HCloud: Resource-efficient provisioning in shared cloud systems – Delimitrou & Kozyrakis, ASPLOS ’16
Do you use the public cloud? If so, I’m pretty confident you’re going to find today’s paper really interesting. Delimitrou & Kozyrakis study the provisioning strategies that provide the best balance between performance and cost. The sweet spot it turns out, is a combination of reserved instances and on-demand provisioning with a placement policy that can improve performance by 2.1x compared to using only on-demand instances, and that can reduce cost by 46% compared to fully-reserved systems. Key to these results is an understanding of how sensitive different applications are to interference (noisy neighbours). One nice tactic that jumped out at me is to provision a large instance, increasing the chances that you’ll get a whole machine or a large portion thereof to yourself (hence reducing external interference). You can then suballocate the machine to your own workloads using containers, leading to much more predictable performance.
There’s so much great information in this paper that I can only share a small subset of it. If these topics interest you, I encourage you to go on and read the full paper.
The types of instances you choose makes a big difference
The authors examine three different workload types with static, low, and high variability in resource requirements. Each is a mix of batch (Hadoop and Spark) and latency-critical (memcached) workloads. The static scenario uses 854 cores, the low variability scenario needs 605 cores on average with peak demand of 900 cores, and the high variability scenario needs between 210 and 1266 cores.
The study looks at provisioning resources for these workloads across a mix of reserved and on-demand resources (spot instances are ignored in this work since they do not provide any availability guarantees).
Reserved resources are dedicated for long periods of time (typically 1-3 years) and offer consistent service, but come at a significant upfront cost. In the other extreme are on-demand resources, which are progressively obtained as they become necessary. The user pays only for resources used at each point, however the per hour cost is 2-3x higher compared to reserved resources, and acquiring new instances induces instantiation overheads.
The major challenge with reserved resources of course is figuring out how many you need – overprovisioning is expensive! Dedicated machines provide more predictable performance but at a high cost, smaller instances are prone to external interference and hence unpredictable quality of service. You can see this playing out in the following plots of performance unpredictability against instance size for batch jobs (where the performance measure is execution time) and for latency sensitive jobs (performance measure is latency):
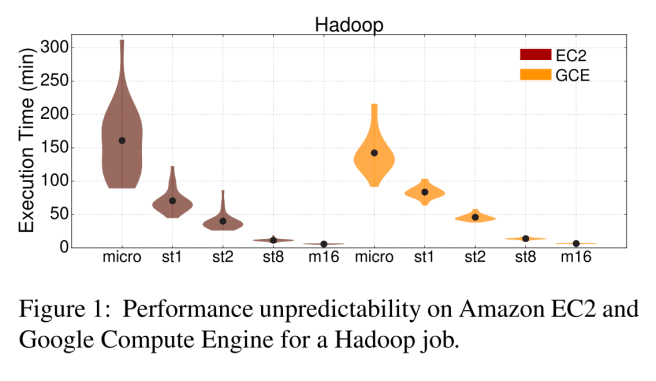

For the batch jobs…
It becomes clear that especially for instances with less than 8 vCPUs unpredictability is significant, while for the micro instances in EC2 several jobs fail to complete due to the internal EC2 scheduler terminating the VM. For the larger instances (m16), performance is more predictable, primarily due to the fact that these instances typically occupy a large fraction of the server, hence they have a much lower probability of suffering from interference from co-scheduled workloads, excluding potential network inter- ference. Between the two cloud providers, EC2 achieves higher average performance than GCE, but exhibits worse tail performance (higher unpredictability).
While for the latency sensitive jobs GCE achieves better average and tail performance compared to EC2.
Our study reveals that while reserved resources are superior with respect to performance (2.2x on average over on-demand), they require a long-term commitment, and are therefore suitable for use cases over extended periods of time. Fully on-demand resources, on the other hand, are more cost-efficient for short-term use cases (2.5x on average), but are prone to performance unpredictability, because of instantiation overheads and external interference.
For the three workload mixes (static, low-variability, and high-variability), the authors study three different baseline provisioning strategies: (a) using statically reserved resources only (SR), (b) using on-demand large instances of 16 vCPUs partitioned using Linux containers (OdF), and (c) using on-demand mixed instances, 1-8 vCPUs (OdM).
