Data Tiering in Heterogeneous Memory Systems – Dulloor et al. 2016
Another fantastic EuroSys 2016 paper for today, and one with results that are of great importance in understanding the cost and performance implications of the new generation of non-volatile memory (NVM) heading to our data centers soon. Furthermore, we also get some great insight into the amount of change that might be necessary in existing applications (e.g. in-memory datastores) to start taking effective advantage of the new hardware.
Using a small amount of DRAM (only 6% of the total memory footprint for GraphMat, and 25% for VoltDB and MemC3) the performance of these applications is only 13% to 40% worse than their DRAM based counterparts, but at much reduced cost, with 2x to 2.8x better performance/$. Intelligent data structure placement is the key to achieving thes result, without which these applications can perform 1.5x to 5.9x worse on the same configuration, depending on actual data placement.
We all know that NVM is coming, and that it falls on the spectrum somewhere between DRAM and NAND Flash, closer to DRAM. We’re all still guessing at the exact specifications and price of NVM technologies, but here’s how the authors see it stacking up against DRAM as a first approximation:

In short, much higher capacity, at one fifth of the cost of DRAM – but this is paid for with increased read latency (4x) and reduced write bandwidth (8x). The higher capacity and lower cost characteristics are very attractive for in-memory workloads when using NVM as a DRAM replacement / complement.
Data center operators are bound to ask whether this model for the usage of NVM to replace the majority of DRAM memory leads to a large slowdown in their applications? It is crucial to answer this question because a large performance impact will be an impediment to the adoption of such systems.
We can consider a spectrum of possible deployments – from today’s all-DRAM systems, to an all-NVM system, and various hybrid configurations with a mix of DRAM and NVM. Throughout the paper, the hybrid configurations are expressed as DRAM:NVM ratios, e.g. a 1/16 system has 16GB of NVM for every 1GB of DRAM.
The likely deployment of NVM is in systems that have a mix of DRAM and NVM. Most of the memory in such systems will be NVM to exploit their cost and scaling benefits, with a small fraction of the total memory being composed of DRAM.
I’m so excited to see the results here that I’m going to start with the findings that show what various NVM configurations might mean for price/performance of our systems, and then I’ll come back and explain the X-Mem design that enabled the team to adapt existing systems (MemC3, VoltDB, and GraphMat) to get the best results out of those configurations.
The Intel hybrid memory emulation platform (HMEP) was used to perform the evaluation.
The impact of NVM on key-value stores
Key-value stores are becoming increasingly important as caches in large data centers. We study a variation of Memcached called MemC3 – a recent advance over the open source Memcached that improves both memory efficiency and throughput over the stock implementation.
MemC3 uses a variant of cuckoo hashing and allocates memory for the cuckoo hash table at start-up. A dynamic slab allocator allocates values with the slab type determined by the size of allocation from the slab.
Depending on the HMEP configuration, an NVM-only configuration performed between 1.15x and 1.45x worse than a DRAM-only configuration. (Swapping from all DRAM to all NVM).
With 1/8 tiering, where only 12.5% of the application data is in DRAM, performance improves by 8-17% over NVM only because X-Mem allocates MemC3’s cuckoo hash DRAM. 1/4 fares even better and improves the performance to within 6-13% over DRAM-only, mainly because X-Mem is now able to place a large number of small values in DRAM and reduce the number of random accesses to NVM.
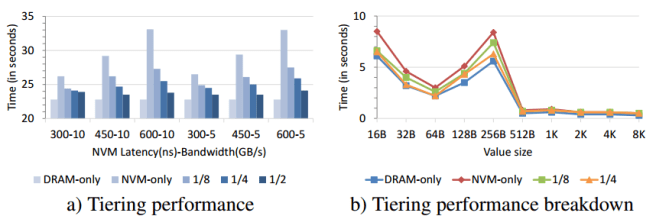
At 1/2 performance is within 5% of an all DRAM solution – but this comes at a much higher price/performance cost.
NVM-only provides the the best performance/$ across all HMEP configurations – 3.5x to 4.5x compared to DRAM only, mainly because the NVM-only overhead is relatively low. Finally, all tiering options provide significantly better performance/$ (1.6x to 3.1x) than DRAM only, resulting in a range of interesting performance/cost tradeoffs.
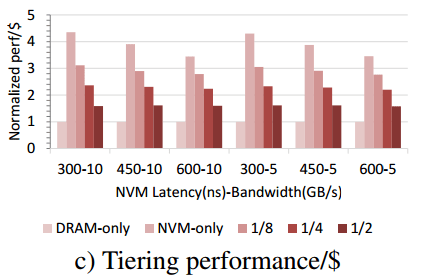
In summary, you can choose any point along a curve from 1.45x worse performance than an all DRAM solution, at 22% of the original cost, to 1.05x worse performance at 63% of the cost.
The impact of NVM on in-memory transaction processing
Here the authors studied VoltDB, an ACID-compliant distributed in-memory database, using the industry standard TPC-C benchmark. VoltDB uses 28 different data structures for indices and tables, which were modified to be managed by X-Mem (which places the data structures that will benefit the most into DRAM, and the rest in NVM, as we will see shortly). The top-10 data structures account for approximately 99% of the total memory footprint.
NVM-only performance is 26% to 51% worse than that of DRAM only… 1/16 performs better than NVM-only by 24-48%, by enabling X-Mem to place temporary data and three frequently accessed data structures in DRAM. 1/8 and 1/4 do not perform much better than 1/16… at 1/2 X-Mem is able to place all the data structures of VoltDB in DRAM, barring the very large but infrequently used CUSTOMER_NAME table and some portions of the tree-based primary index for the same table. As a result, 1/2s performance is 35-82% better than NVM-only, and only up to 9% worse than DRAM only.
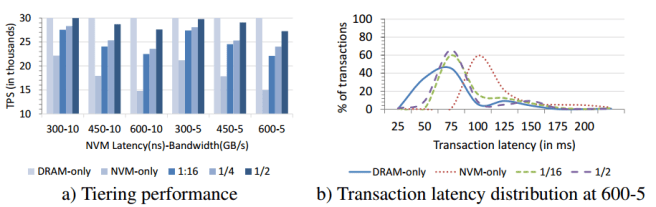
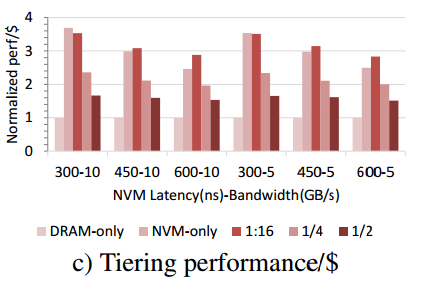
The best performance/$ configuration is 1/16 which is 2.5-3.7x cheaper (27-40% of the cost). All of the tiering options offer better performance/$ than the DRAM-only option. The 1/2 configuration is 1.5-1.7x better for example (59-67% of the cost).
The impact of NVM on graph processing
Exploding data sizes lead to a need for large-scale graph-structured computation in various application domains. Large graph processing, however, lacks access locality and therefore many graph analytics frameworks require that the entire data fit in memory. We study a high performance in-memory graph analytics framework called GraphMat that implements a vertex-centric scatter-gather programming model.
GraphMat’s performance with NVM only is worse that that of DRAM only by 2.6x to 5.9x, with the drop in performance particularly steep at lower peak NVM bandwidth.

