GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server – Cui et al. 2016
We know that deep learning is well suited to GPUs since it has inherent parallelism. But so far this has mostly been limited to either a single GPU (e.g. using Caffe) or to specially built distributed systems such as Deep Image – a custom-built supercomputer for deep learning via GPUs. Distributed deep learning systems are typically CPU-based. Clearly the ideal would be to efficiently harness clusters of GPUs in a general-purpose framework. This is exactly what GeePS does, and the results are impressive. For example, GeePS achieves a higher training throughput with just four GPU machines than a state-of-the-art CPU-only system achieves with 108 machines! To achieve this, GeePS needs to overcome the challenges of limited GPU memory, and inter-machine communication.
Experiments show that single-GPU codes can be easily modified to run with GeePS and obtain good scalable performance across multiple GPUs. For example, by modifying Caffe, a state-of-the-art open-source system for deep learning on a single GPU, to store its data in GeePS, we can improve Caffe’s training throughput (images per second) by 13x using 16 machines. Using GeePS, less than 8% of the GPU’s time is lost to stalls (e.g. for communication, synchronization, and data movement), as compared to 65% when using an efficient CPU-based parameter server implementation.
GeePS is a parameter server supporting data-parallel model training. In data parallel training, the input data is partitioned among workers on different machines, that collectively update shared model parameters. These parameters themselves may be sharded across machines. “This avoids the excessive communication delays that would arise in model-parallel approaches, in which the model parameters are partitioned among the workers on different machines.”
That covers the data-parallel part, but what does it mean to be a parameter server?
Using parameter servers to scale machine learning
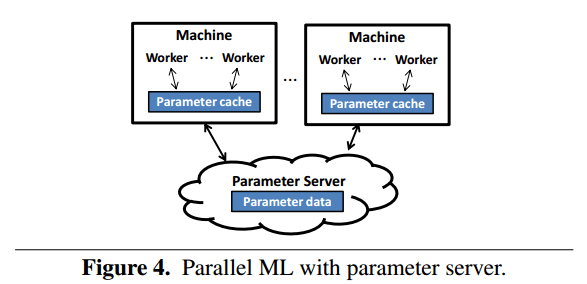
[In] the basic parameter server architecture, all state shared among application workers (i.e. the model parameters being learned) is kept in distributed shared memory implemented as a specialized key-value stare called a “parameter server”. An ML application’s workers process their assigned input data and use simple Read and Update methods to fetch or apply a delta to parameter values, leaving the communication and consistency issues to the parameter server.
Client-side caches are also used to serve most operations locally. Many systems include a Clock method to identify a point when a worker’s cached updates should be pushed back to the shared key-value store and its local cache state should be refreshed.
The consistency model can conform to the Bulk Synchronous Parallel (BSP) model, in which all updates from the previous clock must be visible before proceeding to the next clock, or can use a looser but still bounded model. For example, the Stale Synchronous Parallel model allows the fastest worker to be ahead of the slowest worker by a bounded number of clocks.
While logically the parameter server is separate to the worker machines, in practice the server-side parameter server state is commonly sharded across the same machines as the worker state. This is especially important for GPU-based ML execution, since the CPU cores on the worker machines are otherwise underused.
The authors tried using an existing state-of-the-art parameter server system (IterStore) with GPU based ML….
Doing so was straightforward and immediately enabled distributed deep learning on GPUs, confirming the application programmability benefits of the data-parallel parameter server approach… While it was easy to get working, the performance was not acceptable. As noted by Chilimbi et al., the GPUs computing structure makes it “extremely difficult to support data parallelism via a parameter server” using current implementations because of GPU stalls, insufficient synchronization/consistency, or both. Also, as noted by them and others, the need to fit the full model, as well as a mini-batch of input data and intermediate neural network states, in the GPU memory limits the size of models that can be trained.
Specializing a parameter server for GPUs
To enable a parameter server to support parallel ML applications running on distributed GPUs the authors make three important changes:
- Explicit use of GPU memory for the parameter cache
- Batch-based parameter access methods
- Parameter server management of GPU memory on behalf of the application
“The first two address performance, and the third expands the range of problem sizes that can be addressed with data-parallel execution on GPUs.”
