AnyLog: a grand unification of the Internet of Things, Abadi et al., CIDR’20
The Web provides decentralised publishing and direct access to unstructured data (searching / querying that data has turned out to be a pretty centralised affair in practice though). AnyLog wants to do for structured (relational) data what the Web has done for unstructured data, with coordinators playing the role of search engines. A key challenge for a web of structured data is that it’s harder to see how it can be supported by advertising, so AnyLog needs a different incentive scheme. This comes in the form of micropayments. Micropayments require an environment of trust, and in a decentralised context that leads us to blockchains.
There have been several efforts to create a version of the WWW for "structured" data, such as the Semantic Web and Freebase. Our approach differs substantially by (1) providing economic incentives for data to be contributed and integrated into existing schemas, (2) offering a SQL interface instead of graph based approaches, (3) including the computational and storage infrastructure in the architectural vision.
Note that AnyLog also differs from projects such as DeepDive or Google’s Knowledge Graph. These aim at extracting structured data from existing web resources, AnyLog is concerned with providing access to structured data however it was obtained.
Despite the "Internet of Things" featuring prominently in the title, there’s nothing particular to IoT in the technical solution at all. It just happens to be an initial use case that fits well with the AnyLog model. This much is openly acknowledged by the authors. But I think there’s another more interesting conflation going on. Much of the paper concerns a monetisation scheme for decentralised data. That’s necessary when serving structured data in a manner that can’t be supported by advertising, but on my reading I see no reason it couldn’t also be used to provide alternative business models for unstructured data too (i.e., the web as we know it). I’m going to try and tease apart the micropayments mechanism from the structured data application of it in this write-up. That’s not something you’ll find in the original paper, so caveat lector, and apologies to the authors if I’ve stretched the boundaries too far here.
Market participants
There are five different types of member in an AnyLog system, and any network node can join without restriction as any type of member.
- Clients issue queries over data (queries can be one-off, i.e., static, or continuous). In AnyLog queries are expressed in SQL, but you could also think of e.g. a standard HTTP GET request as a distributed key-value store lookup query.
- Coordinators are servers that receive queries and return results (search engines). In the decentralised setting of AnyLog, coordinators have to plan how best to obtain the desired query results from a set of data providers, called contractors. It would be possible for a coordinator to also maintain their own giant copy of the public data available in the system, assuming some freshness guarantees, but the payment mechanisms in AnyLog make a crawl in advance of queries unattractive. (Caching of query results on the other hand, looks like a good business model, at large enough scale these might amount to pretty much the same thing).
- Contractors store the actual data and provide a query interface to access the data that they hold. They’re analogous to web hosting providers for web data (i.e., web pages).
- Publishers are the producers of the actual data to be served by the network. Publishers ship data to contractors for hosting and serving. (Nothing seems to prevent a given network node from being both contractor and publisher for its own data, which might be a common arrangement).
- A blockchain holds the metadata catalog for the system (participants register on the blockchain for discovery purposes) and also provides the trust and dispute resolution anchor for micropayments.
Contractors can organise into contractor groups to collectively satisfy more stringent performance and fault-tolerance guarantees than any one contractor may be able to do on their own. Likewise publishers may form publisher groups (presumably to share marketing costs and revenues). Groups can be centralised or decentralised, with decentralised groups managed by smart contracts on the AnyLog blockchain.
