Taiji: managing global user traffic for large-scale internet services at the edge Xu et al., SOSP’19
It’s another networking paper to close out the week (and our coverage of SOSP’19), but whereas Snap looked at traffic routing within the datacenter, Taiji is concerned with routing traffic from the edge to a datacenter. It’s been in production deployment at Facebook for the past four years.
The problem: mapping user requests to datacenters
When a user makes a request to www.facebook.com, DNS will route the request to one of dozens of globally deployed edge nodes. Within the edge node, a load balancer (the Edge LB) is responsible for routing requests through to frontend machines in datacenters. The question Taiji addresses is a simple one on the surface: what datacenter should a given request be routed to?
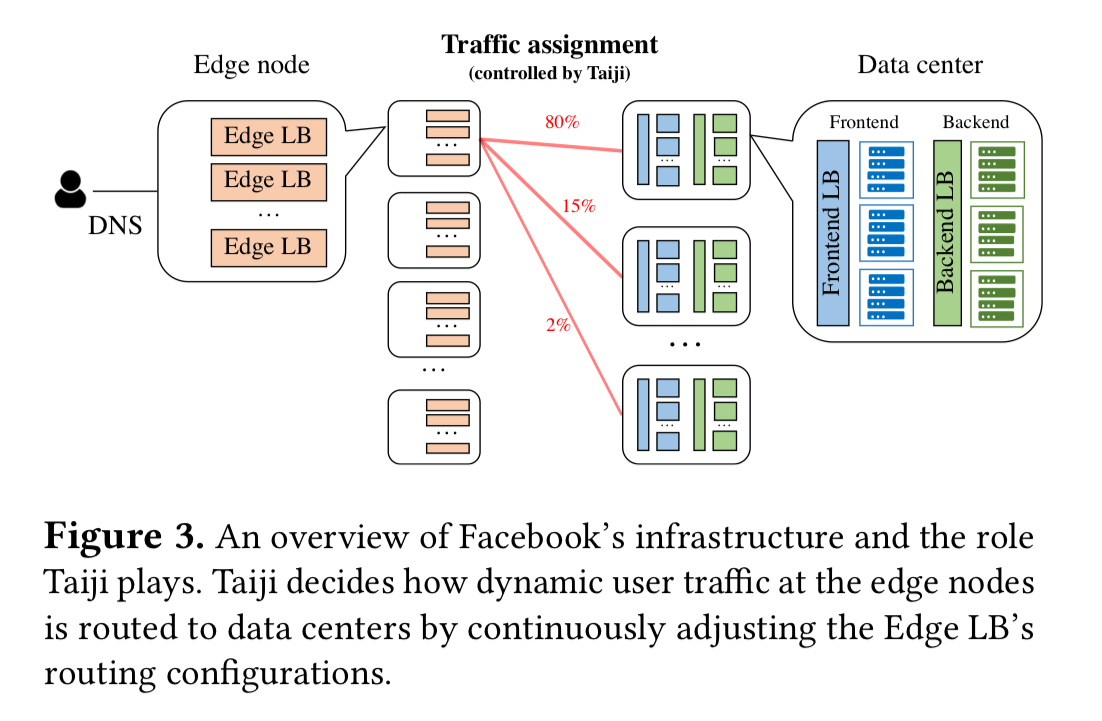
There’s one thing that Taiji doesn’t have to worry about: backbone capacity between the edge nodes and datacenters— this is provisioned in abundance such that it is not a consideration in balancing decisions. However, there are plenty of other things going on that make the decision challenging:
- Some user requests are sticky (i.e., they have associated session state) and always need to be routed to the same location once a session has been established
- Global user traffic patterns are dynamic and highly heterogenous, a simple static assignment of edge-to-datacenter mappings (which Facebook used in production prior to Taiji) can hence lead to some backends being overloaded, while others remain under-utilised.
- The ability of a datacenter to handle traffic changes over time as capacity is added or removed, and hardware upgraded
- The routing needs to be able to tolerate failures without making the situation worse
Sharing is caring caching.
Taiji’s routing table is a materialized representation of how user traffic at various edge nodes ought to be distributed over available data centers to balance data center utilization and minimize latency. The strawman approach is to leverage consistent hashing. Instead, we propose that popular Internet services such as Facebook, Instagram, Twitter, and YouTube leverage their shared communities of users. Our insight is that sub-groups of users that follow/friend/subscribe each other are likely interested in similar content and products, which can allow us to serve their requests while also improving infrastructure utilization.