Here’s how the batch applications fared:

(click on figures for a larger view)
And here’s what happened to the latency-sensitive applications:
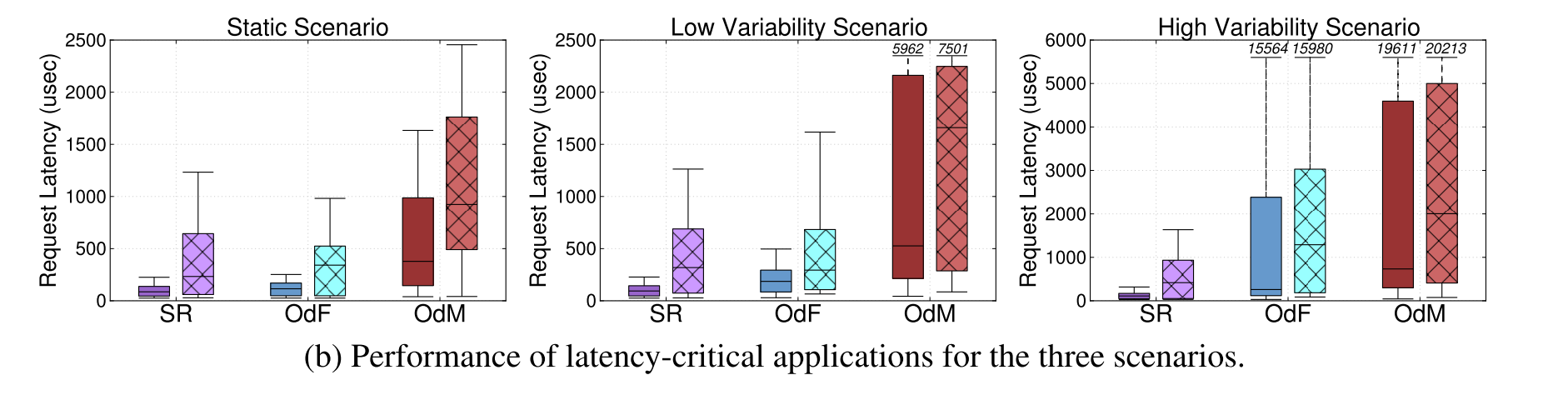
The boundaries in the box plots are the 25th and 75th percentiles, with whiskers are the 5th and 95th percentile, and the horizontal line is the mean. Notice that each pairing has two box plots – one with hatching and one without. The non-hatched boxes represent the performance obtained when using a cluster manager called Quasar which profiles jobs to estimate their resource preferences and interference sensitivity. I covered the Quasar paper very early on in the life of The Morning Paper, before it was a blog and existed only on twitter. Unfortunately that means there is no written write-up for me to refer you back to. It’s a great paper so well worth reading. Here’s the short version:
The recently-proposed Quasar cluster manager provides a methodology to quickly determine the resource preferences of new, unknown jobs. When a job is submitted, it is first profiled on two instance types, while injecting interference in two shared resources, e.g., last level cache and network bandwidth. This signal is used by a set of classification techniques which find similarities between the new and previously-scheduled jobs with respect to instance type preferences and sensitivity to interference.
As you can see in the results, intelligent placement using Quasar makes a big difference (2.4x for SR)! Jobs with a high ‘Q’ number are resource demanding, while jobs with low ‘Q’ numbers can tolerate some resource interference.
