Snap: a microkernel approach to host networking Marty et al., SOSP’19
This paper describes the networking stack, Snap, that has been running in production at Google for the last three years+. It’s been clear for a while that software designed explicitly for the data center environment will increasingly want/need to make different design trade-offs to e.g. general-purpose systems software that you might install on your own machines. But wow, I didn’t think we’d be at the point yet where we’d be abandoning TCP/IP! You need a lot of software engineers and the willingness to rewrite a lot of software to entertain that idea. Enter Google!
I’m jumping ahead a bit here, but the component of Snap which provides the transport and communications stack is called Pony Express. Here are the bombshell paragraphs:
Our datacenter applications seek ever more CPU-efficient and lower-latency communication, which Pony Express delivers. It implements reliability, congestion control, optional ordering, flow control, and execution of remote data access operations. Rather than reimplement TCP/IP or refactor an existing transport, we started Pony Express from scratch to innovate on more efficient interfaces, architecture, and protocol. (Emphasis mine).
and later on “we are seeking to grow usage of Snap, particularly with Pony Express as a general-purpose TCP/IP replacement“.
The forces shaping Snap’s design
The desire for CPU efficiency and lower latencies is easy to understand. But the thing that really stands out to me as a key driving force in determining Snap’s design is the desire to be able to evolve Snap rapidly – i.e. being able to do regular releases of software upgrades to deploy new network functionality and performance optimisations.
With the previous kernel space solution, networking enhancements took longer to develop, and a really long time to deploy: “in practice, a change to the kernel-based stack takes 1-2 months to deploy whereas a new Snap release gets deployed to our fleet on a weekly basis.” That’s 4-8x the speed of evolution and feedback cycles.
To get that release speed, Snap needs to be a user space solution. But if rolling out a new release of Snap required all applications using it to also roll out a release, that would be even more painful. So Snap needs to be outside of both the kernel and any application using it. This rules out a ‘library’ approach.
Where Snap fits into the stack
What’s left is a design whereby Snap runs as userspace ‘microkernel’, which applications communicate with using shared memory reads and writes. This combines all the benefits of centralised management without the tight coupling and slow release cycles. It reminds me of ZeroMQ.
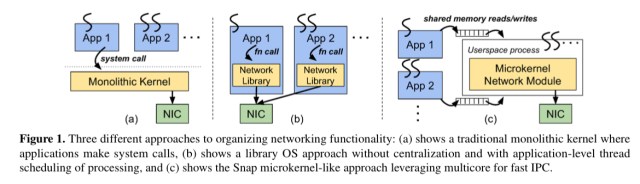
Snap’s architecture is a composition of recent ideas in user-space networking, in-service upgrades, centralized resource accounting, programmable packet processing, kernel-bypass, RDMA functionality, and optimized co-design of transport, congestion control and routing.
Snap’s control plane is orchestrated via RPCs. Data plane operations are handled by pluggable engines (Pony Express is an engine).
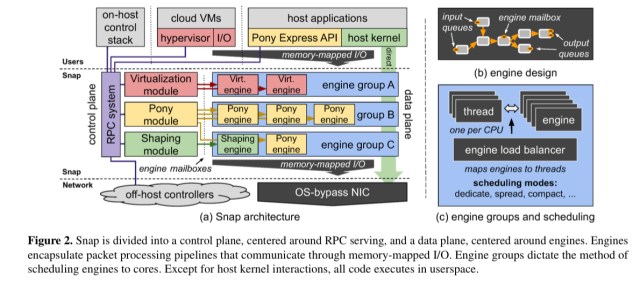
Upgrading in a Snap
When it comes time to rollout a new release of Snap, the upgrade takes place in two phases. A brownout phase performs a preparatory background transfer of all the key state to a memory region shared with the new version. Then a short blackout period (200ms or less) cuts over to the new version. Upgrades are performed incrementally, one engine at a time. Upgrades are also rolled out progressively across the cluster of course.
…with a gradual upgrade process across a cluster, we have found that our existing applications do not notice hundred millisecond blips in communication that occur once per week.
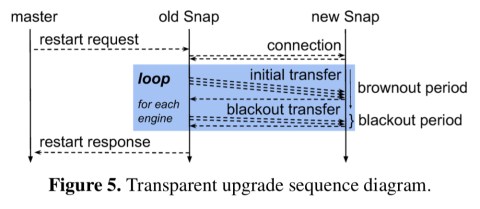
During a rollout there will be periods when multiple release versions can exist in a fleet. Thus new releases have to backwards compatible with older protocol versions. An out-of-band mechanism (tcp socket) is used to advertise the available wire protocol versions when connecting to a remote machine, and the lowest common denominator will be used. Once the whole fleet has turned over, the code for the now unused version(s) can be removed.
The little engine that could
Engines are stateful, single-threaded tasks that are scheduled and run by a Snap engine scheduling runtime.
There are three broad categories of scheduling modes for engines:
- Dedicated cores: an engine is pinned to a dedicated hyperthread on which no other work can run. When under/over provisioning is not a concern, this can deliver very low latency.