To state it simply: if you share some content with your friends, it increases the likelihood that they will see and click on that content. Therefore friend groups all end up accessing similar content, a fact that can be exploited in the backend to improve cache utilisation. We looked at this before when we studied Facebook’s Social Hashing algorithm. Taiji builds on top of Social Hash to provide connection-aware routing.
The deployment of connection-aware routing reduced query-load on backend databases by 17%, compared to a baseline implementation using Social Hash alone. Social Hash on its own achieves 55% connection locality, with connection-aware routing on top, this goes up to 75%.
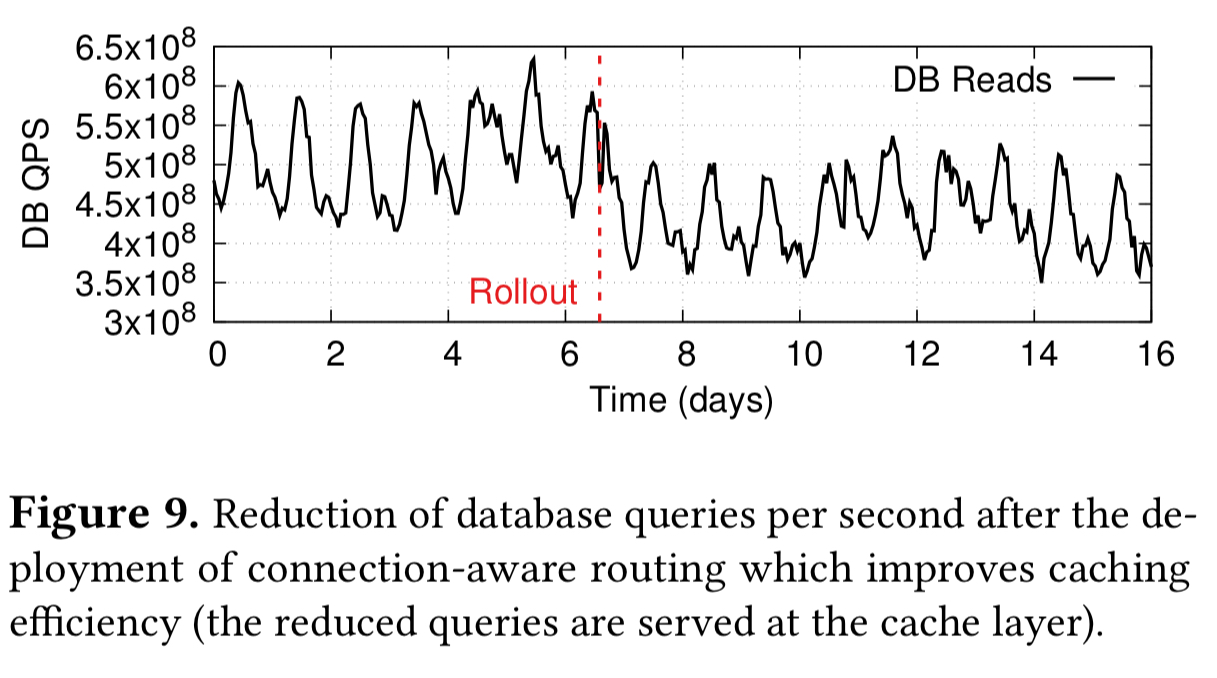
This outcome at our deployment scale means a reduction of our infrastructure footprint by more than one data center.
The social graph partitioning is done offline on a weekly basis to uncover and track changes in friend groups. A binary tree of height 


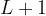

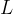
With users statically assigned to buckets during this weekly partitioning exercise, it remains to assign buckets of users to datacenters, which is done in an online fashion via a Stable Segment Assignment algorithm.
Stable Segment Assignment strives to preserve bucket locality by assigning a whole level of buckets (called a segment) in the community hierarchy to the same data center; only a minimal number of segments need to be split. For stability, the same segments should be assigned to the same data centers as much as possible.
See algorithm 1 in section 3.2.1 of the paper for the details.
Routing end-to-end
Taiji consists of two main components: a Runtime component which is responsible for deciding the fraction of traffic each edge node will send to available data centers, acting in accordance with supplied policies, and a Traffic Pipeline component which employs the connection-aware routing groups to create fine-grained routing entries at each edge load balancer.