Using GPU memory
Keeping the parameter cache (primarily) in the GPU memory is not about reducing data movement between CPU and GPU memory, rather it enables the parameter server client library to perform these data movement steps in the background, overlapping them with GPU computing activity.
Putting the parameter cache in GPU memory also enables updating of the parameter cache state using GPU parallelism.
Batching operations
One at a time read and update operations of model parameters values can significantly slow execution.
To realize sufficient performance, our GPU-specialized parameter server supports batch-based interfaces for reads and updates. Moreover, GeePS exploits the iterative nature of model training to provide batch-wide optimizations, such as pre-built indexes for an entire batch that enable GPU-efficient parallel “gathering” and updating of the set of parameters accessed in a batch. These changes make parameter server accesses much more efficient for GPU-based training.
GeePS implements an operation sequence gathering mechanism that gathers the operation sequence either in the first iteration, or in a virtual iteration. Before real training starts, the application performs a virtual iteration with all GeePS calls being marked with a virtual flag. Operations are recorded by GeePS but no real actions are taken.
GeePS uses the gathered operation sequence knowledge as a hint to build the data structures, build the access indices, make GPU/CPU data placement decisions, and perform prefetching. Since the gathered access information is used only as a hint, knowing the exact operation sequence is not a requirement for correctness, but a performance optimization.
Managing GPU memory
The parameter server uses pre-allocated GPU buffers to pass data to an application, rather than copying the parameter data to application provided buffers. When an application wants to update parameter values, it also does so in GPU allocated buffers. The application can also store local non-parameter data (e.g intermediate states) in the parameter server.
The parameter server client library will be able to manage all the GPU memory on a machine, if the application keeps all its local data in the parameter server and uses the parameter-server managed buffers. When the GPU memory of a machine is not big enough to host all data, the parameter server will store parts of the data in CPU memory.
The application still accesses everything through the GPU memory buffers, and the parameter server itself manages the movement of data between CPU and GPU.
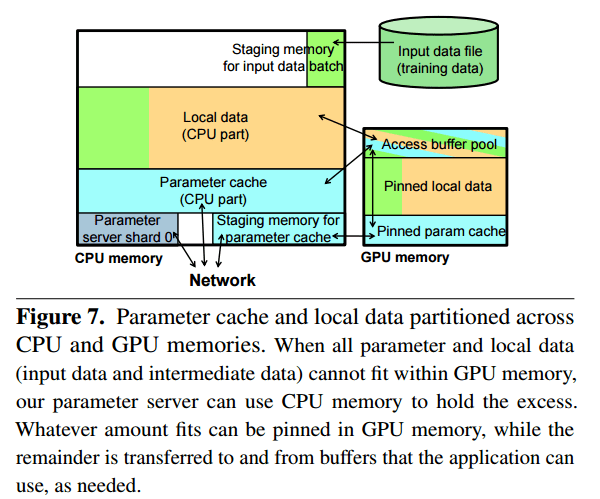
Fortunately, iterative applications like neural network training typically apply the same parameter data accesses every iteration, so the parameter server can easily predict the Read operations and perform them in advance in the background.
Implementation Notes
GeePS is a C++ library. The ML application worker often runs in a single CPU thread that launches NVIDIA library calls or customized CUDA kernels to perform computations on GPUs, and it calls GeePS functions to access and release GeePS-managed data. The parameter data is sharded across all instances, and cached locally with periodic refresh (e.g. every clock for BSP). GeePS supports BSP, asynchrony, and the Staleness Synchronous Parallel (SSP) model.
When an application issues a read or update operation it provides a list of keys. All parameters are fetched or updated in parallel on the GPU cores. The access index built from the list of keys can be built just once for each batch of keys using the operation sequence gathering process described earlier, and then re-used for each instance of the given batch access.
The [GPU/CPU data placement] algorithm chooses the entries to pin in GPU memory based on the gathered access information and a given GPU memory budget. While keeping the access buffer pool twice the peak size for double buffering, our policy will first try to pin the local data that is used at the peak in GPU memory, on order to reduce the peak size and thus the size of the buffer pool. Then, it will try to use the available capacity to pin more local data and parameter cache date in GPU memory. Finally, it will add any remaining available GPU memory to the access buffer.
Figure 8 (below) shows the throughput scalability of GeePS on an image classification task as compared to a CPU-based parameter server distributed system, and a single GPU node Caffe system.