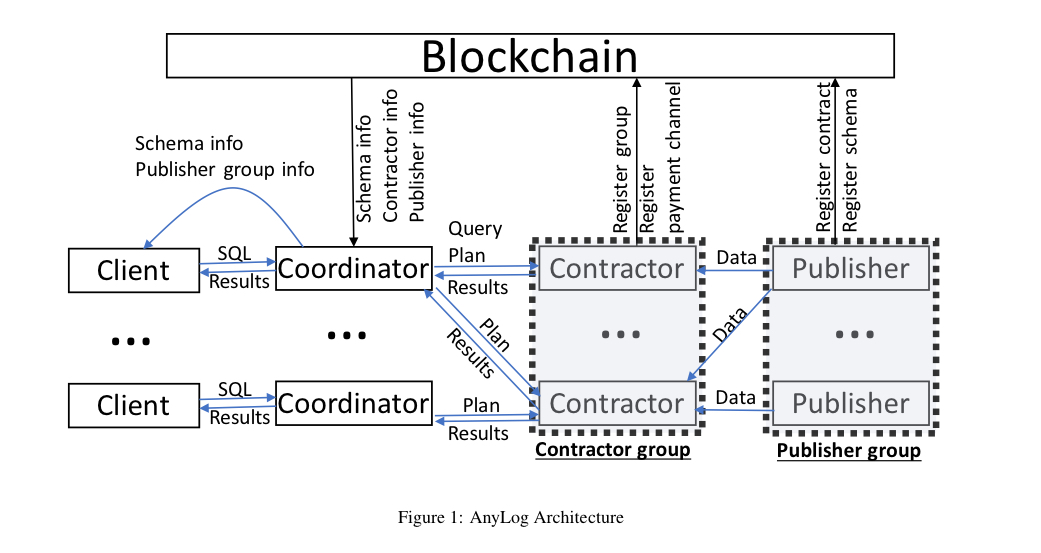
So far, especially if you replace ‘blockchain’ by ‘DNS’ in the lookup role, this looks very much like the web as we know it. But there’s one critical difference – AnyLog has an integral micropayments system.
AnyLog differs from the traditional WWW in the way that it provides incentives and financial reward for performance tasks that are critical to the well-being of the system as a whole, including contribution, integration, storing, and processing of data, as well as protecting the confidentiality, integrity, and availability of that data.
Payments
Coordinators and contractors receive a financial reward for every query that they serve, and publishers receive a financial reward every time data that they contributed participates in a query result. Clients therefore pay to query the system and to view results. Your first reaction may well be something like: "Every web request is a multi-party transaction on the blockchain? How’s that going to work given what we know about the throughput and latency of blockchains, and the associated mining costs?". And the answer of course, is the by now familiar move of keeping most of this off of the blockchain using off-chain protocols (state channels).
At a high level, most AnyLog protocols can be conducted via direct peer-to-peer interactions between nodes. By signing and authenticating messages, nodes maintain evidence of the agreed-upon state of a protocol.
Incentives for publishers
Publishers are incentivised to contributed to the platform because they get paid (by contractors) whenever someone accesses their data. On the assumption that publicly available data will be queried more often than private data, then this also incentivises publishers to make their data available to anyone. Publishers and contractors enter into agreements via smart contracts.
Incentives for contractors
Contractors are incentivised to enter into good business relationships with publishers because they get paid by serving publisher data. Contracts between contractors and publishers also typically specify integrity, availability, and confidentiality guarantees. SLA enforcement mechanisms (discussed below) penalise contractors for failing to meet these conditions.
Incentives for coordinators
Coordinators attract business by providing a great user interface for clients to construct queries, helping them find appropriate data sources, and so on.