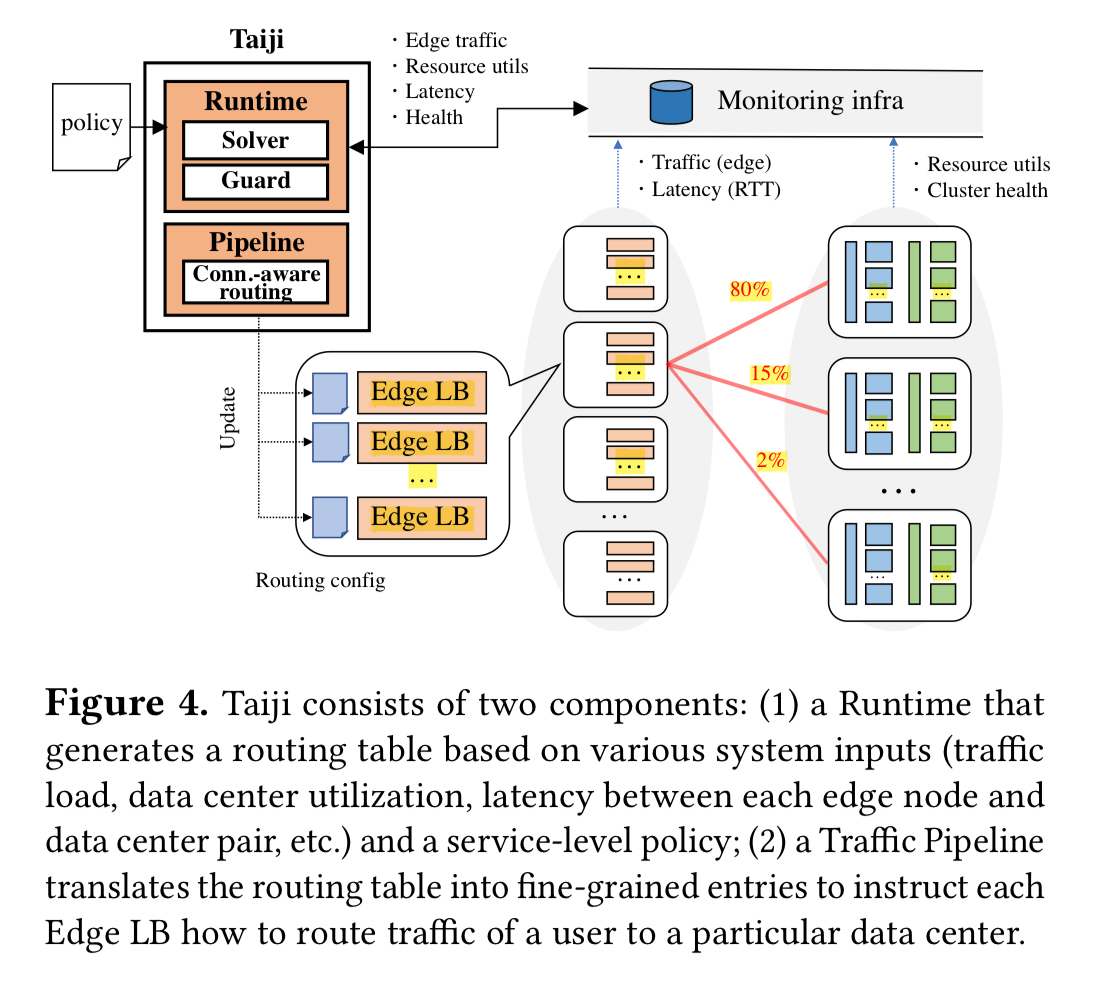
The runtime component takes as input data on the operational state of the infrastructure, and measurement data such as edge traffic volumes and edge-to-datacenter latency. Traffic load is measured using requests per second for stateless traffic, and as the number of user sessions for sticky traffic. The runtime is also configured with service policies that specify constraints and objectives for the routing assignments. For example, balance utilisation across all data centers, or optimise for network latency.
All of these inputs, constraints, and objectives are passed to an assignment solver.
Our solver employs a local search algorithm using the “best single move” strategy. It considers all single moves: swapping one unit of traffic between data centers, identifying the best one to apply, and iterating until no better results can be achieved. Our solver takes advantage of symmetry to achieve minimal recalculation.