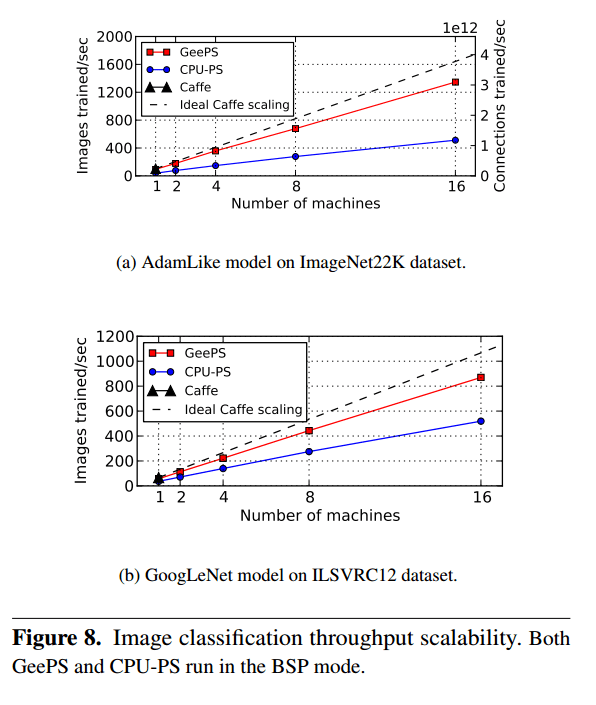
To evaluate convergence speed, we will compare the amount of time required to reach a given level of accuracy, which is a combination of image training throughput and model convergence per trained image. For the AdamLike model on the ImageNet22K dataset, Caffe needs 26.9 hours to reach 10% accuracy, while GeePS needs only 4.6 hours with 8 machines (6x speedup) or 3.3 hours with 16 machines (8x speedup).
GeePS’s support for large neural networks (by combining CPU and GPU memory) was tested with models requiring over 70GB of data in total. Using unmodified Caffe, a video classification RNN can support a maximum video length of 48 frames.
Ng et al. find that using more frames in a video improves the classification accuracy. In order to use a video length of 120 frames, Ng et al. used a model-parallel approach to split the model across four machines, which incurs extra network communication overhead. By contrast, with the memory management support of GeePS, we are able to train videos with up to 192 frames, using solely data parallelism.
BSP vs SSP vs Async
Previously on The Morning Paper we looked at Asynchronous Complex Analytics… and Petuum which found that relaxing synchronization constraints is important to achieving high perfomance with distributed (CPU-based) machine learning. For the GPU-based GeePS, this turns out not to be the case.
Many recent ML model training systems, including for neural network training, use a parameter server architecture to share state among data-parallel workers executing on CPUs. Consistent reports indicate that, in such an architecture,
some degree of asynchrony (bounded or not) in parameter update exchanges among workers leads to significantly faster convergence than when using BSP. We observe the opposite with data-parallel workers executing on GPUs—while synchronization delays can be largely eliminated, as expected, convergence is much slower with the more asynchronous models because of reduced training quality.
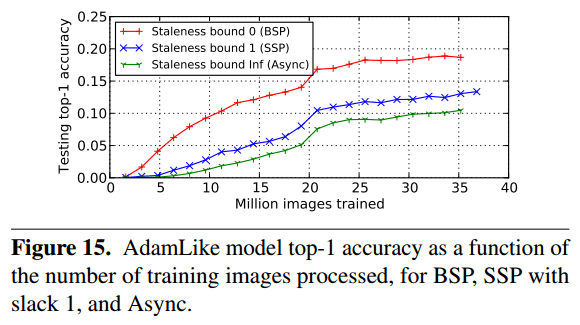
Figure 15 (above) shows that when using SSP (Slack 1) or Async, many more images must be processed to reach the same accuracy as with BSP (e.g. 2x more for Slack 1 and 3x more for Async to reach 10% accuracy).
We believe there are two reasons causing this outcome. First, with our specializations, there is little to no communication delay for DNN applications, so adding data staleness does not increase the throughput much. Second, the conditions in the SSP proofs of previous literatures do not apply to DNN, because training a DNN is a non-convex problem.

2 thoughts on “GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server”
Comments are closed.