CYCLADES: Conflict-free asynchronous machine learning Pan et al. NIPS 2016
“Conflict-free,” the magic words that mean we can process things concurrently or in parallel at full speed, with no need for coordination. Today’s paper introduces Cyclades, a system for speeding up machine learning on a single NUMA node. In the evaluation, the authors used NUMA nodes with 18 CPUs and 1TB memory. Extending Cyclades to work across NUMA nodes, or even in a distributed setting using a parameter server is reserved for future investigation.
The overall hierarchy of ML speed and scale probably looks something like this:
- Clusters of GPUs [w. CPU support] – Speed and Scale
- Multi-GPUs on a single node [w. CPU support] for SPEED, Clusters of CPUs for SCALE
- Multi-core CPUs on a single node
- Single core (thread) systems
Remember not to underestimate what can be achieved on a single thread. Because of their accessibility and ease of programming, systems that work on a single box can have great utility. Cyclades efficiently utilises multiple cores through a graph partitioning step that allocates connected-component subgraphs to cores, eliminating the need for cross-core coordination. One of the compelling things that is unique about Cyclades is that unlike other systems we’ve seen (Asynchronous Complex Analytics, Petuum) that use asynchronous processing to speed up ML, Cyclades maintains serial equivalence. That is, it guarantees to give the same results as a serial implementation. Without serial equivalence, other systems rely on analyses that the deviation from serial is not significant (stays within some bound).
Since it returns exactly the same output as a serial implementation, any algorithm parallelized by our framework inherits the correctness proof of the serial counterpart without modifications. Additionally, if a particular heuristic serial algorithm is popular, but does not have a rigorous analysis, such as backpropagation on neural networks, Cyclades still guarantees that its execution will return a serially equivalent output.
Cyclades works for a large family of algorithms based on stochastic updates. This includes logistic regression, least squares, support vector machines, word embeddings, stochastic gradient descent, matrix completion and factorization, and more.
At the core of Cyclades is a clever partitioning strategy. Consider a graph with two types of vertices (bipartite), update functions and model variables. We create an edge from an update function to a variable if that function reads or writes it.
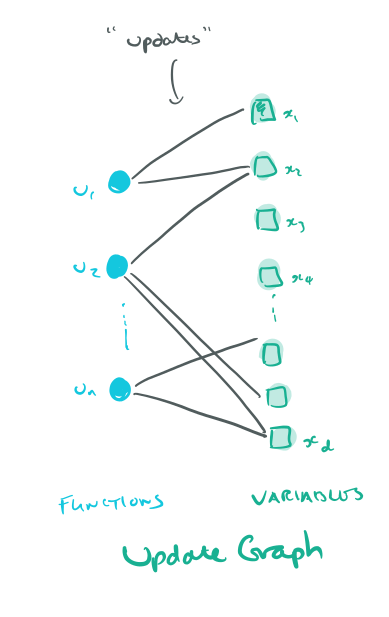
From this we can create a conflict graph (Cyclades never actually fully materializes such a graph, but it’s a useful conception). The conflict graph contains only update function vertices, and links two vertices with an edge if they share at least one variable in the update graph.
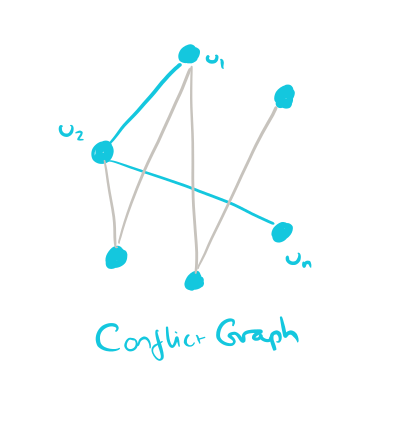
The key now is to partition the conflict graph into connected components, and allocate those connected components to cores.

This relies on a result established in a 2016 Electronic Journal of Combinatorics paper, “The phase transition in site percolation on pseudo-random graphs,” by Krivelevich. No, I’m not brave enough to try and cover a Journal of Combinatorics paper on this blog! The result is as follows:
Let G be a graph on n vertices, with maximum vertex degree Δ. Let us sample each vertex independently with probability p = (1 – &eps;)/&Delta and define as G’ the induced subgraph on the sampled vertices. Then, the largest connected component of G’ has size at most (4/&esp;2) log n, with high probability.
This is pithily summarized by the authors as ‘frugal sampling shatters conflicts.’ It tells us that by careful sampling of the vertices in the conflict graph, we can induce a subgraph with at least O(log n / &eps;2) components to distribute across cores.
(There’s something of importance in the ‘induced subgraph’ phrase that I feel I don’t fully understand. Because what really matters surely is the size of the largest connected component in G (not G’)? (We do the actual computation on G, right?). My interpretation is that by sampling we can create a subgraph G’ from which we can infer connected components that with high probability match the connected components of G (and have certain maximum size)… But then why would the number of components depend on our sampling frequency?? The results indicate that the process clearly works, so we can press on, but if anyone can put me straight here I’d appreciate it!).
Moreover, since there are no conflicts between different conflict-groups, the processing of updates per any single group will never interact with the variables corresponding to the updates of another conflict group.
Cyclades samples in batches of size B = (1-&eps;)n/Δ, and identifies conflict groups for each batch using a connected components algorithm. The appendix shows that this can be done efficiently in time O(num_edges . log2n / P) where P is the number of processor cores available.
We can put all the pieces together for the complete Cyclades algorithm:

The inner loop is parallelized and can be performed asynchronously with no need for memory locks as all the cores access non-overlapping subsets of the input x. This gives good cache coherence, and as each core potentially access the same coordinates multiple times, good cache locality.
Observe that Cyclades bypasses the need to establish convergence guarantees for the parallel algorithm.
And we have the main theorem:
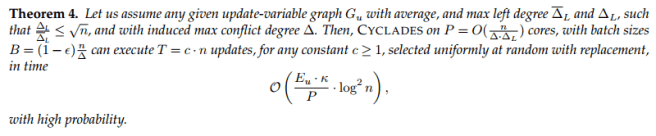
Does it work in practice?
The authors implemented Cyclades in C++ and tested it against HogWild! on equivalent number of cores, and also against a single threaded implementation .
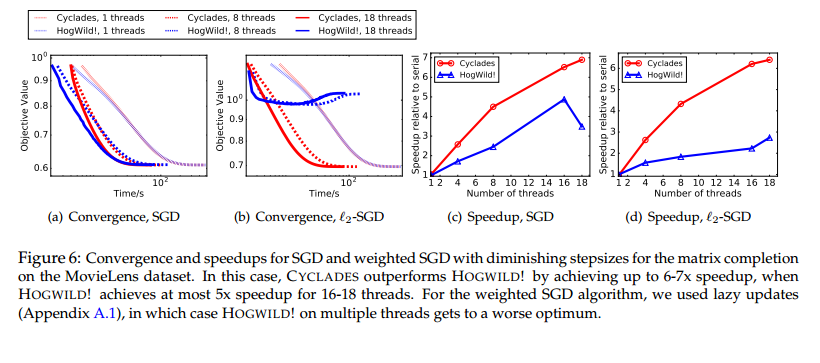
Cyclades is initially slower but converges faster:

It achieves a relative speed-up of up to 5x over HogWild! when both systems are given the same number of cores.
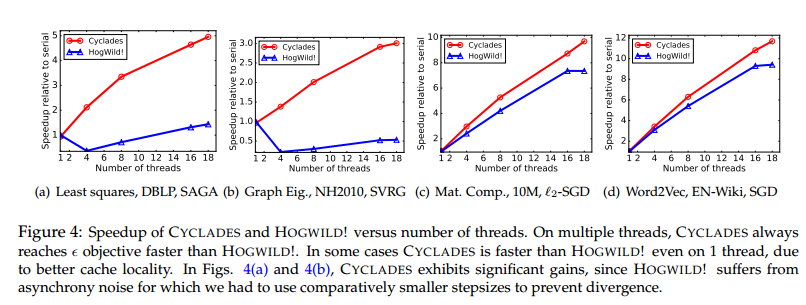
When we decrease the step-size after each epoch, Cyclades shows even stronger relative performance:
It would be interesting to see where else the Krivelevich connected component result can be applied, it seems that many graph computations could potentially benefit.

‘Induced subgraph’ only includes edges that exist between vertices in the sample, not edges that go outside the sampled vertex set. For frugal sampling, there will probably be many small connected components within each connected component of the original graph.
“My interpretation is that by sampling we can create a subgraph G’ from which we can infer connected components that with high probability match the connected components of G…”
I don’t think that’s what’s going on here – for instance, in the example in Figure 2 (that shows the “shattering”), there’s only one connected component. So not only are the connected components of the subsample-induced G’ a poor approximation to the connected components of G, there’d be no way to perform the calculation if it had to be performed without conflicts. (The same is true of any of the subgraphs).
I think what’s going on here is that the serial case would perform the (conflicting) updates in some arbitrary order, based just on the order the loop hits the items, and any of those “serializable” orders would be perfectly legitimate – you just want to avoid race conditions where one task is updating a value while another is writing it. So take the SGD update in appendix A, and the gradient of f(x). You don’t want to update x_k using a gradient that has some updated values and some old values. There’s a number of orderings of k which would give a good answer, but even more which wouldn’t.
There are deterministic algorithms for decomposing the problem into non-overlapping subproblems, performing those in parallel, and then doing any remaining steps; those work but are quite expensive (and aren’t in general always going to give you an optimal decomposition anyway).
This seems to me to be a very cute and simple way (with a surprisingly deep reason why it works well) to stochastically generate and distribute such (over-)decompositions efficiently which performs well in theory and in practice for an interestingly broad range of problems. Because of its simplicity and its effectiveness, I expect that it will see a significant amount of adoption…