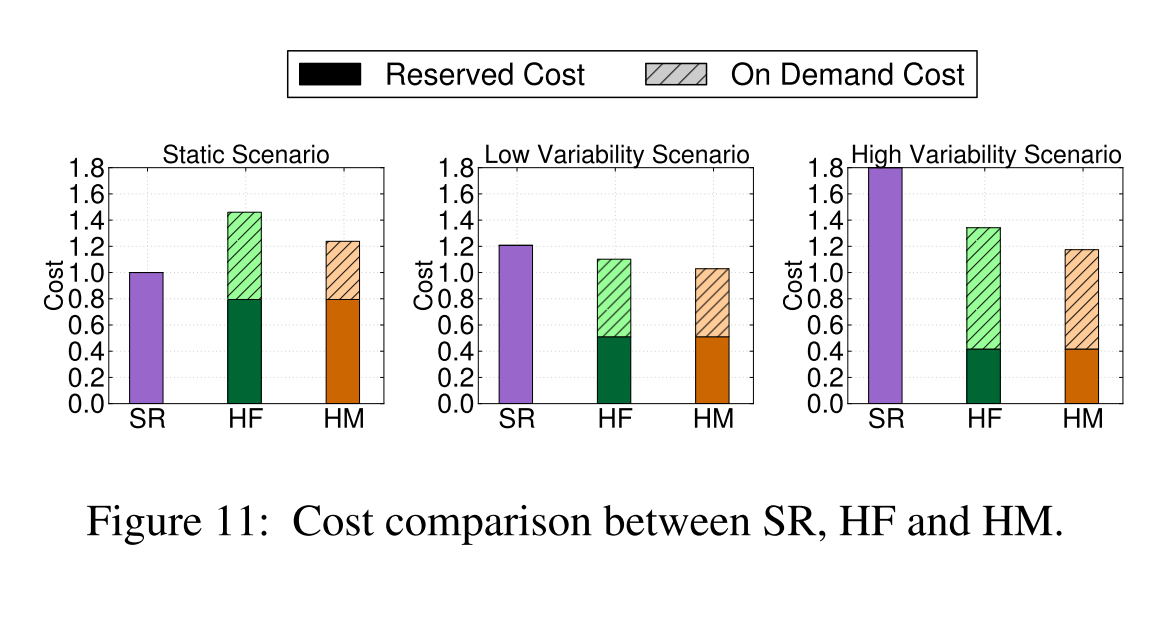
SR has the best performance for all three scenarios, and also appears to have the lowest cost. However, that doesn’t tell the full story:
Although strategy SR appears to have the lowest cost for a 2 hour run (2-3x lower than on-demand), it requires at least a 1-year commitment with all charges happening in advance. Therefore, unless a user plans to leverage the cluster for long periods of time, on-demand resources are more efficient. Moreover, SR is not cost-effective in the presence of high workload variability, since it results in significant over-provisioning. Between the two on-demand strategies, OdM incurs lower cost, since it uses smaller instances, while OdF only uses the largest instances available.
What we seem to need, is some kind of hybrid that uses reserved instances at the core, and takes advantaged of on-demand instances to cope with variability…
Hybrid provisioning with HCloud
The hybrid strategy HF combines reserved instances with the use of only large on-demand instances. HM combines reserved instances with mixed-size on-demand instances. In both cases the number of reserved instances was configured to accommodate the minimum steady-state load to avoid over-provisioning.
The results are shown below. The hatched box represents a baseline placement policy in which applications are mapped randomly between reserved and on-demand resources. The solid box shows the results achieved with a dynamic placement policy that takes into account the resource sensitivity of the jobs (and as you can see, performs much better).