We anticipate a competitive marketplace of coordinators – each one with their own indexing and caching layers to improve performance of queries and reduce costs to the client. Coordinators have total freedom to decide how many tokens to charge a client to process a query…
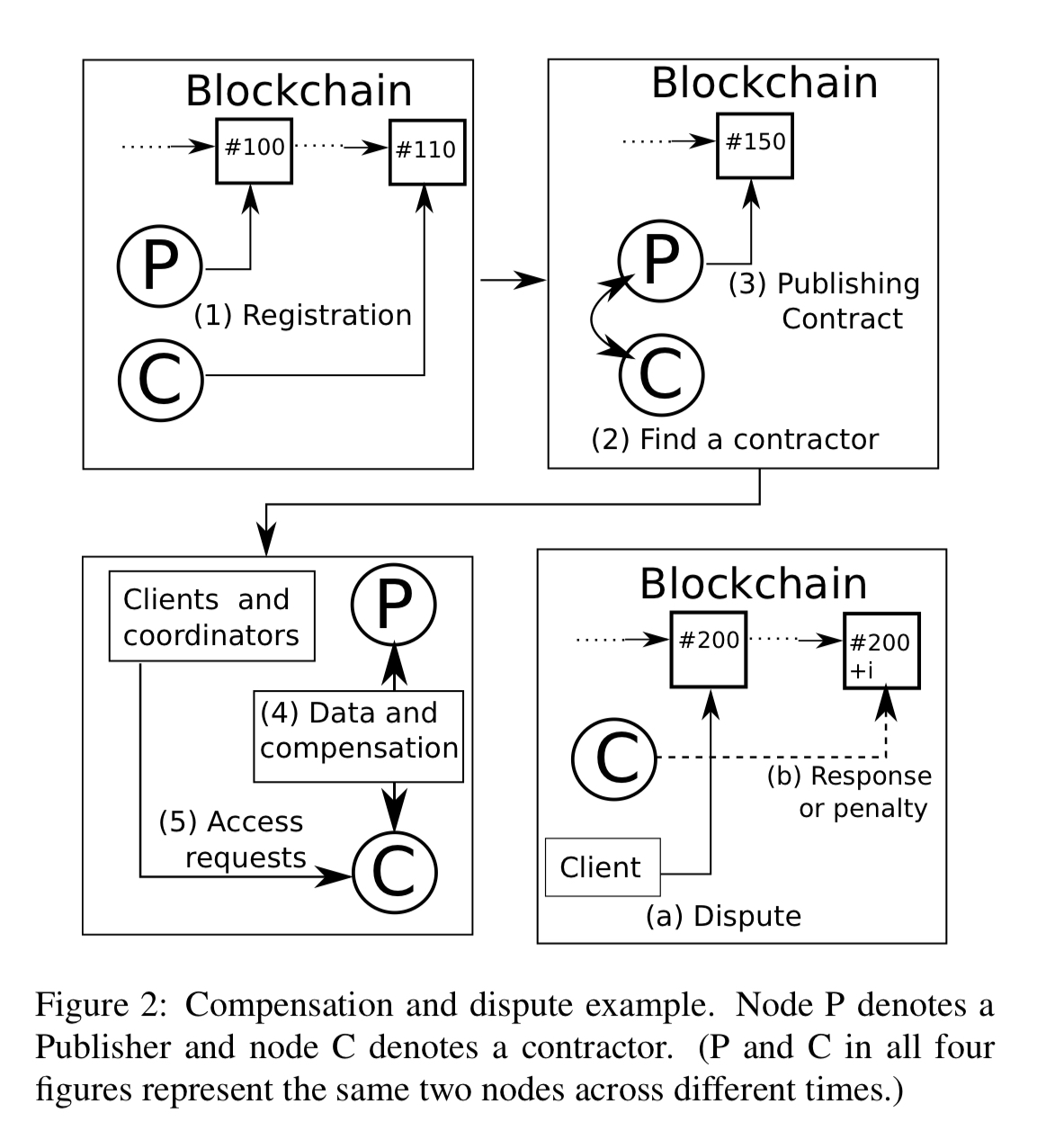
But what about…?
Contractors that don’t want to pay publishers?
Once a contractor has data from a publisher, what prevents them from under-reporting the number of results returned for queries (and thus under-paying the publishers)? Standard business relationships and reputation is a part of the answer here, but publishers may also choose to protect their data from contractors. In this latter case contractors can either process queries within a TEE (trusted by the publisher), or use enrcypted query processing techniques. Publishers can then deploy ‘re-encryption enclaves’ that reveal results to clients or coordinators based on authorization tokens. The need for a publisher-generated authorization token, specific to the client, means that the contractor can’t bypass the publisher. Lack of trust between contractors and publishers is expensive to mitigate!