- Spreading: engines are assigned to threads that schedule only when active, and block on interrupt notification when idle. This mode scales CPU consumption in proportion to load, and provides the best tail latency properties.
- Compacting: this mode collapses work onto as few cores as possible, relying on periodic polling of engine queuing delays to detect load imbalance.
The CPU scheduling modes also provide options to mitigate Spectre-class vulnerabilities by cleanly separating cores running engines for certain applications from those running engines for different applications.
All aboard the Pony Express
Pony Express, as we saw earlier, is a ground-up implementation of networking primitives. It offers asynchronous operation-level commands and completions, with both two-sided and one-sided operations (of which RDMA is an example). One-sided operations do not involve any remote application thread interaction.
Client applications interact with Pony Express over a Unix domain socket using the Pony Express client library. Command and completion queues are managed in shared memory. Application threads can either spin-poll the completion queue to receive results, or can request a thread notification when a completion is written.
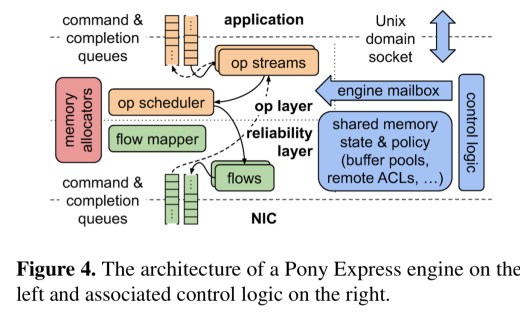
The upper layer of Pony Express implements state machines for application-level operations, and the lower layer implements reliability and congestion control.
The congestion control algorithm we deploy with Pony Express is a variant of Timely, and runs on dedicated fabric QoS classes. The ability to rapidly deploy new versions of Pony Express significantly aided development and tuning of congestion control.
One-sided operations seem to be the one place where applications and Snap are coupled – if an application needs a new one-sided operation it must be pre-defined and pre-installed as part of a Pony Express release.
Performance numbers
Compared to a baseline setup using the Neper utility, Snap/Pony delivers 38Gpbp using 1.05 cores, vs 22Gbps using 1.2 cores for the baseline.
It has low latency, stable tail latency, and high cpu efficiency as shown in the charts below.
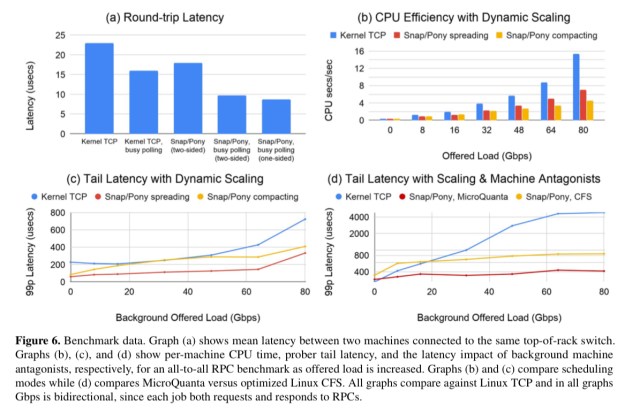
Production workloads have achieved up to 5 million remote memory accesses per second using a single dedicate Snap/Pony core – twice the production performance of the hardware RDMA implementation it replaced (to prevent thrashing, the hardware implementation had caps in place).
Our evaluation demonstrates up to 3x improvement in Gbps/core efficiency, sub-10-microsecond latency, dynamic scaling capability, millions of one-sided operations per second, and CPU scheduling with a customizable emphasis between efficiency and latency.

Is this architecture vulnerable to SPECTRE/MELTDOWN type attacks from one app to the other?
There’s an interesting discussion in the full paper about the way the Engine scheduling policies allow for full separation of engine traffic when desired by pinning an engine to a *dedicated* core. They explicitly reference protection against such side-channel attacks as a benefit here.
With TAS (in EuroSys’2019, https://dl.acm.org/citation.cfm?id=3303985) we ended up building a TCP stack with a similar architecture. The stack also runs as a privileged user space service on dedicated cores, and adapts the number of cores to workload demand. Even some of the implementation aspects are similar, using a Unix sockets for control operation and then switching over to asynchronous shared memory queues. After publication we also added support to integrate with the Linux network stack to make the stack opt-in for applications.
For TAS the main motivation was performance, we were looking to get performance/CPU efficiency close to kernel bypass without losing any of the traditional OS protection/isolation guarantees, and while supporting multiple applications without just relying on busy polling. Another difference, was that we were looking to preserve backward compatiblity with TCP sockets applications. RDMA support (likely RoCE) is on our TODO list, and Snap confirms that we should be able to get similar performance benefits there too.
Encouraging to see that Google seems to agree with the motivation behind this architecture. And the addition of transparent upgrades seems like a great opportunity that we haven’t considered yet. My guess is that this would be a bit trickier to pull off with TCP, but probably doable.
Unlike Snap, TAS is available open source: https://github.com/tcp-acceleration-service/tas