Most of the performance gap can be attributed to sparse vectors, which account for only 3.5% of GraphMat’s footprint (of 32GB)… Performance improves dramaticallly with 1/32 tiering – only 1.17x to 1.55x worse that DRAM only – because X-Mem is able to place sparse vectors in available DRAM. With 1/16 tiering, X-Mem can allocate vertex data (less than 2.5% of the total footprint) in DRAM and that improve tiered GraphMat’s performance to within 1.13x to 1.4x of DRAM-only.
The 1/32 configuration performance/$ is 2.9x to 3.8x that of DRAM-only, and 2x to 3.4x compared to NVM-only. “Interestingly, 1/2’s performance/$ is worse than that of DRAM-only and NVM-only across all HMEP configurations.”
Optimising applications for hybrid memory systems with X-Mem
X-Mem provides a modified version of the malloc API (xmalloc) that enables the programmer to specify a tag for the data structure being allocated. X-Mem then profiles a run of the application to determine the benefit of placing a given application data structure in DRAM vs NVM. This profiling step results in a tag-to-priority map which is then used by the X-MEm runtime to determine the optimal placement of data structures.
Here’s an example where the application has three data structures (tree, hash, and buffer) each with their own tag. Memory allocations for each of these data structures are managed by a separate jemalloc instance. The tags used by the application are assigned internal priorities used to decide placement.

We use a greedy algorithm to maximize the total benefit by first sorting the (memory) regions ino a list ordered by decreasing benefit, and then placing regions starting from the head of the list into DRAM until no more space is left in DRAM. This algorithm is optimal because any placement that does not include one of the chosen regions can be further improved by replacing a region not in our chosen set with the missing region.
Regions may migrate between DRAM and NVM at runtime as new memory regions are added. X-Mem reissues an mbind call with the desired mapping for the region, and lets the Linux operating system do the heavy lifting of actually migrating the pages. This process leaves the application-visible virtual addresses unchanged, so no modifications are needed to the application.
When assigning piorities to tags, the analysis needs to take into account not only the frequency of access to data structures, but also the access patterns. The latter is important because the processor works hard to hide latency, and the access patterns play a big role in how well it can do that.
The authors consider random, pointer chasing, and streaming access patterns. For random accesses , the processor can use its execution window to detect and issue multiple requests simultaneously. In pointer chasing, the processor issues random accesses but the address for each access depends on the loaded value of a previous one, forcing the processor to stall until the previous load is complete. In streaming access, the instruction stream consists of a striding access pattern that can be detected in advance by the prefetcher to issue the requests in advance.
In Figure 5 we vary the latency and bandwidth characteristics of memory in our NVM performance emulator (§5.1). Pointer chasing experiences the maximum amount of stall latency, equal to the actual physical latency to memory. In the case of random access, out-of-order execution is effective at hiding some of the latency to memory. In the case of streaming access, the prefetcher is even more effective at hiding latency to memory. The order of magnitude difference in the performance of these access patterns validates our observation that the frequency of accesses alone is not sufficient to determine the “hotness” of a data structure, and illustrates the need for the more sophisticated classification of memory accesses proposed in this paper.

There are of course many more details on the inner workings of X-Mem and the performance benefit calculations used to determine where to place data structures in the paper itself.

2 thoughts on “Data Tiering in Heterogeneous Memory Systems”
Comments are closed.