The Linux Scheduler: a Decade of Wasted Cores – Lozi et al. 2016
This is the first in a series of papers from EuroSys 2016. There are three strands here: first of all, there’s some great background into how scheduling works in the Linux kernel; secondly, there’s a story about Software Aging and how changing requirements and maintenance can cause decay; and finally, the authors expose four bugs in Linux scheduling that caused cores to remain idle even when there was pressing work waiting to be scheduled. Hence the paper title, “A Decade of Wasted Cores.”
In our experiments, these performance bugs caused many-fold performance degradation for synchronization-heavy scientific applications, 13% higher latency for kernel make, and a 14-23% decrease in TPC-H throughput for a widely used commercial database.
The evolution of scheduling in Linux
By and large, by the year 2000, operating systems designers considered scheduling to be a solved problem… (the) year 2004 brought an end to Dennard scaling, ushered in the multicore era and made energy efficiency a top concern in the design of computer systems. These events once again made schedulers interesting, but at the same time increasingly more complicated and often broken.
Linux uses a Completely Fair Scheduling (CFS) algorithm, which is an implementation of weighted fair queueing (WFQ). Imagine a single CPU system to start with: CFS time-slices the CPU among running threads. There is a fixed time interval during which each thread in the system must run at least once. This interval is divided into timeslices that are allocated to threads according to their weights.
A thread’s weight is essentially its priority, or niceness in UNIX parlance. Threads with lower niceness have higher weights and vice versa.
A running thread accumulates vruntime (runtime / weight). When a thread’s vruntime exceeds its assigned timeslice it will be pre-empted.
Threads are organized in a runqueue, implemented as a red-black tree, in which the threads are sorted in the increasing order of their vruntime. When a CPU looks for a new thread to run it picks the leftmost node in the red-black tree, which contains the thread with the smallest vruntime.
So far so good, but now we have to talk about multi-core systems…
Firstly we need per-core runqueues so that context switches can be fast. Now we have a new problem of balancing work across multiple runqueues.
Consider a dual-core system with two runqueues that are not balanced.Suppose that one queue has one low-priority thread and another has ten high-priority threads. If each core looked for work only in its local runqueue, then high-priority threads would get a lot less CPU time than the low-priority thread, which is not what we want. We could have each core checknot only its runqueue but also the queues of other cores,but this would defeat the purpose of per-core runqueues. Therefore, what Linux and most other schedulers do is periodically run a load-balancing algorithm that will keep the queues roughly balanced.
Since load balancing is expensive the scheduler tries not to do it more often than is absolutely necessary. In addition to periodic load-balancing therefore, the scheduler can also trigger emergency load balancing when a core becomes idle. CFS balances runqueues not just based on weights , but on a metric called load, which is the combination of the thread’s weight and its average CPU utilization. To account for bias that could occur when one process has lots of threads and another has few threads, is version 2.6.38 Linux added a group scheduling (cgroup) feature.
When a thread belongs to a cgroup, its load is further divided by the total number of threads in its cgroup. This feature was later extended to automatically assign processes that belong to different
ttysto different cgroups (autogroup feature).
So can we just compare the load of all the cores and transfer tasks from the most loaded to least loaded core? Unfortunately not! This would result in threads being migrated without considering cache locality or NUMA. So the load balancer uses a hierarchical strategy. Each level of the hierarchy is called a scheduling domain. At the bottom level are single cores, groupings in higher levels depend on how the machine’s physical resources are shared.
Here’s an example:
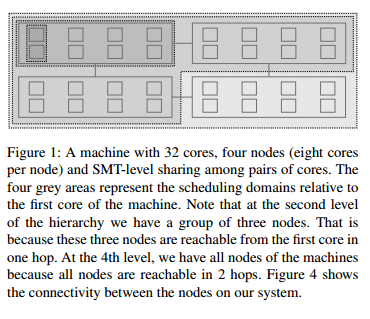
Load balancing is run for each scheduling domain, starting from the bottom to the top. At each level, one core of each domain is responsible for balancing the load. This core is either the first idle core of the scheduling domain, if the domain has idle cores whose free CPU cycles can be used for load balancing, or the first core of the scheduling domain otherwise. Following this, the average load is computed for each scheduling group of the scheduling domain and the busiest group is picked, based on heuristics that favor overloaded and imbalanced groups. If the busiest group’s load is lower than the local group’s load, the load is considered balanced at this level. Otherwise, the load is balanced between the local CPU and the busiest CPU of the the group, with a tweak to ensure that load-balancing works even in the presence of tasksets.
