SocialHash: An assignment framework for optimizing distributed systems operations on social networks – Shalita et al., NSDI ’16
Large scale systems frequently need to partition resources or load across multiple nodes. How you do that can make a big difference. A common approach is to use a random distribution (e.g. via consistent hashing), which usually ensures even load balancing. If there is some structure to the resources or the way they are accessed that we can exploit though, we may be able to do better. We saw a recent example of this when we looked at Optimizing Distributed Actor Systems. Another example would be co-partitioning or co-locating relational tables. Facebook used to use a random distribution to assign objects to components, but switched to an assignment method called Social Hashing that exploits properties in the social graph. This method has now been in production at Facebook for over a year, handling over 78% of web traffic routing and tens of thousands of storage servers. After making the switch they saw huge benefits: cache miss rates for production workloads fell by 25%, and the average response time for production workloads on one of their storage systems fell by 50%. What all these results show is that it’s well worth taking a few moments to consider whether or not there’s any structure in your own workloads that can be exploited in a similar manner.
Almost all of the user-visible data and information served up by the Facebook app is maintained in a single directed graph called the Social Graph. Friends, Checkins, Tags, Posts, Likes, and Comments are all represented as vertices and edges in the graph. As such, the graph contains billions of vertices and trillions of edges, and it consumes many hundreds of petabytes of storage space. The information presented to Facebook users is primarily the result of dynamically generated queries on the Social Graph… The scale of both the graph and the volume of queries makes it necessary to use a distributed system design for implementing the systems supporting the Social Graph. Desiging and implementing such a system so that it operates efficiently is non-trivial…
A central problem is assigning objects to components. Two instances of this problem are described in the paper: assigning HTTP requests to compute servers, and assigning data records to storage systems. With HTTP request routing, the assignment of HTTP requests to compute servers affects the cache hit rate, as a cached data record may be consumed by several queries. For the assignment of data records, it turns out that many queries result in the fetching of multiple data records. The latency of such a multi-get query (across multiple storage subsystems) is determined by the slowest request. If the fanout (number of storage systems that need to be contacted) can be reduced, this reduces the probability of encountering an unexpectedly slow query, and thus the overall query latency. As we saw in the introduction to this piece, the impact can be dramatic.
The Social Hashing process has two stages. In the first stage objects are assigned to groups. Groups are conceptual entities that represent clusters of objects. There are many more groups than there are components to assign them too (this helps with finer-grained load balancing and migration across a cluster). In the second stage groups are assigned to components (e.g. HTTP request groups to compute servers, or data record groups to storage subsystems).
The first stage is a static assignment based on optimising a given scenario-dependent objective function. The second stage is a dynamic assignment which can rapidly and dynamically respond to changes in the system and workload. Thus the assignment of objects to groups changes relatively slowly (e.g. daily), and the assignment of groups to components changes much more frequently.
A key attribute of our framework is the decoupling of optimization in the static assignment step, and dynamic adaptation in the dynamic assignment step. Our solutions to the assignment problem rely on being able to beneficially group together relatively small, cohesive sets of objects in the social graph. In the optimizations performed by the static assignment step, we use graph partitioning to extract these sets from the Social Graph or from prior access patterns.
Any given assignment must balance a number of criteria: minimal average response times; load-balanced components; stability of assignment (avoiding too frequent changes); and fast-lookup of the mapping itself. The problem is made more challenging since co-locating similar objects usually results in higher load imbalances, hardware is heterogeneous, and workload characteristics change over time. The static level assignment of objects to groups is an optimization step, in which a group is treated as a virtual component. The dynamic assignment of groups to components provides for adaptation at runtime. Since all objects in a group are guaranteed to be assigned to the same component, dynamic reassignment of groups to components does not negate the optimisation step.
Step 1 – the social hash static assignment
The static assignment partitioning solution is built on top of Apache Giraph. Assuming that we start with a balanced assignment of objects to groups (e.g. by random assignment, or by using the results of a previous iteration), the algorithm uses the following partitioning heuristic:
- For each vertex, find the group g that gives the optimal assignment for that vertex to minimize the objective function, assuming all other assignments remain the same. (This step can proceed in parallel for each vertex).