Coordinators that don’t want to pay contractors?
Similar mechanisms can be used to prevent coordinators from caching and returning results without paying contractors and publishers. Given their position of power in the network, such caching seems to be highly incentivised in the absence of such mechanisms. The feeling I have reading the paper is that the authors expect encryption mechanisms to be the exception rather than the rule, but I’m not so sure. Consider this quote from the paper regarding the problem of freeloading clients, and replace ‘client’ with ‘coordinator’:
Clients must pay for each query they send to AnyLog. Once a client obtains access to the result of a query, there are few effective technological mechanisms for preventing or constraining further disclosure. A client may attempt to resell the data they have access to or disclose it publicly. Therefore, publishers must take unauthorized disclosures into account when setting query prices or providing access to decryption keys. In some settings, relying on more traditional deterrence mechanisms such as legal contracts may be appropriate.
That doesn’t sound particularly inspiring to be honest!
In the case of coordinators though, then a ‘freeloading protection’ scheme (see e.g. Zhang et al. can remove the coordinator’s ability to authenticate the data to a third party. (The some thing applies to a client reselling the data, but I find the coordinator use case more compelling).
Query result integrity
Query result integrity can be achieved by utilising either attested Trusted Execution Environments for query execution, or by using Authenticated Data Structures (ADSs) such as Merkle trees. Query results can be sent to an SLA contract which can validate the TEE signature or ADS proof. This contract may e.g. impose fines on contractors behaving badly.
To disincentivize the contractor from processing queries dishonestly, coordinators are occasionally permitted to request an ADS proof for one of their previously answered queries… Since the contractor must commit to the query results before it knows which queries it must produce proofs for, it runs a risk of getting caught proportional to the ratio of proofs to queries.
SLA enforcement of availability clauses
SLA contracts between contractors and publishers are specified in terms of a period duration and a minimum record number. A contractor must serve the minimum number of records within each period. Periods (e.g. 48 hours) are divided into batches (e.g. 10 minutes) with the bookkeeping metrics for each batch written to the blockchain. If a contractor doesn’t have enough incoming volume of requests to meet the minimum record number target the contractor can send a request to the SLA contract to have an exception made and avoid a penalty. To keep things honest this seems to need all requests to be logged on the blockchain, but that wouldn’t work with the throughput constraints. Presumably they are also kept in off-chain structures.
An embodiment for structured data
To make all this work for structured data the coordinator needs to be able to accept SQL queries, and must do query planning and optimisation across a distributed set of coordinators. Market forces are expected to encourage data publishers to confirm to one of a comparatively small number of schemas per application domain. Schema information is stored on the blockchain. Contractors could presumably offer UPDATE ... or COPY ... SQL processing for publishers.
The query optimization problem is more challenging for AnyLog coordinators than in traditional parallel database systems. The data relevant for any particular query may be stored across many different contractors, that each have substantially different levels of quality of service and query processing latencies.
Unfortunately, the paper doesn’t go into any further details for how such query optimisation and planning might be done.
An embodiment for structured data for IoT
AnyLog is not just the name of a research system, it’s also a company, AnyLog.co standing up an initial version of the platform for IoT data. Their home page claims the AnyLog software is open source, but the repo it links to contains only documentation at the moment.

Shouldn’t we all stop reading and put a paper aside upon the first encounter of the word blockchain? We are now two years past peak blockchain. The first application of a blockchain architecture, Bitcoin and its copycats, was a disaster for everyone except the coin and token salespeople. Not much has followed in terms of convincing applications.
I don’t see how it keeps out bad publishers. Eg, the structured data form of fake news, or low-quality content.
The unstructured internet has, pagerank and it’s seo friends. How could they fit in this model where every crawl costs the coordinator?