The scheduler prevents duplicating work by running the load-balancing algorithm only on the designated core for the given scheduling domain. This is the lowest numbered core in a domain if all cores are busy, or the lowest numbered idle core if one or more cores are idle. If idle cores are sleeping (power management) then the only way for them to get work is to be awoken by another core. If a core thinks it is overloaded it checks whether there have been tickless idle cores in the system for some time, and if so it wakes up the first one and asks it to run the periodic load balancing routine on behalf of itself and all of the other tickless idle cores.
Four scheduling bugs
With so many rules about when the load balancing doesor does not occur, it becomes difficult to reason about how long an idle core would remain idle if there is work to do and how long a task might stay in a runqueue waiting for its turn to run when there are idle cores in the system.
The four bugs that the authors found are the group imbalance bug, the scheduling group construction bug, the overload on wakeup bug, and the missing scheduling domains bug.
Group imbalance
Oh, the joy of averages for understanding load. I believe Gil Tene has a thing or two to say about that :).
When a core attempts to steal work from another node, or, in other words, from another scheduling group, it does not examine the load of every core in that group, it only looks at the group’s average load. If the average load of the victim scheduling group is greater than that of its own, it will attempt to steal from that group; otherwise it will not. This is the exact reason why in our situation the underloaded cores fail to steal from the overloaded cores on other nodes. They observe that the average load of the victim node’s scheduling group is not any greater than their own. The core trying to steal work runs on the same node as the high-load R thread; that thread skews up the average load for that node and conceals the fact that some cores are actually idle. At the same time, cores on the victim node, with roughly the same average load, have lots of waiting threads.
The fix was to compare minimum loads instead of the average. The minimum load is the load of the least loaded core in the group. “If the minimum load of one scheduling group is lower than the minimum load of another scheduling group, it means that the first scheduling group has a core that is less loaded than all cores in the other group, and thus a core in the first group must steal from the second group.” With the fix applied the completion time of a make/R workload decreased by 13%, and a 60 thread benchmark with four single-threaded R processes ran 13x faster.
Scheduling group construction
The Linux taskset command pins applications to run on a subset of the available cores. When an application is pinned on nodes that are two hops apart, a bug prevented the load balancing algorithm from migrating threads between them.
The bug is due to the way scheduling groups are constructed, which is not adapted to modern NUMA machines such as the one we use in our experiments. In brief, the groups are constructed from the perspective of a specific core (Core 0), whereas they should be constructed from the perspective of the core responsible for load balancing on each node.
The result is that nodes can be included in multiple scheduling groups. Suppose Nodes 1 and 2 both end up in two groups…
Suppose that an application is pinned on Nodes 1 and 2 and that all of its threads are being created on Node 1 (Linux spawns threads on the same core as their parent thread; when an application spawns multiple threads during its initialization phase, they are likely to be created on the same core – so this is what typically happens). Eventually we would like the load to be balanced between Nodes 1 and 2. However, when a core on Node 2 looks for work to steal,it will compare the load between the two scheduling groups shown earlier. Since each scheduling group contains both Nodes 1 and 2, the average loads will be the same, so Node2 will not steal any work!
The fix is to change the construction of scheduling groups. Across a range of applications, this results in speed-ups ranging from 1.3x to 27x.
Overload-on-wakeup
When a thread goes to sleep on Node X and the thread that wakes it up later is running on that same node, the scheduler only considers the cores of Node X for scheduling the awakened thread. If all cores of Node X are busy, the thread will wake up on an already busy core and miss opportunities to use idle cores on other nodes. This can lead to a significant under-utilization of the machine, especially on workloads where threads frequently wait.
The original rationale for the behaviour was to maximise cache reuse – but for some applications waiting in the runqueue for the sake of better cache reuse does not pay off. The bug was triggered by a widely used commercial database configured with 64 worker threads.
To fix this bug, we alter the code that is executed when a thread wakes up. We wake up the thread on the local core – i.e. the core where the thread was scheduled last – if it is idle; otherwise if there are idle cores in the system, we wake up the thread on the core that has been idle for the longest amount of time. If there are no idle cores, we fall back to the original algorithm to find the core where the thread will wake up.
The fix improved performance by 22.2% on the 18th query of TPC-H, and by 13.2% on the full TPC-H workload.
Missing scheduling domains
The final bug seems to been inadvertently introduced during maintenance.