- Using a swapping algorithm, reassign as many vertices as possible to their optimum group, under the constraint that group sizes remain unchanged in each iteration. Swapping may also proceed in parallel if properly coordinated.
For the HTTP request routing case, the graph (of users and the friend links between them) is partitioned using an edge-cut optimization criterion since friends and socially similar users tend to consume the same data, and are therefore likely to reuse each other’s cached data.
The above procedure manages to produce high quality results for the graphs underlying Facebook operations in a fast and scalable manner. Within a day, a small (!) cluster of a few hundred machines is able to partition the friendship graph of over 1.5B+ Facebook users into 21,000 balanced groups such that each user shares her group with at least 50% of her friends. And the same cluster is able to update the assignment starting from the previous assignment within a few hours, easily allowing a weekly (or even daily) update schedule. Finally, it is worth pointing out that the procedure is able to partition the graph into tens of thousands of groups, and it is amenable to maintaining stability, since each iteration begins with the previous assignment and it is easy to limit the movement of objects across groups.
For the storage subsystem use case, a bipartite graph is created from logs of queries. Queries and the data records accessed by are represented by two types of vertices, and these are edge-connected if a query accesses the data record. The objective function for partitioning is to minimize the average number of groups each query is connected to.
Step 2 – dynamic assignment
Dynamic assignment aims to keep component loads well balanced despite changes in access patterns and infrastructure. The specific load balancing strategy used with the Social Hash framework varies from application to application. The authors give some criteria which help to guide selection of an appropriate load balancing strategy:
- If prediction accuracy for future loads is low, then this favours a high (e.g. 1,000:1 or more) group to component ratio with random assignment.
- A system that must balance across multiple dimensions (e.g. CPU, storage, qps etc.) also favours random assignment with high group:component rations
- The higher the overhead of moving a group from one component to another, the greater the load imbalance threshold should be for triggering a move.
- Remember previous assignments, or using techniques similar to consistent hashing may be useful if a group can benefit from residual state that may still be present.
For HTTP request routing, Facebook simply use a large number of groups (21,000) and assign them to clusters (a few 10’s) randomly using a consistent hash scheme.
Putting it all together
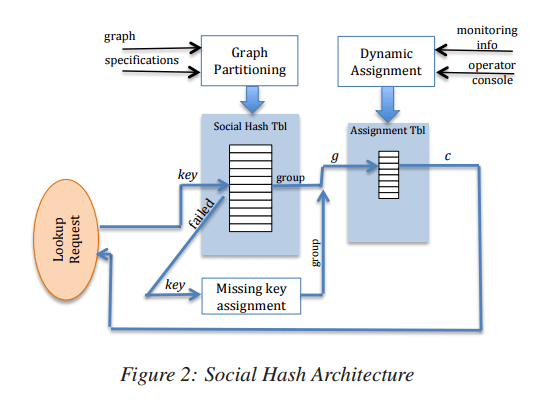
The static partitioning algorithm generates a hash table of (key, group) pairs indexed by key. This is called the Social Hash Table. The dynamic assignment generates a hash table of (group, component) pairs called the Assignment Table.
When a client wishes to look up which component an object has been assigned to, it will do so in two steps: first the object key is used to index into the Social Hash Table to obtain the target group, g; second, g is used to index into the Assignment Table to obtain the component id.
Since the Social Hash Table is only constructed periodically, we might find that a given target key is not present in the table. In this case the object is assigned to a group on the fly.
For HTTP request routing the first lookup would require large Social Hash Table to be available for lookups at every PoP. To work around the complexities of this, a cookie is used to remember the user assigned group. Requests without the cookie are routed to a random front-end cluster, where a cookie will be added for future requests. The cookie is periodically (at least once an hour) updated with the latest value from the Social Hash Table. The second lookup is computed on the fly using consistent hashing and a fairly small map between clusters and weights, which is easy to hold in PoP memory.
