Uncovering bugs in Distributed Storage Systems during Testing (not in production!) – Deligiannis et al. 2016
We interviewed technical leaders and senior managers in Microsoft Azure regarding the top problems in distributed system development. The consensus was that one of the most critical problems today is how to improve testing coverage so that bugs can be uncovered during testing and not in production. The need for better testing techniques is not specific to Microsoft; other companies such as Amazon and Google, have acknowledged that testing methodologies have to improve to be able to reason about the correctness of increasingly more complex distributed systems that are used in production.
The AWS team used formal methods with TLA+, which was highly effective but falls short of checking the actual executable code. The Microsoft IronFleet team used the Dafny language and program verifier to verify system correctness and compile it to a .NET executable. Deligiannis et al. wanted to find a methodology that validated high-level specifications directly on executable code, and that did not require developers to switch to an unfamiliar language.
Our testing methodology is based on P#, an extension of C# that provides support for modeling, specification, and systematic testing of distributed systems written in the Microsoft .NET framework. To use P# for testing, the programmer has to augment the original system with three artifacts: a model of the nondeterministic execution environment of the system; a test harness that drives the system towards interesting behaviors; and safety or liveness specifications. P# then systematically exercises the test harness and validates program behaviors against the provided specifications.
Consider a distributed system with several different types of processes. In the running example in the paper, there are client processes, server processes, and storage node processes. Take the process that you want to test (e.g. the server process), and wrap it in a P# machine – the P# machine interposes on all messages sent and received by the process. For all other process types, build a P# machine model (mock) implementation. Connect the P# machine wrapped process to be tested and P# model processes together in the topology you wish to test.
Here’s an example of a modelled ‘NetworkEngine’ component in P#:

Optionally add a safety monitor P# machine and a liveness monitor P# machine to the deployment topology:
P# supports the usual assertions for specifying safety properties that are local to a P# machine, and also provides a way to specify global assertions by using a safety monitor, a special P# machine that can receive, but not send, events… An erroneous global behavior is flagged via an assertion on the private state of the safety monitor. Thus, a monitor cleanly separates instrumentation state required for a specification (inside the monitor) from program state (outside the monitor).
Liveness monitors contain two special types of state called hot and cold. A hot state represents a point in the execution where progress is required but has not happened yet. The liveness monitor enters the hot state when it is notified that the system must make progress, and returns to the cold state when it is told that the system has progressed. “Our liveness monitors can encode arbitrary temporal logic properties.”
The user specifies some upper-bound on execution time, and if the monitor is in a hot state when bounded execution terminates, a liveness violation is triggered.
Here’s an example P# test harness set-up for a server process, with modelled client and storage node processes and additional monitors:
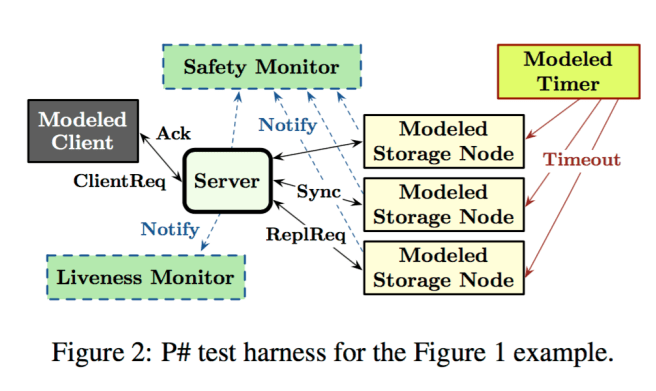
The test harness itself is also written by the developer in P#. It’s goal is to drive the system towards interesting behaviours by non-deterministically triggering various events.
Here’s a snippet of a testing driver for Microsoft Azure Storage, vNext:

With all these pieces in place…
… The P# testing engine will serialize (in a single-box) the system, and repeatedly execute it from start to completion, each time exploring a potentially different set of nondeterministic choices, until it either reaches the user-supplied bound, or it hits a safety or liveness property violation. This testing process is fully automatic and has no false-positives. After a bug is discovered, P# generates a trace that represents the buggy schedule, which can then be replayed to reproduce the bug. In contrast to logs typically generated during production, the P# trace provides a global order of all communication events, and thus is easier to debug.
By intercepting all network messages and dispatching them through P#, P# is able to systematically explore the interleavings between asynchronous event handlers in the system. Modelled components can also make use of P#’s support for controlled non-determinstic choices – for example, by choosing to drop messages in a non-deterministic fashion if emulating message loss is desirable.
This leaves me with two key questions: what about the state-space explosion – i.e. how can the system effectively cover all of the possible combinations?; and what about minimising a schedule down to just that needed to reproduce the bug? I note in the evaluation that four known bugs were not caught by the test harness in the allowed 100,000 executions. “We believe this is because the inputs and schedules that trigger them are too rare in the used distribution.” (See Lineage Driven Fault Injection for another way of approaching this problem).
The authors claim the state-space problem is somewhat mitigated by the use of modelled components. They don’t say anything in this paper about failing test minimisation.
P# testing harnesses and models were built for three different systems at Microsoft: Microsoft Azure Storage vNext, Microsoft Azure Live Table Migration (which transparently migrates a k-v data set between two Microsoft Azure tables), and Microsoft Azure Service Fabric. The total time taken to model these systems ranged from two person weeks (Storage vNext) to five person months (Service Fabric). P# uncovered 8 serious bugs in these systems.
… these bugs were hard to find with traditional testing techniques, but P# managed to uncover and reproduce them in a small setting.
Table 2, reproduced below, summarises the bugs that were found (using a random scheduler, and a randomized-priority scheduler – both variations on randomly choosing which P# machine to execute next at each scheduling point), and the time taken to find them.
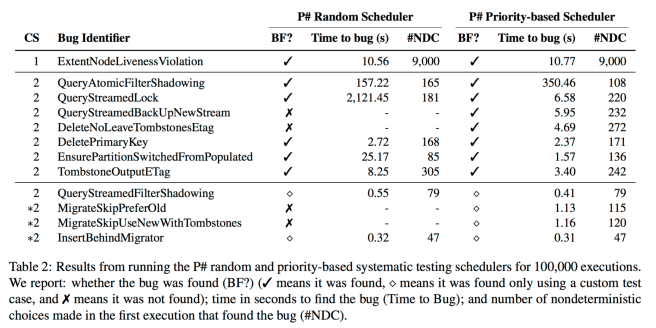
Despite the extensive [traditional] testing efforts, the vNext developers were plagued for months by an elusive bug in the ExtMgr logic. All the unit test suites and integration test suites successfully passed on each test run. However, the stress test suite failed from time to time after very long executions; in these cases, certain replicas of some extents failed without subsequently being repaired… It took less than ten seconds for the P# testing engine to report the first occurence of a liveness bug in vNext. Upon examining the debug trace, the developers of vNext were quickly able to confirm the bug.
“In principle, our methodology is not specific to P# and the .NET framework, and can be used in combination with any other programming framework that has equivalent capabilities.”

Reblogged this on slash dev slash null.
Jespen is a project that distraction tests distributed systems https://github.com/aphyr/jepsen
The theory of its verifier is blogged about here https://aphyr.com/posts/314-computational-techniques-in-knossos
That blog series documents a large number of bugs that it has found in opensource databases.
https://github.com/clojure/test.check does some form of “failed test minimization”, they call it “shrinking”