system calls.
Categories 1-5 are eliminated by FSCQ’s theorems and proofs. Incorrect error codes (6) can only occur where the specification does not say exactly which error code should be returned – the spec. could be extended to do this at the cost of more complex specs and proofs. Bugs due to concurrent execution of system calls (8) can’t occur since the FSCQ prototype does not support multi-threading. That just leaves (6): FSCQ will never lose resources, but the spec. doesn’t require the system to be out of resources to return an out-of-resource error. This class of bugs could be eliminated by strengthening the spec.
A (more) interesting question is how much effort is required to modify FSCQ, after an initial version has been developed and certified. Does adding a new feature to FSCQ require reproving everything, or is the work commensurate with the scale of the modifications required to support the new feature?
Several case studies show that incremental extension of FSCQ does indeed only require work commensurate with the scale of the modifications.
Although FSCQ is not as complete and high-performance as today’s high-end file systems, our results demonstrate that this is largely due to FSCQ’s simple design. Furthermore, the case studies indicate that one can improve FSCQ incrementally. In future work we hope to improve FSCQ’s logging to batch transactions and to log only metadata; we expect this will bring FSCQ’s performance closer to that of ext4’s logging. The one exception to incremental improvement is multiprocessor support, which may require global changes and is an interesting direction for future research.

“Categories 1-5 are eliminated by FSCQ’s theorems and proofs.” I presume that this holds under the assumption that there are no bugs in the microcode of the CPU and/or the drives.
For instance CPU’s themselves seem to lack formal proof, e.g. see: http://danluu.com/cpu-bugs/
Yes indeed, the full paper includes a discussion on assumptions about the underlying compute base – as well as reasons for optimism that we can build with formal verification from the ground up one day…