Operational observations
The combination of new users being added to the system and changes to the friendship graph causes edge locality to degrade over time. We measured the decrease of edge locality from an initial, random assignment of users to one of 21,000 groups over the course of four weeks. We observed a nearly linear 0.1% decrease in edge locality per week. While small, we decided to update the routing assignment once a week so as to minimize a noticeable decrease in quality.
Each weekly update resulted in about 1.5% of users switching groups. Edge locality has stayed steady at around 50% – half the friendships of a given user are within the same group. The static assignment gives good balancing, with the largest group containing at most 0.8% more users than the average group.
The impact on cache miss rate and load (CPU idle rate) after moving to Social Hashing is captured in the following charts:
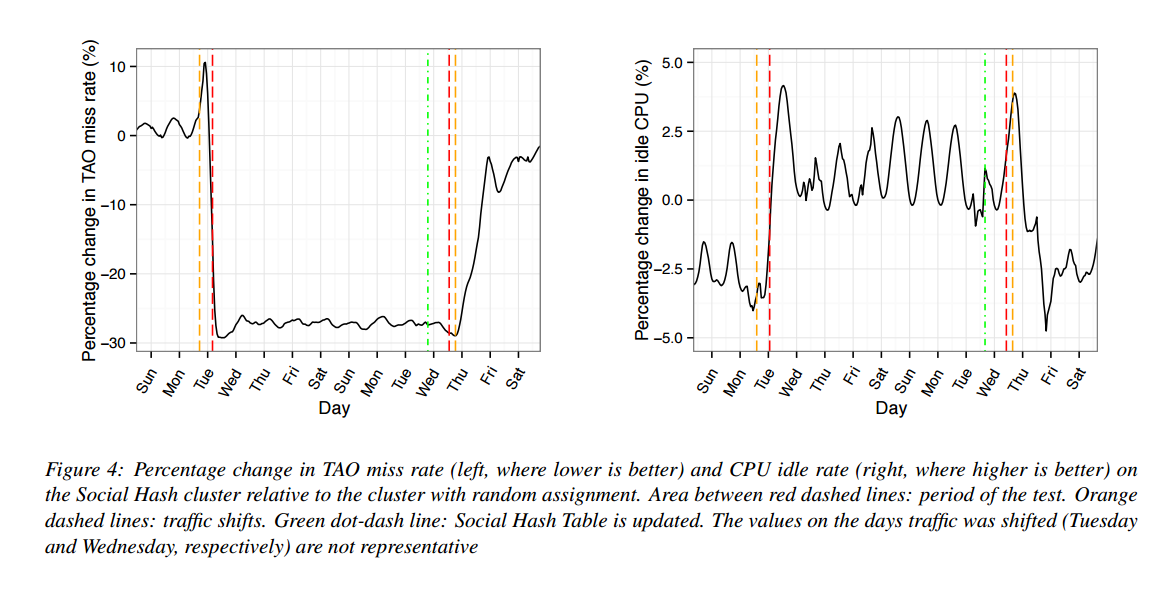
Cache misses drop by over 25%, and the idle time increases by up to 3%. The working set size (total size of all objects accessed by a TAO instance on a front-end cluster at least once during a day) dropped by as much as 8.3%.
For data record retrieval, queries before the introduction of Social Hashing needed to access 38.8 storage subsystems on average. After the introduction, this reduced to 9.9 storage subsystems on average, giving a 2.1x average latency reduction.
After we deployed storage sharding optimized with Social Hash to one of the graph databases at Facebook, containing thousands of storage servers, we found that measured latencies of queries decreased by over 50% on average, and CPU utilization also decreased by over 50%.
For data records, static assignments only needed to be updated every few months, and even dynamic assignment updates were not necessary more than once a week on average.

2 thoughts on “SocialHash: An assignment framework for optimizing distributed systems operations on social networks”
Comments are closed.