When a core is disabled and then re-enabled using the /proc interface, load balancing between any NUMA nodes is no longer performed… We traced the root cause of the bug to the code that regenerates the machine’s scheduling domains. Linux regenerates scheduling domains every time a core is disabled. Regenerating the scheduling domains is a two-step process: the kernel regenerates domains inside NUMA nodes, and then across NUMA nodes. Unfortunately, the call to the function generating domains across NUMA nodes was dropped by Linux developers during code refactoring. We added it back, and doing so fixed the bug.
Before the fix, disabling and then re-enabling one core in the system could cause all threads of an application to run on a single core instead of eight. Unsurprisingly, the system performs much better (up to 138x better in one case!) with the fix.
Lessons and tools
… new scheduler designs come and go. However, a new design, even if clean and purportedly bug-free initially, is not a long-term solution. Linux is a large open-source system developed by dozens of contributors. In this environment, we will inevitably see new features and ‘hacks’ retrofitted into the source base to address evolving hardware and applications.
Is improved modularity the answer?
We now understand that rapid evolution of hardware that we are witnessing today will motivate more and more scheduler optimizations. The scheduler must be able to easily integrate them, and have a way of reasoning about how to combine them. We envision a scheduler that is a collection of modules: the core module, and optimization modules…
Catching the kind of bugs described in this paper with conventional tools is tricky – there are no crashes or out-of-memory conditions, and the lost short-term idle periods cannot be noticed with tools such as htop, sar, or perf.
Our experience motivated us to build new tools, using which we could productively confirm the bugs and understand why they occur.
The first tool is described by the authors as a sanity checker. It verifies that no core is idle while another core’s runqueue has waiting threads. It allows such a condition to exist for a short period, but raises an alert if it persists. The second tool was a visualizer showing scheduling activity over time. This makes it possible to profile and plot the size of runqueues, the total load of runqueues, and the cores that were considered during periodic load balancing and thread wakeups.
Here’s an example of a visualization produced by the tool:
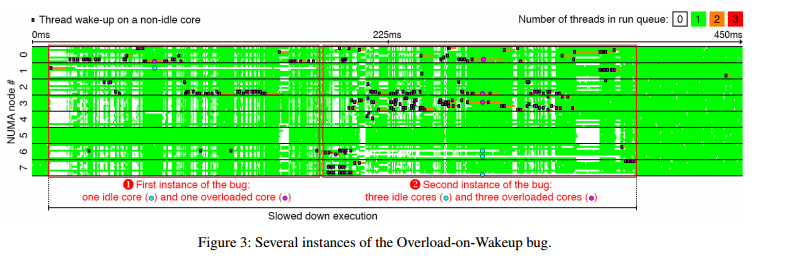
(click for larger view).
The authors conclude:
Scheduling, as in dividing CPU cycles among threads was thought to be a solved problem. We show that this is not the case. Catering to complexities of modern hardware, a simple scheduling policy resulted in a very complex bug-prone implementation. We discovered that the Linux scheduler violates a basic work-conserving invariant: scheduling waiting threads onto idle cores. As a result, runnable threads may be stuck in runqueues for seconds while there are idle cores in the system; application performance may degrade many-fold. The nature of these bugs makes it difficult to detect them with conventional tools. We fix these bugs, understand their root causes and present tools, which make catching and fixing these bugs substantially easier. Our fixes and tools will be available at http://git.io/vaGOW.

Thanks for writing such an interesting article; it has certainly been quite a while since I’ve seen anything new on the scheduler front!
I’ve had to do manual taskset/numactl/cgroups thread pinning strategies throughout most of my career in investment banks and it was always a painful task. Interestingly, after doing a bit of research, I found that the one of the main reasons for poor scheduling (other than the bugs you’ve mentioned) is that thread management itself is quite a complex problem, with a number of solution equal to the number of cores to the power of threads of solutions.
If you take a system with 64 cores and 200 threads, the number of possible scheduling solutions (~10^361) is greater than the total number of atoms in the universe (~10^80)!
and fortunately we don’t have to brute force all of them… ;)
Great job! Interesting read!
I’ve posted on this here.
https://plus.google.com/+ChristopherGaul/posts/V1MkFkeS9bQ
“Not only is this an intersting story, it also gives a good overview of how scheduling works on Linux in general. Worth a read no matter what OS you prefer as there will be similar processes going on.
While reading this, two issues came to mind.
One, how will the proposed solutions take into account the ever important issue of power savings? The more cores active, the higher power consumption. Does the system really spread tasks evenly across all cores, or is it better to leave cores idle, if possible, and put the cores in a lineup. Fully utilizing each core before load spreading to the next core while leaving unnecessary cores in a power saving mode?