The solver generates a solution in 2.81 seconds on average (and in 43.97 seconds at 4x the current scale). The routing table is updated once every 5 minutes. The output from the solver is a collection of tuples of the form:
{ edge: { datacenter: fraction }}
The traffic pipeline takes the fractional assignments output by the runtime, and generates specific routing entries for each edge load balancer, of the form:
{ edge: { datacenter: { bucket }}}
Generating the routing entries and disseminating them takes about a minute.
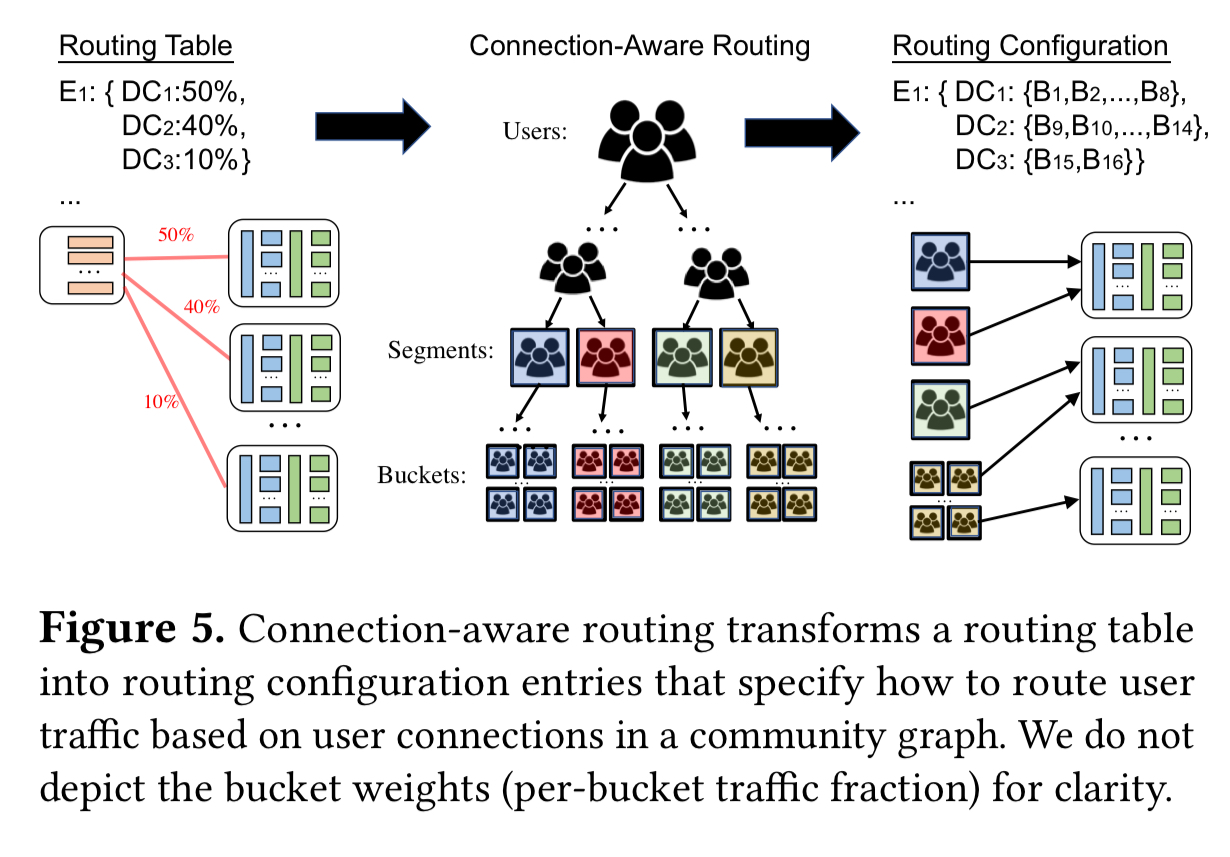
Fine-grained user to bucket mappings are stored in the datacenters (there are too many users to store the full table in all the edge locations!). Thus edge load-balancers route at bucket granularity. When an initial request arrives with no known bucket id the edge LB routes the request to a nearby datacenter, where the frontend controller looks up the bucket id and writes it in a cookie for future requests.
Keeping things under control
Taiji employs several safety guards to limit the volume of traffic change permitted in each update of the routing table.
The onloading safety guard bounds how much the utilisation of a data center can increase during a (five minute) epoch. In production this is currently set at 0.04 (I’m assuming this is 4%, we’re not given units…). This safety guard ensures larger changes happen in stages, giving caching systems etc. a chance to warm up.