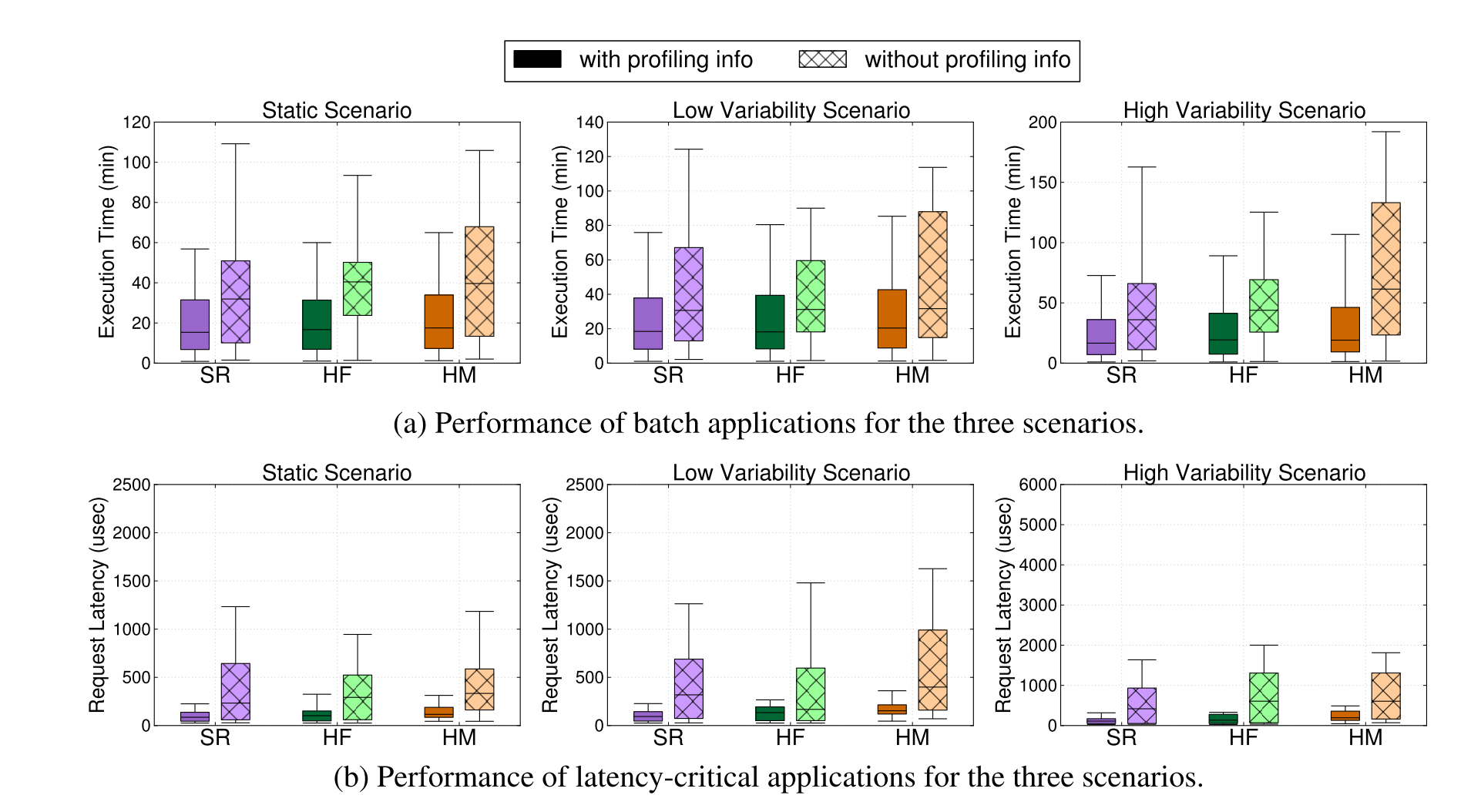
The dynamic policy uses Quasar profiling to determine interference sensitivity, resulting in a Q-number for the job to be placed.
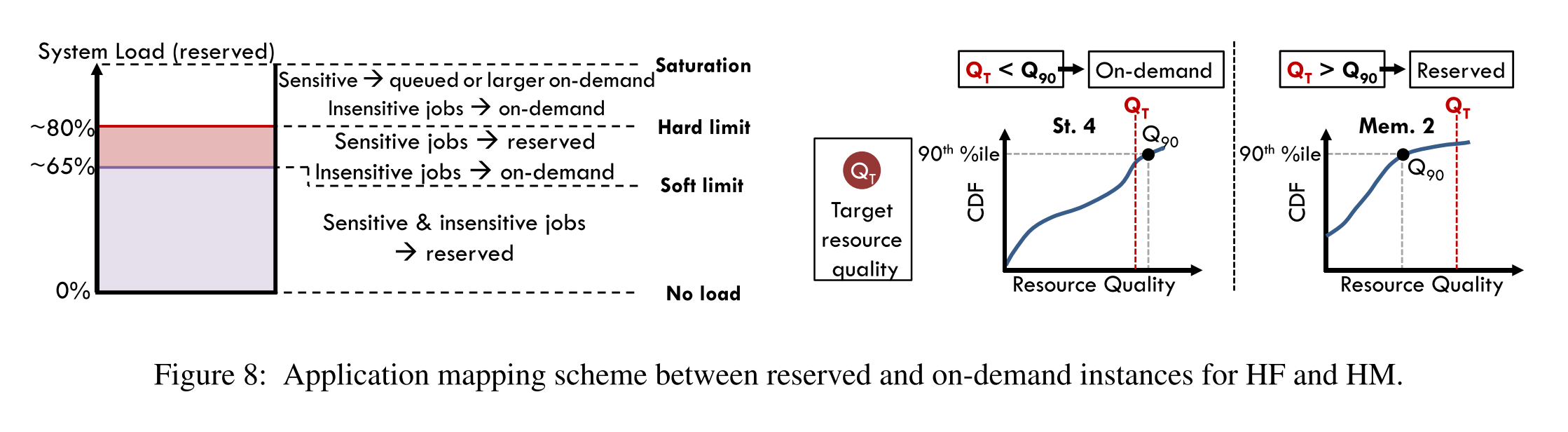
We set two utilization limits for reserved resources. First, a soft limit (experimentally set at 60-65% utilization), below which all incoming jobs are allocated reserved resources. Once utilization exceeds this limit, the policy differentiates between jobs that are sensitive to performance unpredictability and insensitive ones. The differentiation is done based on the resource quality Q a job needs to satisfy its QoS constraints and the knowledge on the quality of previously-obtained on-demand instances. Once we determine the instance size a job needs (number of cores, memory and storage), we compare the 90th percentile of quality of that instance type (monitored over time) against the target quality (QT ) the job needs. If Q90 > QT the job is scheduled on the on-demand instance, otherwise it is scheduled on the reserved instances… Second a hard limit for utilization, when jobs need to be queued before reserved resources become available. At this point any jobs for which on-demand resources are satisfactory are scheduled in on-demand instances… The soft utilization limit is adjusted based on the rate at which jobs get queued.