Two, what about turbo modes on modern CPU’s? Does this new solution take that into account? For some applications, leaving tasks on one core will result in better performance as the CPU can kick that core into it’s “turbo” mode.
Both of these considerations will matter greatly on mobile devices, especially devices with heterogeneous SMP. ARM Big.Little for example.”
About this “overload on wakeup” issue:
“if there are idle cores in the system, we wake up the thread on the core that has been idle for the longest amount of time.”
Did you consider waking up the core that has been idle for least time? Usually power management on CPUs tends to put cores that have been idle longest to deeper sleep which means longer time to wake up. Thus I think it would make sense to wake up the core that has slept the least time instead. In theory it should save more power and lower the wake up latency.
Hi Kalle,
I’m just the messenger I’m afraid! I don’t know if the authors also experimented with this, but it would be interesting to see the results if so.
Regards, Adrian.
There is something else to consider here, the longest the sleep time the coolest the core is, and so it consumes less energy. So waking the core with more sleep time seem to be a good strategy for mobile devices.
It reminds me lots of the issues we covered with the OSv scheduler design.
It was a work of art: https://www.usenix.org/system/files/conference/atc14/atc14-paper-kivity.pdf http://anzwix.com/a/OSv/SchedNewSchedulerAlgorithm
Linux is far more complex and has conflicting requirements from all directions – latency vs throughput vs power.
We’ve encountered the scheduler problem with linux kernel on a quite large multi-user system. The efficiency of CFS fell totally apart with few thousand processes that were requiring small amounts of CPU at a time but regularly. We solved the problem by changing the CFS to BFS scheduler[1] which behaved perfectly in our use case.
We made the change in 2010 and there are few graphs available that show what happened to the runqueue[2]. The use of the server was still increasing steadily over the year and the actual usage pattern didn’t change. There are more graphs available of the same time.[3]
The point of BFS scheduler is to use as few resources as possible to actually making the scheduling decisions and have always bias for processes using less CPU. It has proven to be well suited in computationally intensive tasks too.
One of our members is currently doing protein folding calculations as part of his thesis research on the same server running 10k other processes and having over 1000 concurrent SSH sessions by the users active. The research effort uses all the rest CPU resources available (worth some 10 – 12 cores) while other users suffer no measurable effect from it.
If you are interested in our data and/or real life experiences with CPU scheduling, please feel free to sen email.
[1] : http://ck.kolivas.org/patches/bfs/
[2] : http://warod.kapsi.fi/b/bfs/lakka.kapsi.fi-vmstat-year.png
[3] : http://warod.kapsi.fi/b/bfs/
Hi Jesse, Many thanks for this. It adds a lot to hear of real cases of scheduling problems ‘in the wild’ and what was done to fix them. Regards, Adrian.
Didn’t like cfs for obvious reasons and using BFS for years.
Those wastedcore patches from the git link are even faster than BFS.
Many thanks.
Sorry for a user point of view, but: were those patches sent to the Linux kernel? Did kernel developers applied them, or commented something? Or are they just laying around on github waiting for everybody to forget?
I’d probably answer myself: the discussion on kernel mailing list is here https://lkml.org/lkml/2016/4/23/135
Nice post Adrian. For me this finding highlights a broader issue. Computer science as an academic and research field has a deep and pervasive Linux/Unix bias that can lead to surprising blind spots and lack of awareness of major swaths of the computing landscape. Most notably, there’s an alarming lack of awareness of Windows and its underlying technologies. I was expecting Lozi et al to compare the Linux kernel scheduler to other OS schedulers, to provide some context and a frame of reference, with the most natural contrast objects being Windows Server 2012 or so and FreeBSD. But they didn’t mention other schedulers. I think Windows Server is a very sweet piece of engineering from a scheduling and async standpoint, but CS researchers never talk about it.
This ignorance of the broader computing landscape probably makes decadal-scale problems more likely because it’s harder to notice things like this when you have nothing to compare it to. CS is too much of a monoculture right now, and I think it has dramatically slowed progress in computing. Everything Rob Pike said about the Unix monoculture around 2000 is still true today. We really need to move forward from POSIX. I hope unikernels will push us onward.
Nobody compares with Windows/OS X/iOS/Whatever-Closed-OS schedulers for obvious reasons: they’re closed.
Imagine for a second: you’re a CS researcher, and excited to make a dissertation about modern CPU scheduling. So you’re divining into CFS (a scheduler) (besides, of course, existing papers), researching its internals, and writing the research.