A minimum shift limit prevents unnecessary oscillations by rejecting changes below 1% (which empirically were found to provide little value). Taiji also employs a dampening factor whereby instead of trying to make an exact traffic shift to the target value —which can lead to overshooting—, Taiji aims for 80% of the target.
You can see the impact of these pacing controls in the following charts, which show a datacenter-level drain and restore operation. Notice how much gentler the actual traffic changes (gray bars) are compared to the plan (orange bars). Backend processing latency stays fairly constant during this operation.
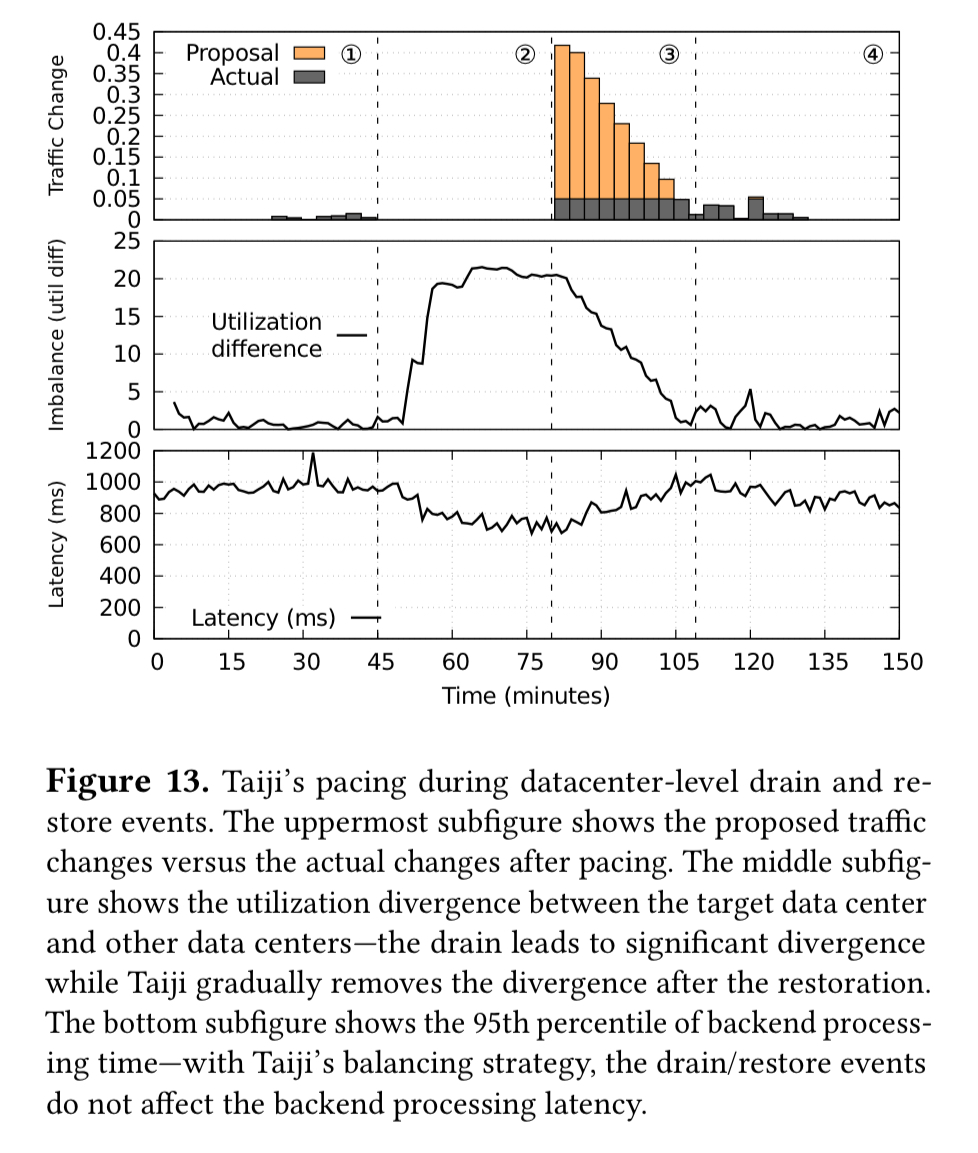
There are many more charts showing Taiji in action in section 5 of the paper.
Taiji has been used in production at Facebook for more than four years, and is an important infrastructure service that enables the global deployment of several large-scale user-facing product services.

One thought on “Taiji: managing global user traffic for large-scale Internet services at the edge”
Comments are closed.