SmoothOperator: reducing power fragmentation and improving power utilization in large-scale datacenters Hsu et al., ASPLOS'18 What do you do when your theory of constraints analysis reveals that power has become your major limiting factor? That is, you can’t add more servers to your existing datacenter(s) without blowing your power budget, and you don’t want to … Continue reading SmoothOperator: reducing power fragmentation and improving power utilization in large-scale datacenters
Tag: Facebook
Popularity predictions of Facebook videos for higher quality streaming
Popularity prediction of Facebook videos for higher quality streaming Tang et al., USENIX ATC’17 Suppose I could grant you access to a clairvoyance service, which could make one class of predictions about your business for you with perfect accuracy. What would you want to know, and what difference would knowing that make to your business? … Continue reading Popularity predictions of Facebook videos for higher quality streaming
SVE: Distributed video processing at Facebook scale
SVE: Distributed video processing at Facebook scale Huang et al., SOSP’17 SVE (Streaming Video Engine) is the video processing pipeline that has been in production at Facebook for the past two years. This paper gives an overview of its design and rationale. And it certainly got me thinking: suppose I needed to build a video … Continue reading SVE: Distributed video processing at Facebook scale
Canopy: an end-to-end performance tracing and analysis system
Canopy: an end-to-end performance tracing and analysis system Kaldor et al., SOSP’17 In 2014, Facebook published their work on ‘The Mystery Machine,’ describing an approach to end-to-end performance tracing and analysis when you can’t assume a perfectly instrumented homogeneous environment. Three years on, and a new system, Canopy, has risen to take its place. Whereas … Continue reading Canopy: an end-to-end performance tracing and analysis system
DQBarge: Improving data-quality tradeoffs in large-scale internet services

DQBarge: Improving data-quality tradeoffs in large-scale Internet services Chow et al. OSDI 2106 I'm sure many of you recall the 2009 classic "The Datacenter as a Computer," which encouraged us to think of the datacenter as a warehouse-scale computer. From being glad simply to have such a computer, the bar keeps on moving. We don't … Continue reading DQBarge: Improving data-quality tradeoffs in large-scale internet services
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
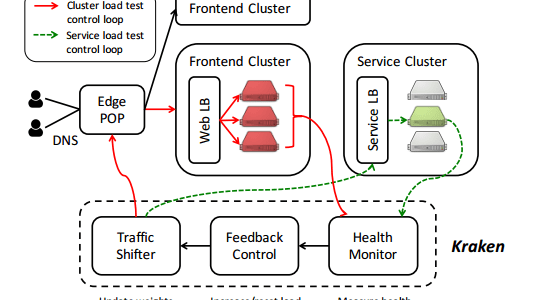
Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services Veeraraghavan et al. (Facebook) OSDI 2016 How do you know how well your systems can perform under stress? How can you identify resource utilization bottlenecks? And how do you know your tests match the condititions experienced with live … Continue reading Kraken: Leveraging live traffic tests to identify and resolve resource utilization bottlenecks in large scale web services
Realtime data processing at Facebook
Realtime Data Processing at Facebook Chen et al. SIGMOD 2016 ‘Realtime Data Processing at Facebook’ provides us with a great high-level overview of the systems Facebook have built to support real-time workloads. At the heart of the paper is a set of five key design decisions for building such systems, together with an explanation of … Continue reading Realtime data processing at Facebook
SocialHash: An assignment framework for optimizing distributed systems operations on social networks
SocialHash: An assignment framework for optimizing distributed systems operations on social networks - Shalita et al., NSDI '16 Large scale systems frequently need to partition resources or load across multiple nodes. How you do that can make a big difference. A common approach is to use a random distribution (e.g. via consistent hashing), which usually … Continue reading SocialHash: An assignment framework for optimizing distributed systems operations on social networks
Gorilla: A fast, scalable, in-memory time series database
Gorilla: A fast, scalable, in-memory time series database - Pelkonen et al. 2015 Error rates across one of Facebook's sites were spiking. The problem had first shown up through an automated alert triggered by an in-memory time-series database called Gorilla a few minutes after the problem started. One set of engineers mitigated the immediate issue. … Continue reading Gorilla: A fast, scalable, in-memory time series database
Memory Networks
Memory Networks Weston et al. 2015 As with the Neural Turing Machine that we look at yesterday, this paper looks at extending machine learning models with a memory component. The Neural Turing Machine work was developed at Google by the DeepMind team, today's paper on Memory Networks was developed by the Facebook AI Research group. … Continue reading Memory Networks