Now, if you’d want to compare it with another open source one — say, BFS — it would ×1⅓ the work, you need to do the same research once more.
Now, if you’d wanted to compare with closed source scheduler — and in your example it’s not just a module closed, it is whole OS closed, so you’d find first where the module assembly resides — you’d need to reverse-engineer it. You can, of course, judge how does it works by some hints, which either present on the Internet, or in threading-relevant system API — but to be sure you’d need to reverse-engineer it either way. It is so much work that you could write a whole separate paper about it!
Constantine is right on the money with his response. I’m not sure what Joe Duarte is thinking, but to everyone else it’s pretty obvious that no one talks about, much less works on the Windows scheduler simply because they can’t. Not only is the entire OS closed source, but thanks to the lobbying of companies like Microsoft, even trying is a crime. Given that there are now companies in the US that exist solely through IP lawsuits it’s easy to see that no researcher wants to run afoul of them or the DMCA. Besides, what purpose would it serve? Is Microsoft going to put Windows up on Github so people can submit patches and improvements? Not in our lifetime.
Honestly I’m skeptical that Mr. Duarte’s comment is actually anything but Microsoft fanboyism anyway as I can’t see why a serious academic would actually ask a question with such an obvious answer.
If the question were legitimate, there are dozens of other OS scheduler comparisons to be made that are source available and research friendly. Hell even OS X has a more accessible core in Darwin. oh wait, that’s part of the evil POSIX monoculture too.
UNIX/Linux/POSIX is not a stale, stagnant, monoculture by any stretch of the imagination. In reality it’s a highly diverse ecosystem that happens to just have a single common core of design sanity that has allowed some of the greatest innovations in computer science and OS design so far in history. The broad range of schedulers, scheduler designs, and theories of scheduler operation that exist in Linux alone are refutation of Mr. Duarte’s statement of monoculture and constrained thinking in the UNIX/Linux/POSIX world, but if you don’t believe it you only have to read through the Linux Kernel Mailing List on a regular basis to know that out of the box thinking, debate, and challenging the traditional way of doing things is alive and well.
I do admit that I would love to see the source of an OS that’s so long been shackled to backwards compatibility with it’s poorly multitasking, DOS based, memory restricted roots. I bet the number of kludges in place are enough to fodder dozens of CS papers on how not to do things.
(I’m not sure what happened — my reply just disappeared; so sorry for double post if a duplicate would appear for whatever reason)
Nobody compares with Windows/OS X/iOS/Whatever-Closed-OS schedulers for obvious reasons: it is closed.
Imagine for a second: you’re a CS researcher, and excited to make a dissertation about modern CPU scheduling. So you’re divining into CFS (a scheduler) (besides, of course, existing papers), researching its internals, and writing the research.
Now, if you’d want to compare it with another open source one — say, BFS — it would ×1⅓ the work, you need to do the same research once more.
Now, if you’d wanted to compare with closed source scheduler — and in your example it’s not just a module closed, it is whole OS closed, so you’d find first where the module assembly resides — you’d need to reverse-engineer it. You can, of course, judge how does it works by some hints, which either present on the Internet, or in threading-relevant system API — but to be sure you’d need to reverse-engineer it either way. It is so much work that you could write a separate paper about it!
Hi Constantine,
Your guess was correct – all comments are moderated in an attempt to keep spam away. So it sometimes takes a while for them to appear based on my availability. It’s the best compromise I’ve found so far given the tools to hand :(
Regards, Adrian.
Hi Constantine – I should’ve said something about the closed/open source issue, since it’s a reasonable and easy-to-anticipate argument.
Most of the research I’m thinking of doesn’tt require access to source code, and much of the published research doesn’t dive into source code. In fact, the only mention of Windows in the Lozi et al paper is to highlight the tracing tool available for it:
“Event Tracing for Windows [2] and DTrace [1] are frameworks that make it possible to trace application and kernel events, including some scheduler events, for the Microsoft Windows, Solaris, MacOS X and FreeBSD operating systems.”
There are lots of things that people can do with Windows as far as testing and research. Moreover, I’d expect Microsoft to be willing, and in some cases eager, to help researchers test and explore Windows. That said, they could probably do a lot more to invite researchers to do so.
Reblogged this on dirisujesse'blog.
A very very interesting article….
great job authors.
The paper by the authors explains in more details about the complexity of the schedulers … as well as the discovery of bugs and the issues of thread scheduling on idle cores.
got to learn a lot from the paper.
At last I found “A Paper” as a mirror for me to see my questions, thoughts and solutions (present/future/possible). Great job. Spread the word!