Using this dynamic profiling placement policy, HF and HM come within 8% of the performance of the statically reserved system, and in most cases outperform OdF and OdM – especially for scenarios with load variability.
Here’s how the costs of the SR, HF, and HM scenarios stack-up across the three workload types:
See the full paper for a discussion of how the various strategies impact resource efficiency.
Alternative pricing models…
So far we have assumed a pricing model similar to Amazon’s AWS. This is a popular approach followed by many smaller cloud providers. Nevertheless, there are alternative approaches. GCE does not offer long-term reservations. Instead it provides sustained usage monthly discounts to encourage high utilization of on-demand resources. The higher the usage of a set of instances for a fraction of the month, the lower the per-hour price for the remainder of the month. Microsoft Azure only offers on-demand resources at the moment. Even without reserved resources, the problem of selecting the appropriate instance size and configuration, and determining how long to retain an instance remains. Figure 17 shows how cost changes for the three workload scenarios, under the Azure (on-demand only) and GCE (on-demand + usage discounts) pricing models, compared to theAWS pricing model (reserved + on-demand). We assume that the resources will be used at least for one month, so that GCE’s discounts can take effect. Cost is normalized to the cost of the static scenario under the SR strategy using the reserved & on-demand pricing model.
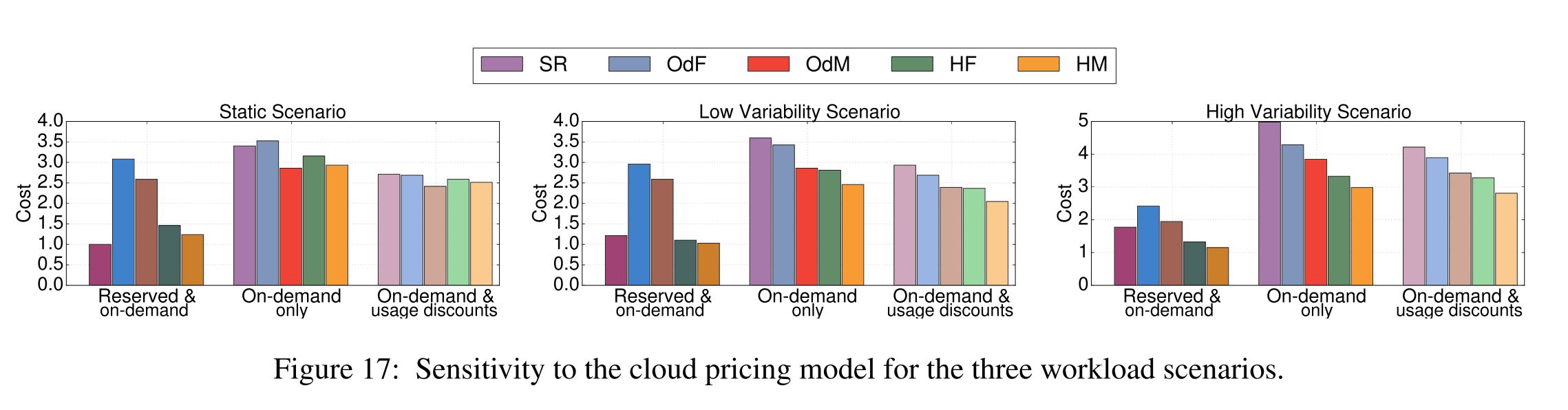
Even with the alternative pricing models using the hybrid strategies and accounting for resource preferences of new jobs significantly benefits cost. For example, for the high variability scenario, HM incurs 32% lower cost than OdF with the Windows Azure pric-ing model; similarly for the GCE model with discounts, HM achieves 30% lower cost than OdF.
In future work, the authors intend to consider how spot instances interact with the provisioning strategies investigated in this paper.

You might also be interested in a review I did of work on Spark using on-demand spot instances – to quote them;
“Flint executes applications at near the performance of on-demand servers (within 2-10%) but at a cost near that of spot servers, which is 90% less than using on-demand servers and 50-66% less than using existing managed services such as SpotFleets and Spark-EMR.”
http://www.hpcurious.com/weekly-paper-review-flint/